1.3.1 数据类型与结构
Created on Mon Jan 17 08:58:45 2022; Last updated on Fri Aug 23 14:41:45 2024 @author: Richie Bao
在解释各个组件时,通常会给出一个由几个组件构成的代码程序来演示数据的变化,可以很好的看出该组件引起数据的变化关系,非常适合于单个组件的学习和功用查询。这种方法虽然便于理解组件的功用,但是当用这种方法学习完所有的组件之后,却发现仍然不会写代码(用节点可视化编程解决设计问题:构建设计模型或分析设计关系等)。这些组件等同于在学习 Python 等文本式编程时的数据类型、结构和运算方法,但是文本式编程含有 if elif else 条件语句, for,while 等循环语句构建语句块、函数或者类处理数据来解决某一问题。用 GH 编程解决设计问题则需要选择数据处理的组件,通过特定的连接模式构建这些“语句块”;同时,GH 是用于实现设计的工具,数据内容大部分是三维(或二维)空间对象的反映,因此不含对应三维对象的纯粹数据会过于抽象;再者,通过组件的连接分析数据处理的方式,可以明了组件配合使用的方法,而不仅是单个组件的功用。因此,在解释 GH 节点可视化编程时,像开始学习 Python 等文本式语言一样,给出大量的"代码段(code snippets)"。代码段的设计上要能够体现与设计应用的结合;还要尽可能用尽量少的组件;且代码段要尽量体现组件间搭配处理数据的方法。
单个组件的演示说明程序和与设计相结合的代码段都是学习基于节点式编程 Grasshopper 参数化设计不可或缺的部分。
1.3.1.1 数据类型与输入
1)数据类型
GH 与文本式编程语言显著的不同在于,GH 主要目的是构建参数化的空间几何对象,因此 GH 的设计除了参考文本式编程语言的主要基本数据类型外,还包括空间几何对象。GH 的基本数据类型表述位于Primitive标签之下(如图1.3.1-1),包括文本式编程语言的主要基本数据类型:整形(integers,int),浮点型(float),字符型(string,str),布尔型(bool),复数(complex)等,对应到 GH 界面Params->Primitive下的Integer、Number、Text、Boolean、Complex。同时增加有Color、 Culture、 Domain、 Domain2、 Guid、 Matrix、Time、Earth Anchor Point、Unit System等。空间几何对象位于Params->Geometry下((如图1.3.1-2)),并可以进一步划分为点与向量类(Point、Vector);曲线与参考面类(Circle、Circular Arc、Curve、Line、Rectangle、Plane);面与体类(Box、Brep、Mesh、Mesh Face、SubD、Surface、Twisted Box,Extrusion,Point Cloud);尺寸标注类(Angular Dimension、Annotation Dot、Centermark、Hatch、Leader、Linear Dimension、Ordinate Dimension、Radial Dimension、Text Entity);及辅助几何类型(Block Instance、Field、Geometry、Geometry Cache、Geometry Pipeline、Group、Light、Transform、View)。

|

|
|---|---|
图 1.3.1-1 Primitive(包含表述基本数据类型) |
图 1.3.1-2 Geometry(包含表述空间几何对象) |
Primitive和Geometry面板下的组件可以归类为容器组件(Containers components),帮助在 GH 中传递数据,这包括主要基本数据类型(参数)和空间几何。容器组件只能保存特定的数据类型,且每种类型的数据通常都有一个容器组件,如在图1.3.1-3中示例了几种容器组件。容器组件的输入一般包括四种情况,其一,可以在组件上右键,例如对于组件Line和Box,可以选择Set one Line(Set multiple Lines)、Set one Box(Set multiple Boxes)后在 RH(Rhino)空间中绘制;其二,类似第一种情况,但是可以从 RH 空间中拾取几何体,例如对于Point,右键选择后,在 RH 空间的命令行上(Command)选取相关选项(如图1.3.1-3中Image Sample中显示的命令行),可以拾取 RH 空间创建的对象;其三,可以直接连入 GH 空间下对应的几何组件,例如组件Line连接到组件Line;其四,GH 提供了读取外部文件路径的组件File Path,可以加载本地磁盘中的数据文件,例如读取了包含经纬度和高程的数据文件elevation.txt,并配合组件Read File读取数据。示例中有意识地向容器组件中传入不相容地几何类型,例如将Box和Line几何对象通过Merge合并后同时再次输入到Box和Line组件上,可以发现,Box组件在设计时可以将直线段转化为其外接矩形,而Line组件则会对输入地非直线型数据提示错误。

图 1.3.1-3 容器组件示例
为了实现在 GH 中烘培(bake)几何对象时能够自定义属性,并且在 GH 中调用 RH 中的材质(material),在 GH 1.0(RH 8 WIP)版本开始增加了 RH 中的图层(Layers)、线型(Linetypes)、填充(Hatches)、材质(Materials)、字体(Fonts)等数据类型,并不断丰富,这些组件主要位于GH 界面的Rhino面板下。因此也对应增加了容器组件,位于Params->Rhino下,部分示例如图 1.3.1-4。图中左上角为Params->Rhino面板,底部的 Layer图层为 RH 空间中可以定义的属性,这包括Name(名称)、Is Active (ie. Current)(是否为当前图层)、Visible/Hidden(可见/隐藏)、Locked/Unlocked(锁定/解锁)、Display Color(显示颜色)、Material(材质)、Linetype(线型)、Print Color(打印颜色)、Print Width(打印宽度)、Section Style(截面样式)等,这些配置目前在 GH 中同样可以实现。

图 1.3.1-4 Rhino 数据类型
2)数据输入
节点可视化编程以组件的方式组织代码,因为操作模式的变化,数据输入的方式也灵活多样(图 1.3.1-5 )。在Params->Input下集合了多种输入模式的组件,可以按照输入数据类型分类,包括数值型(int, float),例如Number Slider、Control Knob、Digit Scroller、MD Slider、Value List等,每个组件提供的输入操作模式各异,拖拉、旋转、位数处滚动数值、同时获取两个值(X,Y),及可以定义公式的下拉选择项模式等;布尔型(bool)有Boolean Toggle和Button,以开关拨动和按钮的形式呈现;时间类(Time)包括Calendar和Clock,对应年月日和时间;颜色类(Color)包括Color Picker、Colour Swatch、Colour Wheel和Gradient几种类型,通过颜色拾取、选择、转盘和渐变的不同方式输入。同时Input也提供了Graph Mapper图形工具,根据选择的图形函数输出数据列表。及Image Sampler,可输入编辑图像通道信息。
数据也可以从外部读取,在Params->Input下提供了PDB(Protein Data Bank,蛋白质及核酸的三维结构,与Atom Data组件配合使用)、3DM(Rhino的三维模型)、Coordinates(.xyz格式存储的点坐标格式)、Image(图像,与Image Resource组件配合使用)、SHP(地理信息数据.shp),以及Params->Primitive->File Path和Read File组件配合使用读取文本文件。
其中需要注意地是Panel面板组件,其既可以用于输出端的数据观察,也可以用于数据的输入,及仅展示注释说明性内容。Panel输出的为字符串,但是根据输入内容和输出连接的组件,数值型数据可以自动转化,用于计算。

图 1.3.1-5 Input(包含各种不同数据输入形式组件)
3)数学运算
Maths组件面板(图1.3.1-6)提供了Domain(区间)、Matrix(矩阵)、Operators(运算符)、Polynomials(多项式)、Time(时间)、Trig(Trigonometry)(三角函数)等运算工具,及Util下的数学常数、极值、简单的数据处理和复数。节点可视化编程组件很难像文本式编程,可以在无限制的扩展内容时,又方便调用,因此在Script下提供了编程脚本,包括 Python、C# 和 VB 等编程语言,从而可以直接调用这些语言下已经存在的库,这包括大量的数学运算。目前 GH 下的 Python Script 已经更新为 Python 3,但最为关键的升级是可以根据需要自行安装 Python 扩展库,这为 GH 下无限的探索提供了可能。

图 1.3.1-6 maths 面板
1.3.1.2 数据结构与代码段练习
Python 内置的数据结构(类型)有列表(list)、元组(tuple)、字典(dictionary)、集合(set),字符串(string,str),及Numpy①扩展库下的数组(array)和Pandas②下的 DataFrame 及 Series 等。对 GH 而言(图 1.3.1-7),对应有列表(Sets->List),集合(Sets->Sets),字符串(Sets->Text)。类似于字典类型的可以对应到树型数据(Sets->Tree),不过二者存在明显的差异性,树型数据以路径为键,由路径的分支数解构运算发生的层级。因为 Python Script 升级后可以自行安装 Python 扩展库,这大大增加了 GH 下可以使用的数据结构或类型。

图 1.3.1-7 GH 内置的基本数据结构
1)List(列表)
列表是这几个数据类型中最基础,也是最简单的类型,对列表的操作组件位于Sets->List下。
编程最好的学习方法,是结合文字的解释,观察数据的前后变化,确定组件的功能和调用(输入端、输出端)的方法。有时,需要变化输入数据来观察输出数据的变化,更清晰的理解组件功用。因为设计的代码段结合到了空间设计几何形态或相关分析,这有益于对参数化设计途径的理解。
A组:
🍋🟩代码段-练习-1: ( )
这是一个非常简单的代码段,通过手动控制输入点的移动,同时控制偏移曲线形态的方法来初步认识参数化的意义。在表达上,可以通过Dot Display组件修改点的显示颜色和大小,这有助于标识出特殊的,或者重要的,需要说明问题的点;而Point List组件常用来标识出点列表中点的顺序索引,方便观察点位置。这在编写代码时,方便组织点数据实现设计意图。
代码编写要尽量用更少的组件完成设计或数据分析任务,因此需要尽量的将数据组织通过Tree型数据实现,每个Tree型数据通常包括若干个List型数据,从而简化因大量单独List型数据运用造成的繁琐构建。例如本例中,用于构建两根折线的点数据都被尽量组织在一个组件中,例如数据组织于Insert Items和Entwine组件内。在代码(组件)编写过程中,通过Explode Tree方法将Tree分解为单独的列表,移动其中一组点数据后,仍旧用Entwine组件将两组点数据组织在一个Tree下。如果此时不整合数据,那么在后续的代码编写时,会用到两次PolyLine方法将点连线,那么对于后续生成同样逻辑的几何形态(例如最终都构建为梁)对象来讲会非常的繁琐。
Tree型数据用路径名的结构形式表征所包含不同列表的数据意义,从而能够有效地组织各个列表以实现设计目的,这较之单纯使用List来组织数据,则需要对数据本身的结构有更多的理解,但却可以更有效的处理数据结构,组织数据,避免繁琐使用更多的组件达到同一目的。
#1. Insert Items- 将输入的值插入到指定索引值位置上。如果指定的索引值大于列表长度,且Wrap为True时,则循环计算索引值;如为False,则插入空值;

图 1.3.1-8 代码段(列表)-1与结果
🍋🟩代码段-练习-2: ( )
通过构建逻辑(包含设计逻辑及数理逻辑),实现通过各级不同参数的调整达到自由控制最终几何形态的目的,方便设计形式的选择及形态的调整,这是参数化的基本核心意义。在此之上,设计师会尝试设计构建具有更大自由度的逻辑,会更加频繁的使用随机组织的方式。例如本例(图 1.3.1-9)中使用Populate 2D组件随机生成点,并通过输入端Points手动配置非随机点占据的空间位置,用Random Reduce组件随机移除点对象,获取最终可以控制点数量,部分点位置的蓝、红两组多个随机点。
本例需要区分出Random Reduce组件移除和保留的点,以蓝、红颜色区分,配合Item Index和Set Difference组件实现。用Set Difference找出Populate 2D随机生成点索引值与Random Reduce后点在原数据中对应索引值的不同元素,为集合的差运算。
#2. Item Index- 用于检索指定项值(应属于原对象中的元素)的索引值,如果不属于原对象则返回为-1,如图 1.3.1-10 ;

图 1.3.1-9 代码段(列表)-2与结果
又如:

图 1.3.1-10 Item Index 组件示例
🍋🟩代码段-练习-3: ( )
(图 1.3.1-11)拾取多个点,由Nurbs Curve组件构建曲线,再由Divide Curve组件等分曲线获得等分点,由Jitter组件输入端Seed随机打乱等分点,从其输出端Indices中选取的部分索引值提取等分点用于构建新的曲线。这是一个简单的,具有依附关系的参数化设计练习。参数化设计往往会构建这种由一个对象或因素(限制条件)来生成或者控制另一个对象或因素的逻辑。本例实现该目的的核心组件是Jitter,可以随机打乱输入端List输入项,而后从中顺序选取几个对象。这里可仅使用一个List Item组件连接到Jitter输出端Values直接获取点。示例中是使用了输出端Indices,通过索引值位置的变化来学习Jitter的功用。
#3. List Item- 根据指定的索引值,提取对应的项值;

图 1.3.1-11 代码段(列表)-3与结果
🍋🟩代码段-练习-4: ( )
这个设计的形态可以理解为是一个帐篷或者木屋的雏形,但是设计的思维过程是通过数理逻辑的思维来实现,并使其具有参数化的意义,可以通过参数调整获取无数种形式结果,及部分特定参数控制布置位置(图 1.3.1-12)。一般设计思维会直接手动调整底端的管状形式,包括折线段数、长度、曲折方向,结合垂直杆件连接各结合点等,这是设计师草图思考的过程,或者是三维软件辅助设计空间推敲的过程。在参数化设计里,这个思维的过程会有所不同,不同的参数化设计逻辑思维的方式也往往会大相径庭。对于本例的参数化思维,会思考用何种方式可以随机获取底端的管状折线,达到这个目的的的途径不计其数,这里则是给定一个可控制半径的平面圆,在该圆内生成给定数量的随机点,进而连接为折线。因此最终的设计不是手绘草图或三维推敲的结果,而是从这构建的参数化逻辑下,生成的无数种可能中选择一种结果的过程。该参数化逻辑的结果形式的变化是可预测的,也有很多设计的数理逻辑的结果形式变化是不可预测的,这让设计增加了更多的可变性或可能性。
#4. List Length- 获得输入列表的长度,即最大索引值加1(因为索引值从0开始);

图 1.3.1-12 代码段(列表)-4与结果
🍋🟩代码段-练习-5: ( )
这一非常简单的案例(图 1.3.1-13),只是用Partition List组件组织曲线等分点的数据。而Colour Wheel组件生成给定长度的颜色值,可以很方便的赋予不同点组予不同的颜色。Path Mapper组件通过{A;B;C}->{item_count}语句对Tree路径加以组织,将相同长度(项值数量)列表归在一个列表下。
Path Mapper组件的用法在下文中有详细解释
#5. Partition List- 根据指定的长度大小分片列表,返回包含各自长度数量的树型(tree)数据;

图 1.3.1-13 代码段(列表)-5与结果
🍋🟩代码段-练习-6: ( )
由手动控制点构建的曲线,可以通过调整点位置将平面曲线调整为空间三维曲线,所生成的最终折线也会转换为三维空间曲线。其中最初建构的两条曲线为设计的结构线,设计的结构线往往可以直接用于结构分析中的输入条件,当然,二者有本质的区别,本文中所解释的设计结构线为设计师构思空间形式或参数化数理逻辑的基础控制线。
该练习(图 1.3.1-14)是由两条控制线的等分点穿插组织形成最终的管状折线。所用到的核心组件Cull Pattern可以根据输入的布尔模式(用True和False,或者1(非0数据均可)和0表示)移除部分点,达到数据组织的目的。这里用Replace Items组件替换一组点列表的方式合并两组点列表数据。
显示点的索引除了直接使用Point List组件标识外,还可以用Text Tag 3D或者Text Tag组件,输入端给定位置Location和标识文字Text显示点索引。
#6. Replace Items- 指定索引值和新项值,用新项值替换输入列表中指定索引值对应的项值;

图 1.3.1-14 代码段(列表)-6与结果
🍋🟩代码段-练习-7: ( )
Random组件产生的随机数是伪随机,当给输入端Seed一个整数值时,生成给定Number数的一个随机列表。如果要产生多个随机列表,则可以在Seed端给多个值(每个值均位于单独路径下,用Graft Tree组件实现,或者直接在输入端右键选择Graft选项)。如果这用于Seed输入端的多个值也为随机产生,则可以再增加一个Random组件,那么产生的多个随机列表,仅有增加的Random输入端的一个Seed值控制,从而避免调整多个值。
图 1.3.1-15 这个方案构思了一个架空的平台雏形,手动控制边线的形态,只是支撑结构线由Reverse List组件反向列表元素顺序,构建反向交叉的形式。
#7. Reverse List- 反转输入列表的顺序;

图 1.3.1-15 代码段(列表)-7与结果
🍋🟩代码段-练习-8: ( )
通常给Graph Mapper组件输入端一个序列数,在输入端上右键选择内置的图形函数获取对应的运算结果。这个图形函数不仅显示曲线图形,还可以调整函数曲线的关键位置点,直观观察曲线的变化,这有易于方便调整建立的具有图形函数属性的设计曲线。
图 1.3.1-16 这个练习,除了用Graph Mapper组件来调控具有图形函数特征的曲线形式之外,其中Shift List组件提供的方法可以偏移列表的索引位置。当有多个列表时(每个列表为一组曲线分割点),输入Series组件生成的序列,每个列表相对前一个列表依次向右偏移一个单位;反之亦然,即给负值,向左偏移,可以构建出竹筐编织的效果。
#8. Shift List- 将输入列表向上或向下移动,移动的多少由输入项Shift确定。如果Shift为1,则上移一位,Shift为-1则下移一位。Wrap输入端用于配置布尔值,为True时第一个项值被移到列表的底部,为False时,第一个项值被移除;

图 1.3.1-16 代码段(列表)-8与结果
🍋🟩代码段-练习-9: ( )
给定一个空间盒体,由Populate 3D组件在其内部生成随机点后,使用Sort List组件按照一个方向或者延一条曲线排序这些随机点来构建空间曲线或折线,这是随机空间曲线构建的一种方式。这个练习案例(图 1.3.1-17)的设计意图是构建生成一个空间中简单的方形折线状构筑物,可以通过Populate 3D组件输入端Seed生成多种结果,从众多结果中选择一个适合的形态作为最终设计的选择。也可以构建一组随机形式,每个折线状构筑物均有变化,作为雕塑、变化的灯柱,或者尺度足够大到容纳人的空间体。
#9. Sort List- 输入端和输出端均包含Keys键与Values值。输出端的keys将输入端的Keys所对应的列表按顺序自动排序,输出项值(Values)按照输出键(Keys)索引值位置排序输入端的Values值;

图 1.3.1-17 代码段(列表)-9与结果
🍋🟩代码段-练习-10: ( )
目前很多建筑的表皮(实体或幕墙)设计为 Delaunay triangulation(狄洛尼三角剖分) 的三角网状空间变化形式,使得建筑彰显出现代的时尚感。Delaunay Edges组件提供了构建三角网边线的方法,输入端Points是给定的一组点列表。在图 1.3.1-18这个案例里,除了获得三角网格的形式外,给定一个可控制的位置点将随机点分为两组,只是部分生成三角网。切分位置控制点由Dot Display组件显示,由Closest Point组件提取随机点中到控制点最近点的索引值作为切分Split List组件输入端Index的参数输入值。当左右移动控制点,生成的三角网发生偏移;调整Populate 2D组件输入端参数,可以获得多个形式结果。这个练习仅演示了平面的三角网形式,当变化随机点的Z值(或点垂直于某一表面的方向)后,可以获取空间三角网形态,丰富建筑表皮及空间形态的变化。
#10. Split List- 按输入索引值的位置切分列表;

图 1.3.1-18 代码段(列表)-10与结果
🍋🟩代码段-练习-11: ( )
这个练习(图 1.3.1-19)的设计受启发于工厂粗大输送管线所散发出来的工业风。不过,该练习的主要目的是在 GH 空间中标注空间尺寸的方法。很多人会意识到,当在体验实际的建筑,尤其在三维空间中观察建筑时,即使空间复杂多变,也很容易理解这空间的形态。但是将它转换为二维的图纸,解读起来往往让人费解,这也许是建筑信息模型(Building Information Modelling,BIM)所要解决的问题之一。当二维图纸让人费解时,往往给出三维模型和关键的标注,则一眼可以辨识空间结构,而没有必要在二维上费力的解读。本例中使用Aligned Dimension组件标注粗钢管的等分尺寸。
#11. Sub List- 根据输入的索引值区间选取输入列表对应的区间项值输出;

图 1.3.1-19 代码段(列表)-11与结果
B组:
🍋🟩代码段-练习-12: ( )
这是理解设计深度的一个小练习。不同设计师或者不同设计工作室、设计团队的设计流程,不同阶段对设计深度会有不同的理解和要求。但是,当对细节把握的越深,设计的把控就会越全面,建成后效果就越接近于设计本初,从而尽量减少偏离设计初衷的损失。图 1.3.1-20 这个练习给出了横梁与拉杆(或钢索)的内部锚固方式,让设计深度略微增加细节的把控。同时需要注意,在参数配置时,如果一个参数受制于另一个参数,那么通常会把这种关系表述出来,而不是分别给定参数,例如本例在用Evaluate Length组件提取直线近两端等距的点时,不是分别给定两个Number Slider组件,而是由Length组件计算直线的长度。给定一个值后,通过减法运算获取另一个点位置,再用Merge组件将其合并在一个数据下,输入到Evaluate Length的Length输入端。
#12. Dispatch- 根据 Dispatch pattern输入端布尔值(分组模式),将List输入端数据分成两组,对应为 True的索引输出列表值到输出端List A;为False的到输出端List B;

图 1.3.1-20 代码段(列表)-12与结果
🍋🟩代码段-练习-13: ( )
参数化除了设计空间形态外,设计分析(及规划分析)都是其重要的内容之一。图 1.3.1-21这个案例实际上可以理解为类似用于生态分析的扩展组件Lady Bug运算方法上极简单的一个示例。这里假设了由一个点构建的球体作为太阳,太阳向四周发射光线(表述为直线或向量),计算有多少光线落在了折面的建筑表面上,即建筑光照分析的一个简单表述。Project Point组件是完成这个运算的核心组件,将输入端的点Point,按照给定的方向Direction投影到给定的几何对象(Geometry)上,如果有投影则返回投影点,如果没有则为空值(<null>)。进而由Null Item组件判断空值,返回布尔值用于后续计算。
#13. Null Item- 判断输入列表中是否存在空值(Null)或无效值(Invalid),存在则为True,否则为False;

图 1.3.1-21 代码段(列表)-13与结果
🍋🟩代码段-练习-14: ( )
调整空间几何对象的尺寸(尺度),一个形态可以表述为具有同一逻辑的不同设计对象,例如这个练习(图 1.3.1-22)的折线面,可以理解为铺地、条凳、围墙,乃至建筑体等。如果给不同的材料及细节的构造,就会有不同的风格形式,不同的空间形态感受。在这一逻辑下,可以由内外曲线调控折线面延申扩展的程度,由随机数控制垂直于曲线点随机移动的距离,从而获得不同曲折变化结果。这个练习也通过Pick'n Choose组件,给定模式组织两组点列表,调控折线面曲折形式。
除了点,线和面(包括曲面和 mesh 面)都会有向量的属性,例如本例中Divide Curve组件在等分曲线的同时,其输出端Tangents也会输出等分点位置曲线的切向量,那么各等分点位置上垂直于曲线的向量,则仅需旋转切向量 90 度角。善用线面的向量属性,可以更加自由的调整几何对象的形式,达到预期设计的目的。
#14. Pick'n'Choose- 根据输入端 Pattern 输入的序号模式,从对应序号的输入端中依次选取项值;

图 1.3.1-22 代码段(列表)-14与结果
🍋🟩代码段-练习-15: ( )
在SketchUp这类非参数化设计的软件平台下推敲设计方案,之所以会增加设计师的负担,是因为设计是一个不断反复推敲的过程,当基本的控制线发生变化时,就不得不重新修改所有对应与之关联的后续模型构建工作。很多时候,一个设计方案要反复推敲数次或数十次不止,如果不变化核心的设计(数理)逻辑,参数化的优势则显而易见。例如图 1.3.1-23这个练习,并没有采用随机数等随机生成的方式,只是用两组点控制生成两根折线来分别构建一个墙体和一个折线条凳(或路边缘,亦或墙体)。这非常接近传统的空间形式推敲过程,可以通过移动点的位置调整两根控制线的形态,但后续生成墙体或条凳等具有体积的对象时,在由 GH 组件编写联动的代码实现后,就不再需要重复构建后续几何对象。这一参数化的过程不仅节省了模型重复构建的劳作,同时调整控制线的同时,可以实时生成最终的设计形态,即时的结果反馈有利于设计推敲。
设计中常用的构建模式或者逻辑,即编写好的常用代码片段(例如生成墙体的代码段,又或者计算曲线上点垂直向量的代码段),通常可以用Cluster将代码段封装为一个组件,方便后续调用,例如该例中可以对墙体进行封装(本例未给出封装)。
Cluster 封装的具体方法可以查看相关章节
#15. Replace Nulls- 将输入端 Items 输入数据中存在的空值或无效值替换为指定的项值;

图 1.3.1-23 代码段(列表)-15与结果
🍋🟩代码段-练习-16: ( )
为盒体生成随机点后,用Sort ALong Curve组件延给定曲线排序点后构建空间曲线的方法,配合使用Deconstruct Box和Domain Box组件切分单一盒体为多份,由多个盒体生成不同随机点列表,构建多根空间曲线。该练习(图 1.3.1-24)是建立三根空间曲线,各自等分的点由Weave组件实现数据编织组织。
#16. Weave- 按照输入端Pattern输入的序号模式从对应序号的输入端中选取项值,并循环重复输入的序号模式直至全部选取完成;

图 1.3.1-24 代码段(列表)-16与结果
C组:
🍋🟩代码段-练习-17: ( )
该练习(图 1.3.1-25)为由随机数值填充给定高程数据的缺失值,并标注高程数据的处理过程。给定的高程值和随机生成的替换高程值并没有统一的列表长度,使用Larger Than组件判断,配合Stream Filter组件输出最长列表长度值,用于Populate 2D组件的输入项Count,生成该长度值的随机点数量。由Combine Data组件用随机生成的高程值填充给定高程值中的空值,用于随机生成点的 Z 值。
在高程数据处理时,通常用Deconstruct方法将点对象解析出 x、y 和 z 值,调整 z 值后,再用Construct Point组件将其组合成新的高程点。
#17. Combine Data- 输入端多个输入数据列表将按照最长列表长度分别使用各自列表尾项值填充至等长,并对应填充 Null 空值位置,注:放大该组件,通过 +,-按钮可扩展或减少输入端项数量;

图 1.3.1-25 代码段(列表)-17与结果
🍋🟩代码段-练习-18: ( )
Sift Pattern和Combine Data组件数组组织方式互逆。这里将等分点通过Sift Pattern组件按照给定的模式输出为3个输出项列表,对每一点列表执行Perp Frame->Circle->Evaluate Length的过程操作,在生成不同半径的圆上提取各自的一个点,再配合使用Combine Data组件将三支数据组织回最初的数据结构形式(图 1.3.1-26)。这种先对数据按某种形式分支后,各自执行不同的操作再组织返回到原来的数据形式的过程,是逻辑构建的一种技巧,除了应用配对互逆的组件外,通常是直接操作数据路径达到同样的目的。
#18. Sift Pattern- 输入端 List 列表数据将按照 Sift Pattern 输入端提供的模式循环分组,模式中的序号代表输出端的序号,按模式循环提取,未筛选项填充为空值,保持筛选后的列表长度与输入列表长度一致,注:放大该组件可扩展输出端项数量;

图 1.3.1-26 代码段(列表)-18与结果
D组:
🍋🟩代码段-练习-19: ( )
这个练习(图 1.3.1-27)除了说明组件自身,并没有包含其它的数据处理、逻辑构建或者任何设计上的表述。Cross Reference、Longest List和Shortest List这三个组件通常用于将不等长的数据列表组织为等长,用于后续代码编写的输入项。
#19. Cross Reference- 输入端列表 A 中的每一个项值均各自与 B 中所有的项值匹配,反之亦然;
#20. Longest List- 输入端列表 A 和 B 项值一一对应,列表长度较短方将填充其尾项值直到完成一一匹配;
#21. Shortest List- 输入端列表 A 和 B 项值一一对应,直至列表长度最短的数据用完为止。
注:放大各组件可扩展输入端项数量

图 1.3.1-27 代码段(列表)-19与结果
2)Sets (集合)
集合的数学概念为元素的集合,具有无序性(集合里的元素没有顺序),互异性(集合中每个元素只出现一次),确定性(集合中的元素必须是确定的)。如果集合含有所要研究问题中涉及的所有元素,那么这个集合为全集(Universe,U)。全集下的子集(或同一范围内的不同集合)可以相互比较,包括的基本运算有:交运算、并运算、差运算和补运算。GH 集合提供了几种基本运算的组件,如下示例。
注,只有使用 Creat Set 才建立集合,组件输入端的 Set 并不一定是集合,可理解为数据集或列表。
A组:
🍋🟩代码段-练习-20: ( )
各种类型的数据处理过程中,有时会在同一列表下产生重复的数据,这会影响对象数量的统计,重复元素较多时也会增加内存和计算量,有时也会影响后续实现特定需求的代码编写,因此有必要移除重复的元素。例如,本次练习(图 1.3.1-28)对Popular 2D产生的随机点列表,给与两次Seed值不同的Random Reduce随机移除点操作,并将两次输出合并。此时就可能产生重复的点数据,使用Create Set组件直接建立集合,重复的元素会自动被筛除掉。
练习里用到了Dash Pattern组件,可以将曲线转换为虚线形式,只是这里并不是构建设计几何对象,而是用于了线型表达上。
#1. Create Set- 建立有效数据集,移除空值和无效值,重复元素仅保留一个;
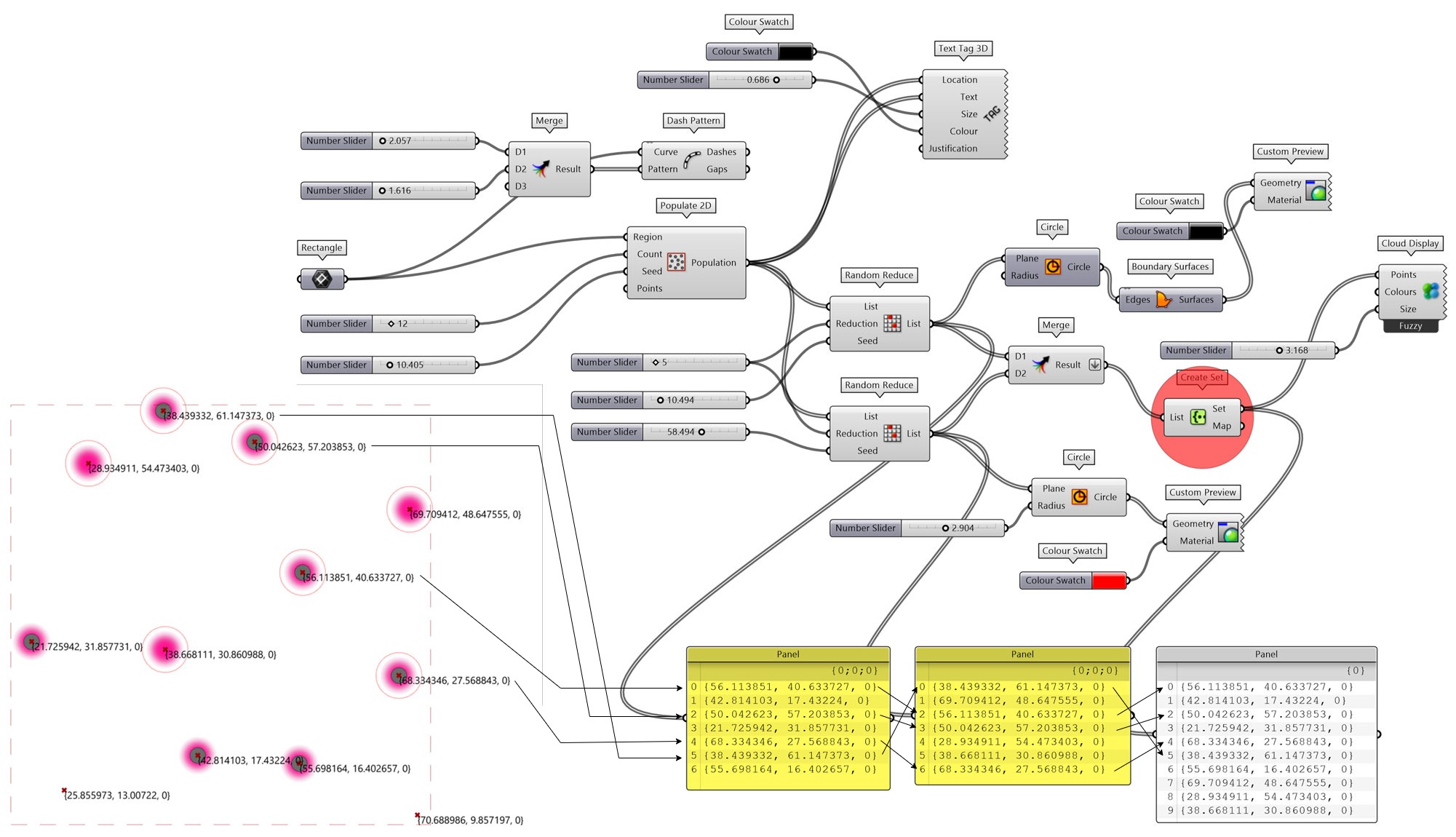
图 1.3.1-28 代码段(集合)-20与结果
🍋🟩代码段-练习-21: ( )
图 1.3.1-29练习中的随机三角网格包含多个参数控制,一是,用Populate 2D组件产生多个随机点;二是,用Random组件随机生成两个索引值,提取随机点列表中的两个点,用于绘制两个圆。并通过Set Difference组件提供的差运算求得部分点,用于Delaunay Edges组件输入端建立三角网格。两个圆的中心点也可以修改为手动配置,这样可以有目的的控制最终三角网格布置的位置。因为用于生成随机颜色的两个Random组件配合使用生成多个随机列表的方法经常被使用到,可以考虑Cluster方法封装,方便调用。
#2. Set Difference- 拾取 A 子集元素,但是移除 B 子集与 A 子集相同的元素,为差运算;

图 1.3.1-29 代码段(集合)-21与结果
🍋🟩代码段-练习-22: ( )
经常使用多代理(Multi-agent system,例如NetLogo③工具)的方法建立个体行为规则,从而“涌现”宏观形式,可以借助这一自下而上的方法生成种植林缘线。这个练习(图 1.3.1-30)则给出了另一种产生林缘空间的方法,设计过程为:由Populate组件生成区域内随机点;->由Random Reduce组件随机提取两部分点;->给定随机半径,由每一随机点生成这两部分的随机圆,各点的随机圆大小均不同;-> 用Point in Curves组件在各圆上提取随机点;->对这两部分圆提取的随机点用Set Difference(S)组件求差集,并由MetaBall组件融合为元球曲线,从而获取随机生成不同结果的林缘线形态。上述过程就是建立的一个数理逻辑,可以说是一种设计上的算法。
该练习给定的是一个矩形区域,实际上设计的区域往往不规则,可以根据实际情况调整输入条件。
#3. Set Difference(S)- 拾取 A、B 子集元素,但是移除 A、B 子集共同的元素,为差运算的拓展;

图 1.3.1-30 代码段(集合)-22与结果
🍋🟩代码段-练习-23: ( )
除了Delaunay(如用组件Delaunay Mesh或Delaunay Edges)三角网格,Voronoi泰森多边形也是常用到的几何形态,不仅用于区域距离分析,也能构建出多变的几何空间形态,如图 1.3.1-31。Voronoi Cell组件可以构建三维空间形态的泰森多边形,其输入条件为点Point及其邻域点Neighboours。随机点的产生是用Set Difference组件求两个球体交集部分所包含的空间随机点。
#4. Set Intersection- 拾取 A、B 子集共同的元素,为交运算;

图 1.3.1-31 代码段(集合)-23与结果
🍋🟩代码段-练习-24: ( )
通过点或者线可以构建磁场,例如用Line Charge组件构建线磁场,位于磁场中的每一个点都可以用Evaluate Field组件提取出点所在位置的磁向量(Tensor),那么位于磁场中的对象则可以延着磁向量移动。因为磁场是变化连续的,延磁向量移动的对象继承了磁场的这一属性,移动后的结果彰显出磁场性质的规律。一方面,可以利用磁场构建对象之间吸引或互斥的运动,例如功能关系相近的对象之间可以配置较高的吸引力,而功能冲突的对象之间则可以配置较高的斥力,因这种关系构建的磁场影响对象之间相互的位置关系,可以获得对象位置优化的结果;另一方面,磁场的连续性特质,可以构建出连续的表面变化,例如地形表面,因此可以由磁场生成地形等连续变化的表面形态。磁场的应用途径不止上述两种方式,在设计的过程中,可以继续发掘利用磁场应用的场景。
这一练习(图 1.3.1-32)也用Set Majority组件提取 3 组等分点邻近点至少出现两次的点对象,即图中的红色圆点。也就是说红色位置至少是路径上两个等分点的最近点,相对只出现一次的蓝色点,红色位置在某种意义上更加重要。
#5. Set Majority- 拾取3个子集中出现次数多于1个的元素,或理解为移除仅出现一次,非至少两组共同拥有的对象;
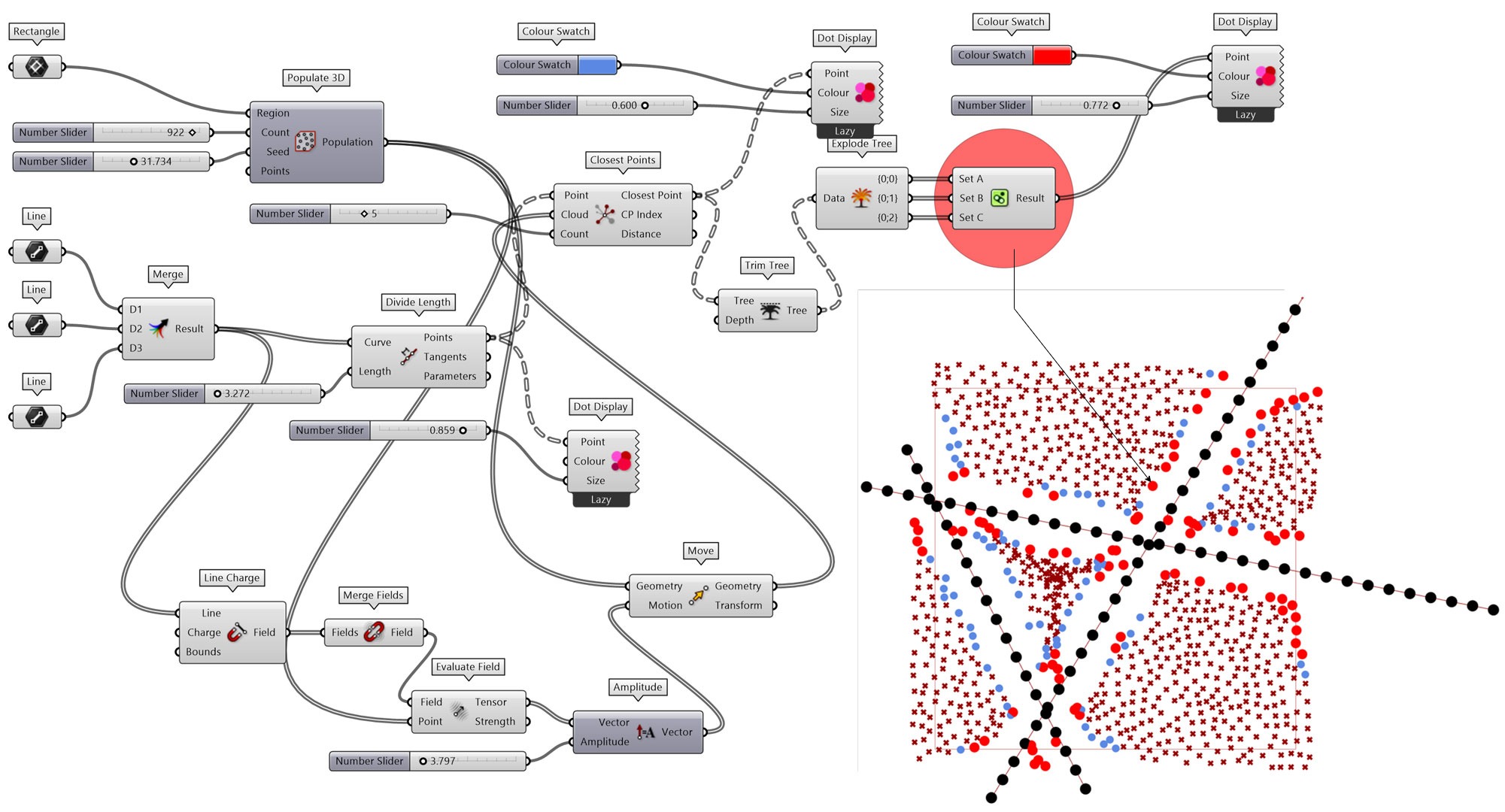
图 1.3.1-32 代码段(集合)-24与结果
🍋🟩代码段-练习-25: ( )
Image Sampler组件可以提取输入图像的色彩通道,这包括RGBA(红、绿、蓝和透明通道)及各自单独的通道,和Hue(色相)、Saturation(饱和度)及brightness(明度)等。GH 在Display->Colour面板下提供了多种颜色值处理的组件。图 1.3.1-33 是一个提取两个图像颜色,用Set Union组件并运算合并颜色值后,赋于给点阵列,显示颜色的练习。注意,Image Resource组件仅预览图像。
#6. Set Union- 为输入多个子集的集合,保持互异性,为并运算;

图 1.3.1-33 代码段(集合)-25与结果
B组:
🍋🟩代码段-练习-26: ( )
梁(檩)椽设计模型的构建关键是处理相互搭接的位置,椽方木截面自身通常要尽量垂直于梁(檩),自身通常也要尽量保持垂直(在平面视图上,只看到椽子上表皮,没有变形歪斜),这样梁(檩)椽能保持合理的受力状态。传统的大木作因为设计规矩,梁(檩)椽的参数化模型搭建实际上相对容易,而现代各类多变的设计形式,在处理参数化逻辑时,则需要获取和调整线面体上作用的不同向量(参考平面)方向,或垂直、或相切、或其它作用方向。同时,在建立参数关系时,当基础的控制线发生旋转偏移时,梁(檩)椽相互垂直的关系不应该发生错位。
图 1.3.1-34这个练习是将椽的控制线作为椽下皮一边,不是很合理,可以调整为控制线作为椽下皮的中心线,这个练习的代码段中并没有调整。
#7. Carthesian Product- 类似 Python 中的zip()函数,将两个长度相同的子集,按索引值两两结合到同一路径之下;

图 1.3.1-34 代码段(集合)-26与结果
🍋🟩代码段-练习-27: ( )
设计也可以是动态的,例如将一次性计算转换为各个位置上的单独计算。动态的逻辑构建是变化某一或多个参数时,获取一个连续的变化结果。参数的变化通常会和Params->Util->Trigger组件配合使用(该练习中未配合),参数随时间(迭代)自动变化,避免手动拖动数据滑条。
这里绘制了一条路径(>图 1.3.1-35),由Evaluate Length组件控制位置点的变化;并给定一个半径绘制圆(缓冲区域),控制MetaBall(t) Custom组件生成的元球曲线包含的点位是否落于缓冲区域。该练习下的Point In Curve和Disjoint组件均输出布尔值,再由布尔值配合Cull Pattern组件提取对象。如果要将 True 变为 False,而 False 变为 True,可以使用Gate Not组件。布尔值的操作组件位于Maths->Operators下。
#8. Disjoint- 判断 A、B 两个子集是否没有相同元素。如果没有返回 True,否则返回 False;

图 1.3.1-35 代码段(集合)-27与结果:动画

图 1.3.1-35 代码段(集合)-27与结果
🍋🟩代码段-练习-28: ( )
对于规格统计,一方面,可以查看设计对象的规格变化区间,辅助调整设计,使设计趋于合理;另一方面,用于最后概预算,及提供给生产方的加工数据。对于大批量的嵌板(或者任何设计对象单元),最好在设计之初就规划好有限的规格形式,避免增加加工成本。本次练习(图 1.3.1-36)的空间三角网格数量很少,是用Populate Geometry组件随机生成控制点,演示按区间统计面积的方法,并给出颜色标识(面积位于同一区间为同一颜色值)。这里涉及到三个关键知识点,一个是对于区间的运用,区间相关组件位于Maths->Domain面板下;另一个是应用Gradient组件建立连续变化的颜色;第三个则是用Format组件格式化字符串,例如{0:0.000};{1}语句配置了小数点位数为0.000,精度为3。
#9. Member Index- 返回Member输入端元素(项值)在数据集(Set输入端,非集合)中对应出现的索引值(可能为多个)及数量。类似数据查询功能;

图 1.3.1-36 代码段(集合)-28与结果
🍋🟩代码段-练习-29: ( )
模式是设计中常用手法之一,模式意味着可以重复的一种规律,这不仅反应在实体对象上,同样也可表述为空间模式。GH 组件提供有很多根据输入条件(模式)变化数据关系的组件,例如Sets->List下的Dispatch,Pick'n'Choose,Weave;Sets->Sequence下的Cull Nth,Cull Pattern等。该练习(图 1.3.1-37)用0、1、2三个值构建了一个模式,用Duplicate Data组件重复复制该模式,进而用Replace Members组件对应模式值替换为旋转角度值。事实上,可以直接用旋转角度值直接配置为模式,但是旋转角度值较之简单的整数值复杂,并不方便快速的手工输入调整模式,因此在模式的建立上,模式的输入值设计上一般优先考虑简单整数值,或者布尔值。
#10. Replace Members- 指定项值替换新的给定值,值为 Primitive 类型;

图 1.3.1-37 代码段(集合)-29与结果
🍋🟩代码段-练习-30: ( )
这个练习(图 1.3.1-38)是一个动态撞击的模拟,将撞击结果作为设计的一种形式。实际上,类似的物理碰撞或运动产生某种形式的过程和结果的设计手法可以无限的拓展。该代码段中Voronoi 3D组件可以通过给定输入点建立空间泰森多边形,并由各个单独的多边形体生成空间随机点(用Poplulate 3D组件)用于在球体穿过时判断是否被运动的球体包含(Point In Prep)来判断是否要移除(Cull Pattern)该多边形体,从而产生空洞。
练习中用到了两个球体同时穿过泰森多变形构建的方体,在数据组织时通常不会分开处理,而是在一个数据集下,以数据组织的方式,尽量减少重复逻辑的构建,并降低组件使用量,达到同时撞击的目的。在组件的输入和输出端,右键菜单包含Reverse,Flatten,Graft,Simplify等数据组织功能,这些功能组件在Sets面板下有对应的单独组件,但是因其经常被用到,而被置于右键菜单,方便调用,并减少组件使用量。
#11. SubSet- 判断是否包含,即子集 B 是否是 A 的子集;

图 1.3.1-38 代码段(集合)-30与结果:动画

图 1.3.1-38 代码段(集合)-30与结果
C组:
🍋🟩代码段-练习-31: ( )
GH 常用于建筑等人工事物的设计,但是对于自然事物的数据也有很好的处理能力,例如地形规划分析和设计。只是当规划区域较大时,高精度地形的数据量非常大,目前 GH 对于处理“大数据”的能力有限,运行时间可能过长,甚至宕机。另一个在设计中常用到的自然对象是植被,虽然 GH 可以建立抽象的树木,而自然事物的复杂性和数据量,使得趋于逼真形态树木的表达耗费较大计算资源。目前已经有很多自然景观渲染的算法,不过这多用于游戏引擎或影视类制作软件,例如 UE5(Unreal Engine)下的 Nanite、Lumen等。
练习图 1.3.1-39中,File Path指定文件路径后(使用文本格式的高程数据),由Import Coordinates组件读取点数据。地理信息数据通常为投影坐标数据,研究对象通常远远偏离平面坐标零点,因此一般需要将其转换为相对坐标,移动到平面坐标系的中心。在 RH 下,如果几何对象远远偏离坐标中心点,几何视图操作将不会很方便,同时几何对象可能出现显示错误。
在地形表达上,用Delaunay Mesh组件建立地形几何表面,用Gradiant组件根据配置的高程分类区间赋予地形表面渐变颜色,用Contour组件绘制等高线。
#12. Delete Consecutive- 移除连续相同的项值,同时返回最大重复值数量。输入端Wrap确定是否首尾相接;

图 1.3.1-39 代码段(集合)-31与结果
🍋🟩代码段-练习-32: ( )
图 1.3.1-40是预先给出规格,根据给定规格划分方格网的练习。这里对规格的组织通过对区间的数据处理配合Find similar member组件实现。由Random组件生成指定区间内,给定数量的随机数。对这些随机数规格化,是要将各个随机数值规范到给定的固定值上(即为随机值替换为最近固定值)实现规格化。
练习中红色Panel面板标识出当前等分的状态。这个状态包含超出和未超出线段长度两种结果,由Smaller Than组件作长度比较运算,并将输出结果的布尔值作为Stream Filter组件输入端Gate的输入参数。那么,当为 True时,Stream Filter将输入端1的数据流出;为 False 时,将输入端0的数据流出,实现状态的判断。两种状态的文字说明,预先通过Format组件格式化实现。
#13. Find similar member- 输入端 Data 给定数据集,逐一在输入端 Set 中查找最接近的值替换,可以规格化数值;

图 1.3.1-40 代码段(集合)-32与结果
🍋🟩代码段-练习-33: ( )
在 GH 中,文本处理使用量相对不多,Sets->Text下给出的字符串处理方法远远不及 Python 对文本处理的能力。但是,对文字的处理是无法避免的,这不仅体现在规划设计区域地理信息数据。同时,基于参数化的 BIM(Building Information Modelling)的发展,对设计几何属性的文字说明,例如材料说明、造价、及任何相关数据的信息化,都会对文本处理提出要求。练习图 1.3.1-41中Read File组件读取 CSV 格式的 POI(Point of Interesting)数据,这些数据每一条为一个点样本信息,包括名称、分类、经纬度坐标等内容,需要借助Text Split组件将数据提取出来使用。根据经纬度在 GH 中建立点坐标实际上并不合理,应该将经纬度坐标转换为投影坐标,以米或千米为单位。地理信息系统(Geographic Information System,GIS)处理坐标转换(投影)是基本操作,工具很多,可以尝试借助QGIS④完成,也可用 Python 相关地理信息库完成。在 GH 下,基本的组件对 GIS 的支持基本为零,只是有Params->Input->Import SHP组件可以读取 SHP 格式的地理信息数据几何对象,但这并不包括属性表信息。因此,目前用 GH 处理 GIS 数据并不适合,但是应对设计背景等简单分析和可视化,依靠目前的工具足可以实现。
练习中,由Closest Point、Key/Value Search、Format和Text Tag 3D等组件的配合使用,实现了移动点,查询 POI 点信息的功能。
#14. Key/Value Search - 输入端Keys和Values保持长度一致,一一对应,类似 Python 中的字典键值对。输入端Search中数据对应到Keys端中搜索,根据Keys端对应的索引值返回Values输入端的值。如果未在Keys中搜索到Search端给的数值,则返回<null>空值。

图 1.3.1-41 代码段(集合)-33与结果
3)Tree(树型数据)
GH 设计者 David Rutten 绘制的 Tree 图表如图 1.3.1-42,经典解析了 Tree 型数据结构。Tree 由各个分支(树枝)即路径组成,每个路径下面包含由索引值标示的项值(树叶)列表(List);路径组成由{A;B;C;D;...}表示,控制树型数据的分支情况,例如图中,A 项全部为‘0’,B 子项的‘0’,‘1’,‘2’分支全部由 A 项父级分支生长出,为{0;0},{0;1},{0; 2},获得基于父级分支 A 子级 B 的3个子分支(路径)。同理,C 项是基于 B 分支的子级分支,这时 B 项成为 C 项的父级,例如 B 项为‘0’的分支生长出由 C 项控制的‘0’,‘1’两个子级分支,分别为{0;0;0}和{0;0;1}, 所有分支的表示依次类推。

图 1.3.1-42 Tree(树型)数据结构。图片引自:Andrew Payne & Rajaa isssa.The Grasshopper Primer, Second Edition – for version 0.6.0007. 2009.
Sets->Tree提供了对 Tree 类型数据处理的工具。
A组:
#1. Clean Tree - 选择性移除 Nulls、Invalid 和 Empty值(Nulls 表示显示地将变量设置为“无值”(null),而 Empty 意味着变量被定义并且有一个值,但是这个值为空,例如空字符串、空列表等);
#2. Flatten Tree - 将所有路径下的项值置于唯一的一个路径之下,即只有一个路径;
#3. Graft Tree - 将所有路径下的项值各个置于各自的路径之下,即一个路径下仅有一个项值;
#4. Prune Tree - 根据输入端Minimum和Maxmum确定的列表长度,提取符合列表长度要求的路径及所有项值;
#5. Simplify Tree - 保持路径数量、索引值和项值不变的前提下,简化路径名;
#6. Tree Statistics - 统计数据的路径名,及路径长度和各列表长度;
#7. Trim Tree - 根据输入端Depth数值从后往前移除路径项;
#8. Unflatten Tree - 将输入的数据按照指定的数据路径结构复原路径分支。
B组:
#9. Entwine - 将输入的所有数据先分别展平,再顺序放置于各自的路径分支之下;
#10. Explode Tree - 将所有路径炸开为单独的列表输出;
#11. Flip Matrix - 将所有路径下索引值相同的项值放置于同一个路径之下;
#12. Merge - 保持所有输入端数据路径名不变的条件下进行合并,只有路径名相同的才会合并到一个路径之下。
🍋🟩代码段-练习-34: ( )
图 1.3.1-43这个练习除了演示Tree下的多个组件使用方法外,还包括用Cluster方法将常用代码段(某一编写逻辑)封装为单独一个组件的方法(需要配置Cluster Input组件和Cluster Output组件,选中所有组件后中键选择Cluster封装,如图中方形红色虚线框起来的图标)。例如分枝-项值-random封装组件,是由两个Random组件构建常用生成多组随机列表数值的方法。另一个演示了Math->Script->Python Script,即用 Python 编写代码辅助组织数据的方式,例如Pts2MeshQuad组件。在练习时,可以直接将 Python 代码复制到Python Script组件下,修改输入输出端名称,和输入端右键下的数据类型为Tree Acess。
用`Python Script`编写 Python 代码辅助数据组织,参考 Python Script 部分。

图 1.3.1-43 代码段(Tree)-34与结果
-
Cluster部分,为选择所有组件后,中键选择Cluster封装组件。 -
Python Script部分,可以直接复制代码至
Maths->Script->Python Script组件中。注意,需修改输入端名称为TreeData,并右键选择数据类型为Tree Access;和输出端名称为PLst。
Python Script-Pts2MeshQuad:
"""Provides a scripting component.
Inputs:
TreeData: Tree 型点数据
Output:
PLst: Mesh Quad 型顶点格式"""
__author__ = "Richie Bao"
__version__ = "2024.08.25"
import Rhino
import rhinoscriptsyntax as rs
from Grasshopper import DataTree
from Grasshopper.Kernel.Data import GH_Path
data=TreeData
branches=data.Branches
PT=DataTree[Rhino.Geometry.GeometryBase]()
def grouper(branches,dt):
for m in range(len(branches)-1):
a=branches[m]
b=branches[m+1]
for i in range(len(a)-1):
lst=[]
lst.append(b[i])
lst.append(a[i])
lst.append(b[i+1])
lst.append(a[i+1])
dt.AddRange([rs.coercegeometry(i) for i in lst],GH_Path(m,i))
return dt
if __name__=="__main__":
PLst=grouper(branches,PT)
🍋🟩代码段-练习-35: ( )
在 GH 的扩展插件中涉及到很多类似生物骨骼形态(或有机形态)的几何算法,可以从food4rhino⑤中的 GRASSHOPPER APPS 下寻找。对于此类算法,通常应用已开发的算法组件或用 Python 和 C# 已有的代码实现,当某些形态的实现并没有提供现成的算法时,往往需要自行编写这些算法。MultiPipe组件可以对输入的列表线段生成相互连接完好的管状对象(图 1.3.1-44),同时可以配置节点位置,杆间直径的变化,使得最终的几何形体呈现生物形态化。杆间变化的粗细在受力情况下具有不同的结构位移(Maximum displacement [cm]),最优的计算结果是位移最小。如果要获得合理的管状粗细变化,可以配合使用进化算法Params->Util->Galapagos和结构计算插件,例如Karamba3D来寻找受力合理的几何形态。

图 1.3.1-44 代码段(Tree)-35与结果
C组:
#13. Match Tree - Tree输入端数据路径将被匹配为Guide端输入的数据路径结构,项值保持不变;
#15. Path Mapper - 根据指定的语法编写路径结构,达到路径结构调整的目的;
#16. Shift Paths - 根据输入端Offset数值从前往后移除路径项;
#17. Split Tree - 根据Mask输入端提供的掩码路径提取数据,路径掩码位置项可以使用?或者*通配符替代;
🍋🟩代码段-练习-36: ( )
练习-34构建的折线之间发生了重叠,未达到最终设计的目的。如果要避免折线间的碰撞,需要调整代码构建的逻辑。该部分练习(图 1.3.1-45 )提供了一种方法,并将其封装为单独的一个组件为可控随机间隔,方便调用。其核心逻辑是在给定区间的随机位置起点间给与给定区间的随机宽度,即用Weave组件编织数据区间起点和宽度,并用Consecutive Domains组件提取为顺序累加值,用于Evaluate Length组件输入端Length的输入值。

图 1.3.1-45 代码段(Tree)-36与结果
Split Tree语法:{path1,path2,path3,...}[idx1,idx1,idex3,...],例如{0,2,...}[1,3,...],如图 1.3.1-46。

图 1.3.1-46 Split Tree 语法示例
⇩代码下载(codeSnippet_data_splitTree.gh)
Masks语法
Set->Tree->Split Tree,Set->Tree->Path Compare,以及Set->Tree->Path Compare等组件都具有Masks或类似的输入端。熟悉Masks语法可以有效的组织数据结构,具体语法如下:
| 序号 | 语法 | 描述 |
|---|---|---|
| 1 | {;;} |
大括号括起树枝(Tree Branches)的掩码。之间用分号分隔。 |
| 2 | [] |
方括号括起元素(项值)的掩码。如果要选择所有的叶子(项值),只需跳过它。 |
| 3 | () |
圆括号用于组织和分组。主要与布尔值或操作符一起使用。 |
| 4 | * |
星号允许在路径中选择任意数量的整数。任何路径树,都允许包含所有分支。 |
| 5 | ? |
问号可以选择任意一个整数。 |
| 6 | 6 |
任何特定的整数 |
| 7 | !6 |
除了给定整数的任何其它数 |
| 8 | (1,5,9) |
组中给定的任何一个特定整数。之间用逗号分隔。 |
| 9 | !(2,6,7) |
除了给定组中任何数外的其它整数 |
| 10 | (2to10) |
给定区间内的任何整数。分界值2和10也包括在内。 |
| 11 | !(1to15) |
给定范围之外的任何整数 |
| 12 | (0,2,...) |
无穷数列的任何整数。序列至少两个整数长,以逗号后的3个点结束。 |
| 13 | (0,2,...,36) |
有限序列的任何整数。 |
| 14 | !(3,5,...) |
不属于给定无穷数列的任何整数。示例结果选择数字0、1、2、4、6、8、10、12和所有剩余的偶数。 |
| 15 | {*}[(0to4)or(9,32)] |
可以使用布尔或操作符组合两个或多个规则。该示例选择树下每个列表中的所有分支的前5项,以及索引9和31对应的项值。 |
Path Mapper(Lexer)语法(图 1.3.1-47)
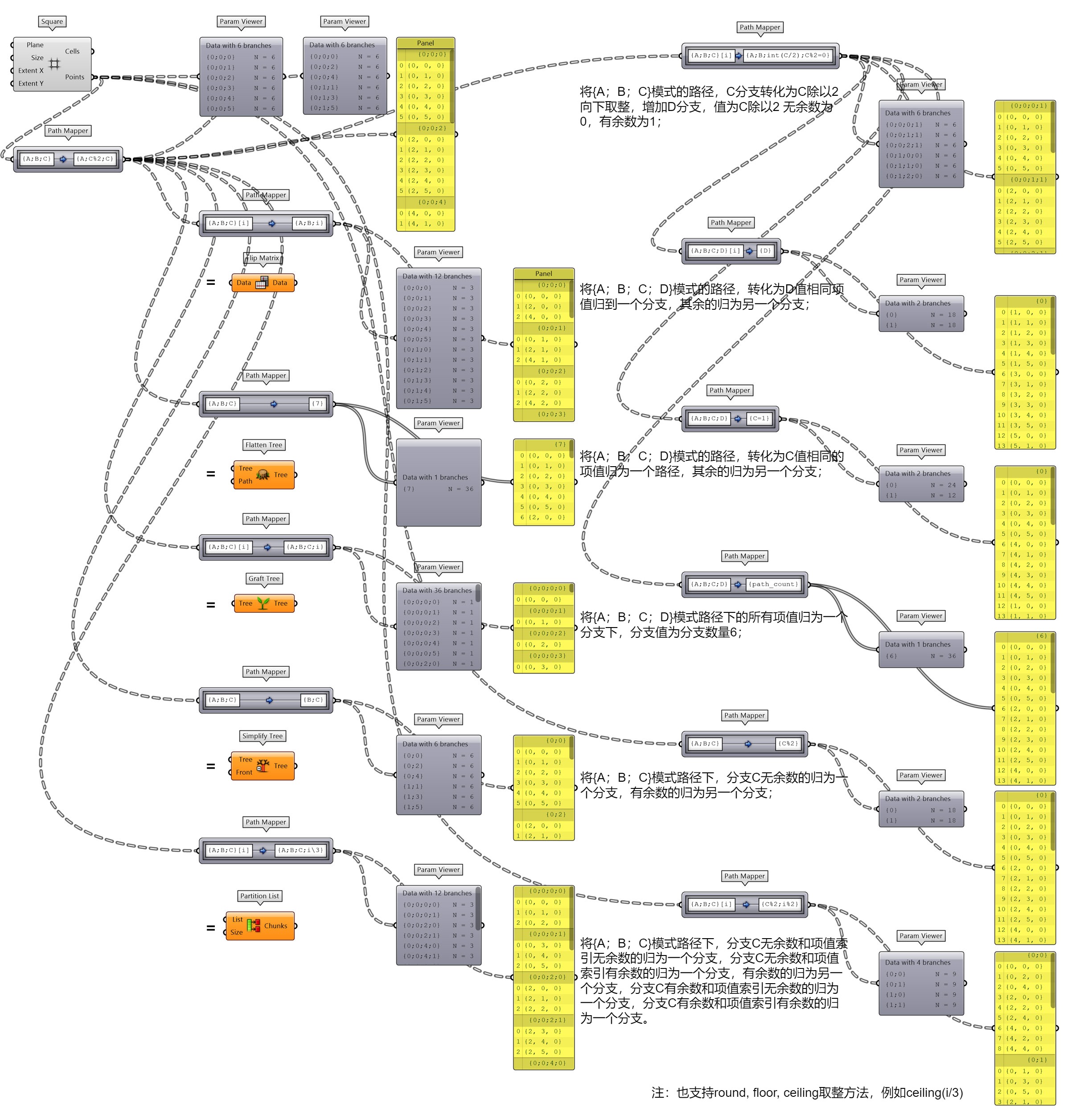
图 1.3.1-47 Path Mapper(Lexer)语法示例
⇩代码下载(codeSnippet_data_mask.gh)
D组:
🍋🟩代码段-练习-37: ( )
抽取一个乡土建筑设计项目的部分代码,用于说明参数化设计中应用组件封装书写代码的方式。对于乡土建筑(民居建筑)、传统古建筑这类具有一定特征归属的设计内容,往往可以把很多空间模式、建造模式、构造模式转换为参数化的数理逻辑设计模块。一方面,作为传统设计模式的总结;另一方面,可以用这些模式来设计新建筑,新空间。练习中建立了几个封装模块,家具位置控制线(图 1.3.1-49),家具位置变换-定位轴线(图 1.3.1-50),墙主体(图 1.3.1-51)和洞口(图 1.3.1-52)等组件。应用这些组件可以迅速的建立墙体及门窗开洞,并布置家具辅助推敲空间形态。同时,封装的人参考定位(图 1.3.1-53)可以布置人模型,比较空间尺度变化的合理性。最终应用自定的封装组件完成设计,如图图 1.3.1-54。
这些封装的组件,实际上可以看作为参数化 BIM (Building Information Modeling)的雏形。在 GH 的扩展插件中有不少可用的面向不同设计方向的 BIM 扩展组件,例如VisualARQ⑥。不过,因为设计类型不同,设计师自身对设计的考量因素,很多 BIM 的扩展组件可能并适合当前的项目,因此,根据项目特点由设计师自主完成及拓展这些模组,逐步形成可应用,可分享的组件,能够加快设计团队建立自有的参数化设计模组库,对于设计团队自身实力的提升不无裨益。
虽然自从2000年08月 SketchUp 首次被释放,2006年03月被 Google 收购之后得以迅速发展,尤其在建筑设计领域得到广泛应用。当设计师已经习惯在三维中推敲方案时,直至今日也不免发现,仍然有不少设计师仍然在二维的世界里做设计。那么,对于参数化设计技术,在2007年 David Rutten 在 Robert McNeel and Associates(Rhino 三维设计模型软件的创造者)构想了可视化编程工具 Grasshopper(GH)(之前最早2003年还有一个 CAD 软件 MicroStation 的插件 Generative Components(GC)),随后也在设计领域迅速普及,尤其在建筑设计行业得以广泛应用,也成为绝大部分建筑类高校院所开设的必要课程之一。然而,今日也不免发现,真正能用 GH 参数化处理设计的设计师为数亦是有限。
#18. Stream Filter - 由Gate输入端指定的输入序号输出数据;

图 1.3.1-48 代码段37结果 |

图 1.3.1-49 家具位置控制线 封装组件 |
|---|---|

图 1.3.1-50 家具位置变换-定位轴线 封装组件 |

图 1.3.1-51 墙主体 封装组件 |
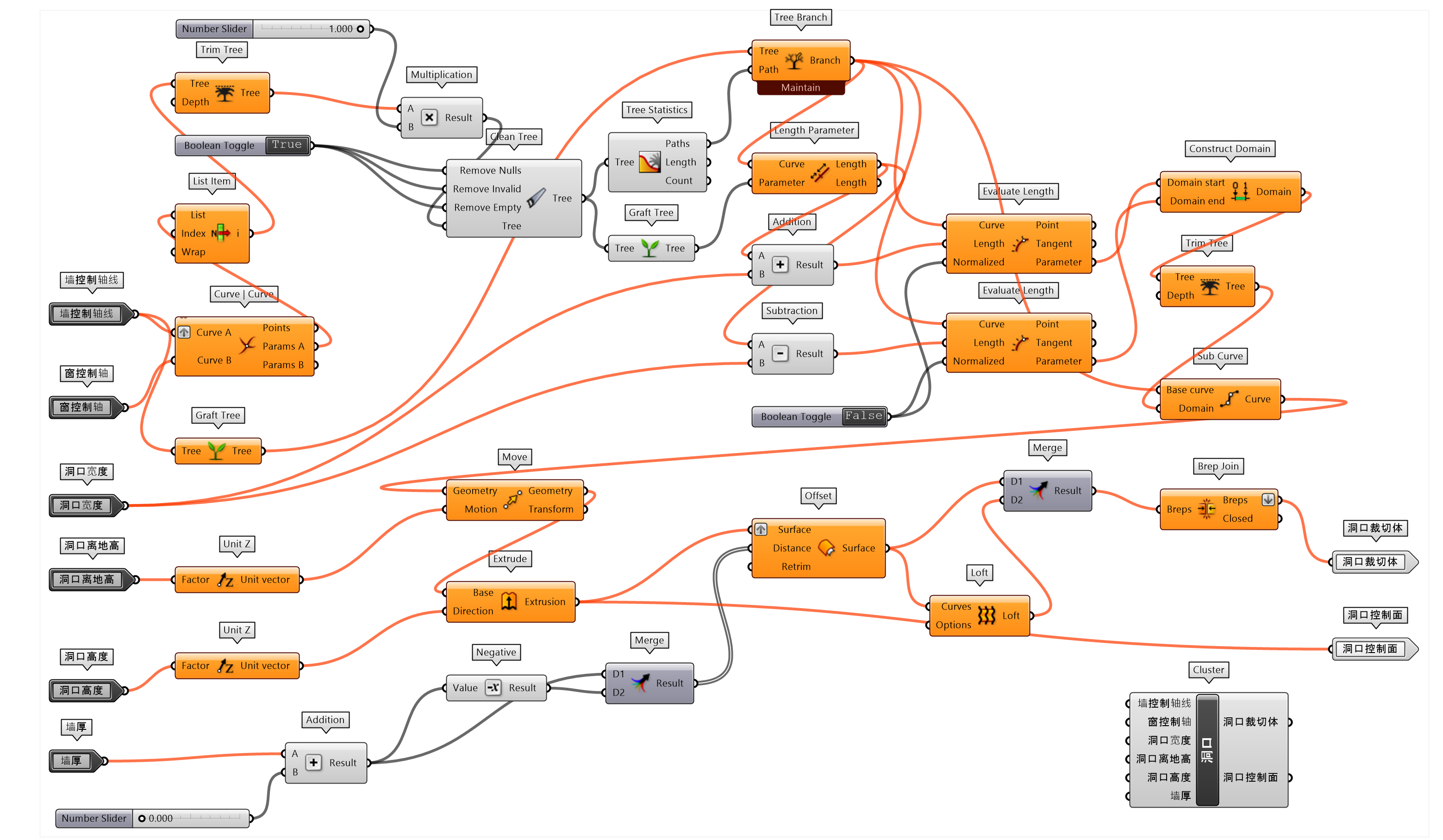
图 1.3.1-52 洞口 封装组件 |

图 1.3.1-53 人参考定位 封装组件 |

图 1.3.1-54 代码段(Tree)-37
🍋🟩代码段-练习-38: ( )
所有的设计基本上都是为人服务,因此要满足人的尺度和使用习惯。图 1.3.1-55中的练习则构建具有一定形式随机性,和人尺度关联在一起的类生物骨骼结构方形框架。最初该练习的设计构想是由人的行为产生空间,这要涉及到人体姿态估计,如 SMPL(A Skinned Multi-Person Linear Model)⑦,及人体姿态与场景交互等⑧,这项研究探讨必然要列入未来的研究列表中。
SMPL 是一个从数千个 3D 人体扫描模型中学习,基于皮肤和混合形状的真实人体 3D 模型,包含可以在 Python、Maya 和 Unity 中使用的代码。
人体姿态与场景交互可以参考 Hassan, M., Guo, Y., Wang, T., Black, M., Fidler, S., & Peng, X. B. (2023). Synthesizing Physical Character-Scene Interactions. arXiv [Cs.GR]. Retrieved from http://arxiv.org/abs/2302.00883 等论文。
#19. Stream Gate - 由Gate输入端指定输出序号,对应输出端输出Stream端输入的数据;

图 1.3.1-55 代码段(Tree)-38与结果:动画

图 1.3.1-55 代码段(Tree)-38与结果
E组:
🍋🟩代码段-练习-39: ( )
图 1.3.1-56的练习是在圆柱体内生成随机点,然后构建点磁场,用于推动表皮点延磁向量方向移动,构建出具有空间变化的表皮形态。对于交叉的支撑结构,除了用Shift List组件偏移点完成外,也可以用Relative Item编写模式实现。
#20. Relative Item - 可以同时或者分别偏移路径(数值)和项值(叶子)。假设已有路径模式为{A;B;C},如果Offset输入端输入语句为{0;0;0},则不会发生任何偏移。如果为{0;0;+1}则路径C项正向偏移1位,为负则反向偏移,偏移大小可以调整;除了路径偏移,项值偏移使用小括号,例如{0;0;+1}(+1),为路径正向偏移1位时,项值也偏移1位,这同于List->Shift List组件的方法。Wrap Paths和Wrap Items可以通过输入布尔值确定是否首尾衔接(可以想象为一个平面和一个球面的差异,即有界和无界的差异);
#21. Relative Items - 基本逻辑同Relative Item,在输入端Tree(或Tree A、Tree B)输入 Tree 型数据,输入端Offest配置变化模式,对应模式输出两组数据Item A和Item B。关键是理解Offset输入语法。Tree 型数据包括分支(branch)和项值索引(idex),如{0;0}(0),那么输出为两组数据关系的模式{±n;±n}(±n)就是配置两组输出数据的分支和项值索引,如果模式配置为{0;+1}(+1),则可以理解为如果Item A的分支索引为{0;0}(0),那么对应的Item B为{0;1}(1),分支和索引均依次递增,依此类推。又如{0;0}(+1),即Item A的分支索引为{0;0}(0),那么Item B的分支索引为{0;0}(1),即分支不变,但同一分支的列表(项值)索引依次加1。分支和索引也可以用负整数值,例如{0;+1}(-1),可以理解为反向过程,此时Item A的分支索引为{0;0}(1),而Item B的分支索引为{0;1}(0)。递增(+)的情况下可以省略加号;
保留了对 Relative_Item 和 Relative Items 两次略有差异的解释,方便读者更好的理解。
#22. Tree Branch - 根据输入的路径名提取数据对应的路径及其项值;
_#23. Tree Item - 根据输入的路径名和项值索引值提取数据对应路径下的项值;

图 1.3.1-56 代码段(Tree)-39与结果
🍋🟩代码段-练习-40: ( )
图 1.3.1-57这个简单代码段练习主要实践Relative Items组件提供的数据组织方法。

图 1.3.1-57 代码段(Tree)-40与结果
F组:
#24. Construct Path - 将列表转化为路径名;
#25. Deconstruct Path - 将路径分解为列表数据;
#26. Path Compare - 与输入端Mask提供的掩码路径比较,判断路径是否与之对应,如果一致则输出 True,否则为 False;
#27. Replace Paths - 将输入端Search提供的路径替换为输入端Replace提供的路径,项值保持不变。
🍋🟩代码段-练习-41: ( )
设计上如果增加一点点变化,总会让一成不变的形式灵动起来。让形式富有变化的一种途径是随机数值的应用,例如Random、Jitter、Random Reduce、Populate 2D、Populate 3D、Populate Geometry等;另一种方式是用磁场建立起具有一定变化韵律的向量领域,可以变化空间对象的尺寸、位置偏移、方向和大小,或者用作变化任何类型几何空间形态的输入参数,都会产生富有变化的形态或空间。
设计的空间形体通常由点线控制,进而生成面,最后构建体。由线放样成体的方法,均可以在Surface->Freeform面板下找到合适的方法。有时对线放样需要输入一些条件参数,对经常用到的放样手段依旧用Cluster方法封装,例如本例中的方形放样。

图 1.3.1-58 代码段(Tree)-41与结果
4)Text(字符串)
A组:
#1. Character - 将字符串转换为列表;
#2. Concatenate - 连接多个输入的字符串;
#3. Text Join - 使用分隔符连接字符串列表;
#4. Text Length - 计算字符串长度;
#5. Text Split - 按分隔符切分字符串;
B组:
#6. Format - 使用输入端标注有序号的字符串替换Format输入端字符串对应序号位置,实现字符串格式化;
#7. Text Case - 将输入字符串转换为全部大写和全部小写;
#8. Text Fragment - 根据输入的字符串起始位置和提取长度提取字符串;
#9. Text Trim - 去除两侧(不包括内部)空白的字符串;
C组:
#10. Match Text - 判断字符串是否符合Patten扩展通配符或者RegEx正则表达式;
#11. Replace Text - 使用输入端Replace的字符串替换输入端Find字符串;
#12. Sort Text - 按照字母顺序排序字符串;
#13. Text Distance - 计算两个文本片段之间的Levenshtein Distance⑨,即相似度;
🍋🟩代码段-练习-42: ( )
图 1.3.1-59这个乌托邦式的设计概念练习,一方面,基于前文的人参考定位封装组件增加了人朝向参考线,修改为人参考定位-方向(图 1.3.1-60)。这里封装组件是要求输入端人mesh中增加一根直线,标识出人朝向;再者,是基于人体及其朝向构建空间的逻辑模块,空间立方体+人尺度封装组件(图 1.3.1-61),配合人参考定位-方向输出项,配置空间深度、宽度建立空间;最后一方面,是建立简单截面封装组件(图 1.3.1-62),演示提取剖面的方法。一般几何体与平面相交可以用Brep | Plane组件提取出截面线,但是,如果是点对象,交点并不能很好的表述点对象的空间分布,因此,这里是用截面截取出一段空间,将落于这个空间中的点投影到截面上进行表达。
空间的随机点增加了磁场的影响,从截面中可以清晰的观察出点具有磁力线的运动动势。最终的代码段如图 1.3.1-63。

图 1.3.1-59 代码段(文本)-42的结果

图 1.3.1-60 人参考定位-方向 封装组件 |

图 1.3.1-61 空间立方体+人尺度 封装组件 |
图 1.3.1-62 简单截面 封装组件 |

图 1.3.1-63 代码段(文本)-42
🍋🟩代码段-练习-43: ( )
图 1.3.1-64与练习-33 CSV 格式 POI 数据处理类似,通过Read File组件读取 CSV 格式的数据,不过此时用到的数据是Array of Things,AoT⑩中传感器在芝加哥市区布置的点位数据,数据中包括经纬度、点位ID、地址、数据获取起止时间等信息。图 1.3.1-65 练习所关注的重点是 GH 对文本数据处理的技术,这包括Text Split组件切分提取数据,Text Trim组件移除字符串首尾潜在的空白字符,用Characters组件转换字符为列表,通过Math Text组件匹配字符串寻找字符,Replace Text组件替换字符修改时间格式,Text Length组件计算字符串长度,辅助移除异常字符串等字符串处理任务。
注意,练习里用经纬度值直接构建空间分布点,实际上要进行坐标投影,转换为米制等长度单位。

图 1.3.1-64 代码段(文本)-43的结果

图 1.3.1-65 代码段(文本)-43
5)Sequence(序列)
A组:
#1. Cull Index - 根据输入的索引值剔除列表中对应的项值;
#2. Cull Nth - 每隔输入端Cull Frequency指定的数值,移除该对应的项值,或者理解为按照Cull Frequency指定的数值循环切分列表,移除各自末尾项;
#3. Cull Pattern - 输入端CUll Pattern为布尔值,True 时保留,Flase 时移除;
#4. Random Reduce - 输入端Reduction为移除的数量,Seed为随机种子,生成不同的移除结果;
B组:
#5. Char Sequence - 输入端Count指定数量,Char Pool输入端给定字符集,默认为字母表(alphabet),创建一个文本字符序列。输入端Format可选配置格式;
#6. Duplicate Data - 根据指定的Number输入端数值复制列表,Order输入端可以指定复制项值放置的位置,是逐个项值复制后放置于该项值之后循环,还是整个列表复制后放置于原列表末尾循环;
#7. Fibonacci - 建立Fibanacci (斐波纳契)数列,后一个项值是紧随前两个项值之和;
#8. Range - 在指定区间范围内,等分区间获取数列;
#9. Repeat Data - 根据输入端Length指定的复制列表长度进行复制,大于列表长度则循环复制;
#10. Sequence - 由Notation输入端配置规则,例如默认为[N-1] + [N-2],其中N为当前索引,例如为3,则该位置的值为索引为2-1=1和2-2=0对应项值之和。Initial输入端就是开始指定的项值。规则可以包括条件,例如[N-1] + If([N-1]%2=0,1,9);
#11. Series - 由初始值Start,步幅值Step和数量Count建立一个等差数列;
#12. Stack Data - 将输入端Stack指定的数值作为Data输入端列表各项值复制的次数,并循环该数值;
C组:
#13. Jitter - 振荡是将列表中的数据随机变化位置,获得新的数据顺序,项值不变;
#14. Random - 生成指定区间内指定数量的随机数。图标右键Iteger Numbers项可以设置是否为整数;
🍋🟩代码段-练习-44: ( )
达到同一个目的,逻辑构建的途径有很多,例如练习中 A 和 B,都是为了建立一个随机渐变的图形效果,不过 A 中使用了Random Reduce组件配合;而 B 中使用了Jitter和Cull Index组件配合。二者的核心逻辑保持了一致,是将矩形内单元格划分为几份,逐一顺序的,增加剔除单元格的数量产生渐变的形式。同时,注意到给出的矩形不是水平垂直的,这里想表述逻辑构建的一个准则是,当控制线发生旋转偏移时,最终结果应不会发生错乱,如图1.3.1-66和图 1.3.1-67。

图 1.3.1-66 代码段(序列)-44的结果

图 1.3.1-67 代码段(序列)-44
🍋🟩代码段-练习-45: ( )
图 1.3.1-68的练习仅是展示了5个序列组件生成数据的规律。
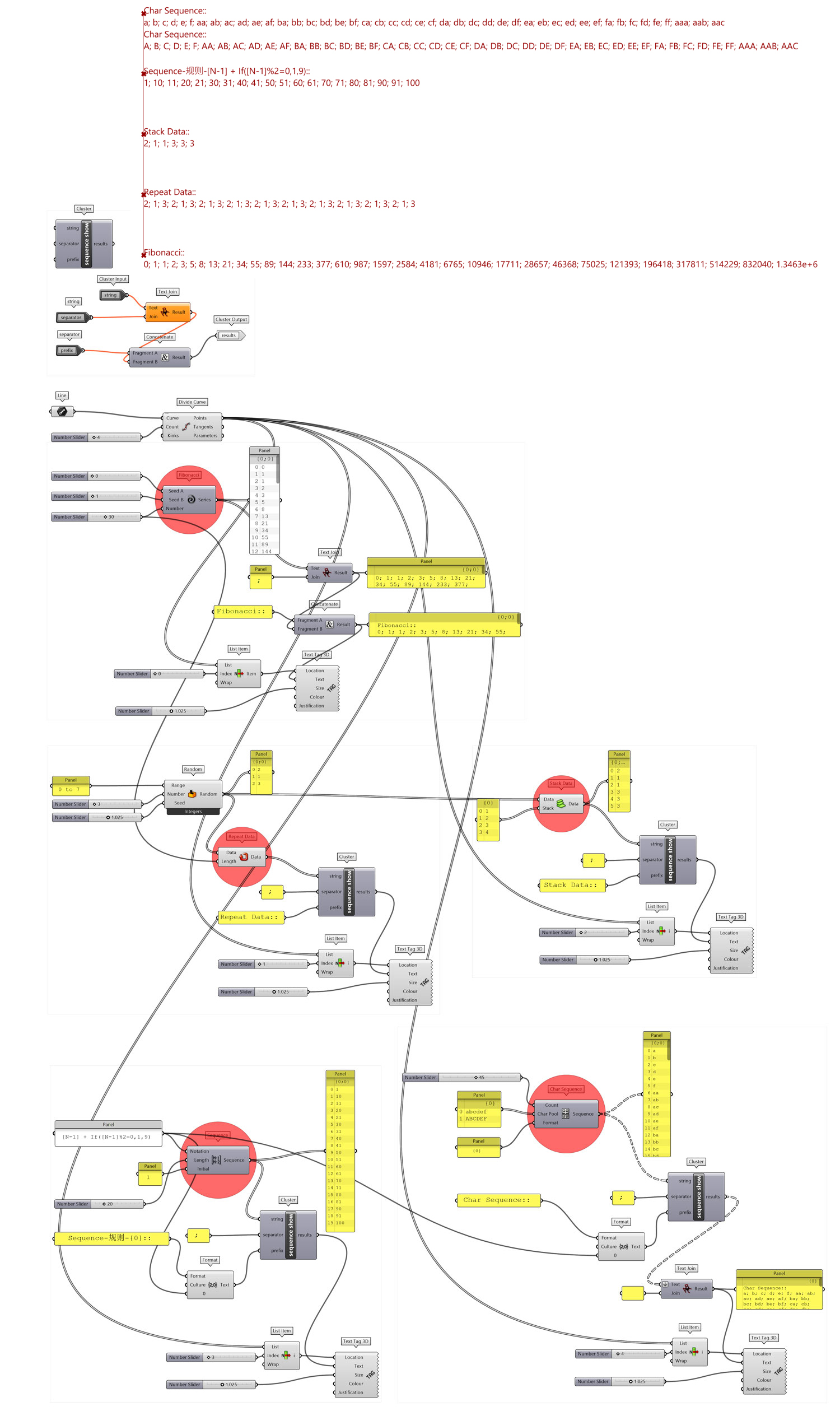
图 1.3.1-68 代码段(序列)-45与结果
练习题
🌟练习-A.
完成要求(图 1.3.1-69):
- 通过调整参数可以获得多个比较方案(结果);
- 支撑柱在地面和天花板之间的位置可随机变化;
- 支撑柱圆截面数量随机,半径随机;
- 支撑柱竖向编织线可以旋转偏移(
Shift List); - 地面和天花板间距可调。

图 1.3.1-69 练习-A 结果图:动画

图 1.3.1-69 练习-A 结果图
🌟练习-B.
完成要求(图 1.3.1-70):
- 底层矩形平面,宽和长可调整;
- 建筑高度可调整;
- 内墙和外墙距离可调整;
- 两层墙的矩形孔洞,位置随机,孔洞宽高随机。

图 1.3.1-70 练习-B 结果图:动画

图 1.3.1-70 练习-B 结果图
🌟练习-C.
完成要求(图 1.3.1-71):
- 可以自由控制桥体跨度;
- 支撑桁架的杆件数量可控制;
- 支撑桁架的结构随机生成;
- 可以控制桁架开始、结束端,以及中间截面的高度。

图 1.3.1-71 练习-B 结果图:动画
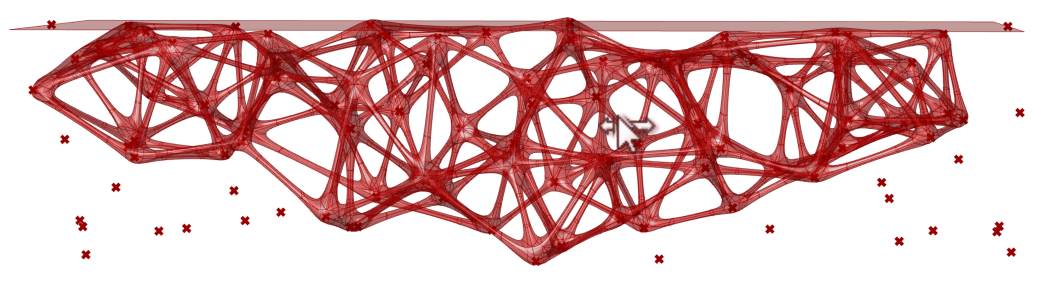
图 1.3.1-71 练习-B 结果图
注释(Notes):
① Numpy,是 Python 编程语言的一个库,具有对大型多维数组和矩阵的支持,及对这些数组进行操作的大量高级数学函数集合。(https://numpy.org/)。
② Pandas,是为 Python 编程语言编写用于数据操作和分析的软件库,提供了用于操作数据框(DataFrame)(即数据表、属性表、面板数据(panel data)等)和序列(Series)的数据结构和操作(https://pandas.pydata.org/)。
③ NetLogo,是基于智能体建模(agent-based modeling)的一种编程语言和集成开发环境(IDE),即多代理可编程建模环境(https://ccl.northwestern.edu/netlogo/)。
④ QGIS,是一个免费开源的地理信息系统(geographic information system,GIS)软件,支持查看、编辑、打印、各种数据格式的地理空间数据分析任务(https://www.qgis.org/)。
⑤ food4rhino,为 Rhino 3D 软件的扩展插件,包括大量 GH 的扩展组件()。
⑥ VisualARQ,GH 的 BIM 扩展插件,支持从三维模型生成所有项目文档信息,例如平面图、剖面图、立面图,及建筑表皮、尺寸、组件和数量统计等(https://www.food4rhino.com/en/app/visualarq)。
⑦ SMPL,人体姿态估计模型(https://smpl.is.tue.mpg.de/index.html)。
⑧ 人体姿态与场景交互(https://arxiv.org/abs/2302.00883)。
⑨ Levenshtein Distance,在信息论、语言学和计算机科学中,Levenshtein 距离是基于字符串度量测量两个序列之间的差异。两个单词之间的 Levenshtein 距离是将一个单词变为另一个单词所需的单字符编辑(插入、删除或替换)的最小数量(https://en.wikipedia.org/wiki/Levenshtein_distance)。
⑩ Array of Things,城市环境传感器,收集城市环境、基础设施和活动的实时数据供研究和公共使用(https://arrayofthings.github.io/)。