4. 数据结构
🤖 作者:包瑞清(richie bao): lastmod: 2024-10-21T23:40:03+08:00
4.1 数据结构
数据结构是计算机科学中的一个核心概念,是以特定方式组织、管理和存储数据的集合,以便高效地访问和修改,是程序设计的基础。不同的数据结构具有不同的特性和用途,选择合适的数据结构可以提高程序的性能和可维护性。在实际的应用中,了解不同数据结构的特性和使用场景,可以帮助开发者做出更有效的设计决策。下表列出了常见数据结构的解释及对应编程语言的实现方法。
| 数据结构 | 解释 | Python | C | C++ | C# |
|---|---|---|---|---|---|
| 数组(Array) | 数组是一种固定大小的线性数据结构,其中的元素在内存中顺序存储。支持随机访问,通过索引可以直接访问任何元素。但其大小在其创建时便固定,不支持动态调整。数组适用于存储图像像素、数据表等需要快速访问的场景 | 动态数组(list) |
固定大小(使用数组) | STL 中的 vector |
数组(可变大小的 List) |
| 链表(Linked List) | 链表是一种动态大小的线性数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针。支持动态大小,插入和删除操作具有较高的效率。不支持随机访问,访问元素需要从头遍历。适合于实现队列、栈等频繁插入和删除元素的场景 | 使用自定义类实现 | 通过定义结构体和函数实现 | STL 中的 list |
使用自定义类实现或 LinkedList |
| 栈(Stack) | 栈是一种后进先出(last-in first-out,LIFO)的线性数据结构,只允许在一端进行插入和删除的操作。其只有一个出口(栈顶),先进后出。常用操作包括压栈(push)、弹栈(pop)和查看栈顶元素(peek)。适用于函数调用管理、表达式求值和回溯算法等 | 使用列表或 collections.deque |
通过定义结构体和函数实现 | STL 中的 stack |
使用 Stack<T> |
| 队列(Queue) | 队列是一种先进先出(first-in first-out,FIFO)的线性数据结构,允许在一端插入元素(队尾)并在另一端(队头)删除元素。元素按照插入顺序处理,常用操作包括入队(enqueue)、出队(dequeue)和查看对头元素。适用于任务调度、异步数据处理等场景 | 使用 collections.deque |
通过定义结构体和函数实现 | STL 中的 queue |
使用 Queue<T> |
| 哈希表(Hash Table) | 哈希表是一种基于键值对的非线性数据结构,使用哈希函数将键映射到特定的数组索引。能够提供快速的查找、插入和删除操作。适用于实现字典、缓存和数据库索引等场景 | 字典(dict) |
通过定义结构体和函数实现 | STL 中的 unordered_map |
使用 Dictionary<TKey, TValue> |
| 树(Tree) | 树是一种非线性数据结构,由节点组成,具有层级关系。每个节点有零个或多个子节点,根节点是树的顶层节点。支持层级存储和快速查找。二叉树是最常见的树结构,其每个节点最多有两个子节点。适用于表示层级结构,如文件系统、组织结构等场景 | 自定义类实现,或者使用anytree、treelib等 Python 库 |
通过定义结构体和函数实现 | 使用 STL 的容器组合来实现树(自定义类) | 自定义类或使用 SortedSet、SortedDictionary |
| 图(Graph) | 图是一种由节点(顶点)和边组成的非线性数据结构,边表示节点直接的关系。可以是有向图(边有方向)或无向图(边无方向)。有邻接矩阵和邻接列表等表示方式。适用于网络结构,如社交网络、交通网络等场景,可以解决最短路径、连通性等问题 | 自定义类实现,或者使用networkx、igraph等 Python 库 |
通过定义结构体和函数实现 | 使用 STL 容器的 vector、list 或 unordered_map 等实现(自定义类) |
自定义类实现,或者使用QuickGraph、GraphX等库 |
| 集合(Set) | 集合是一种无序且元素不重复的集合。支持基本的集合运算,如并集、交集和差集等。可以使用哈希表实现,提供快速查找。适用于去重、统计和数学运算等场景 | 集合(set) |
通过定义结构体和函数实现 | STL 中的 unordered_set |
使用HashSet<T> |
4.2 C/C++ 和 C# 的数组(Array)
为了使一个变量不只是仅存储一个单一数据项,而是能够存储多个数据项,其中一种方式是创建数组(Array)。C/C++ 创建数组方式基本保持一致,C# 则有较大不同,如下比较表格:
| C/C++ | C# | |
|---|---|---|
| 语法 | data-type array-name [number-of-elements] |
data-type[] array-name = new data-type[number-of-elements] |
| 声明数组 | int myArray[5]; |
int[] myArray = new int[5]; 或int[] myArray;myArray=new int[5]; |
| 声明数组后赋值 | myArray[2]=3; |
myArray[2]=3; |
| 声明数组时赋值 | int myArray[5] = { 1,2,3,4,5 }; |
int[] myArray = new int[5]{ 1, 2, 3, 4, 5 }; |
| 声明和初始化数组时不指定数组大小 | int myArray[] = { 1,2,3,4,5 }; |
int[] myArray = { 1, 2, 3, 4, 5 }; |
| 多维数组(矩阵) | int myMatrix[3][3] = { {1, 2, 3},{4, 5, 6},{7, 8, 9} }; |
int[,] myMatrix =new int[3,3]{{1,2,3},{4,5,6},{7,8,9}}; |
| 访问多维数组 | int valOFmatrix = myMatrix[1][2]; |
int valOFmatrix = myMatrix[1, 2]; |
如果以 C 的数组为参照,C++ 通过引入头文件#include <array>和#include <vector>,还可以使用std::array<int, 5>和std::vector<int>来声明数组,其中Vector向量属于 C++ 的标准模板库(Standard Template Library,STL)中一种自定义的数据类型,可以认为是数组的增强版;而 C# 内置的数组类型 Array 类,具有丰富的属性和方法。首先通过下述表格中的代码示例比较使用 C 系列语言基础数组的使用方法。
| 数据结构 | C | C++ | C# |
|---|---|---|---|
| 数组(Array) |
|
将 C 中使用数组的试验代码迁移至 C++ 中,其主要区别为:
C 和 C++ 除了上述主要区别外,代码基本相同。
|
将 C 中使用数组的试验代码迁移至 C# 中,其主要区别为:
在定义数组打印的
|
4.3 C++ 的容器[Container]
C++ 中的容器(Container)是一个持有对象的对象,用于存储其他对象(作为容器的元素)的集合。它们作为类模板(class templates)实现,支持多种灵活的元素类型。容器管理其元素的存储空间,并提供成员函数(member function)以直接的方式,或者迭代器(其引用对象与指针的属性类似)访问元素。容器复现了编程中常用的结构,如动态数组(vector)、队列(queue)、栈(stack)、堆(priority_queue)、链表(list)、树(set)和关联数组(map)等。许多容器有多个共同的成员函数,并共享某些功能。栈(stack)、队列(queue)和优先队列(priority_queue)作为容器适配器(Container adaptors)实现。容器适配器不是完整的容器类,而是提供特定接口的类,依赖于某个容器类(如deque或list)的对象处理元素。底层容器以一种方式被封装,以便通过容器适配器的成员独立于所使用的底层容器类来访问其元素。
容器类模板(Container class templates)可以归类如下表,
| 分类 | 容器 | 说明 |
|---|---|---|
| 序列式容器(Sequence containers) | 数组(array) |
静态连续数组 Array class |
向量(vector) |
动态连续数组 Vector | |
双端队列(deque) |
双端队列 Double ended queue | |
单向链表(forward_list) |
单链表 Forward list | |
链表(list) |
双链表 List | |
| 关联式容器(Associative containers) | 集合(set) |
唯一键的集合,并按键排序 Set |
映射(map) |
键值对的集合,按键排序,键唯一 Map | |
多重集合(multiset) |
键的集合,按键排序,元素可不唯一 Multiple-key set | |
多重映射(multimap) |
键值对的集合,按键排序,键值可不唯一 Multiple-key map | |
| 无序关联式容器(Unordered associative containers) | 无序集合(unordered_set) |
唯一键的集合,按键散列(哈希表) Unordered Set |
无序映射(unordered_map) |
键值对的集合,按键散列,键是唯一的 Unordered Map | |
无序多重集合(unordered_multiset) |
键的集合,按键散列,元素可不唯一 Unordered Multiset | |
无序多重映射(unordered_multimap) |
键值对的集合,按键散列,键值可不唯一 Unordered Multimap | |
| 容器适配器(Container adaptors) | 栈(stack) |
后进先出数据结构(last-in first-out) LIFO stack |
队列(queue) |
先进先出数据结构(first-in first-out) FIFO queue | |
优先队列(priority_queue) |
最高优先出 Priority queue |
选择特定需求所用的容器类型(图 4.1,4.2)通常不仅依赖于容器所提供的功能,还与其某些成员的效率(时间/空间复杂度[附2])有关。这在序列式容器中表现明显,它们在插入/删除元素和访问元素之间提供了不同的复杂度权衡。
图 4.1 序列式容器和关联式容器选择流程图,改绘自参考文献[2] Containers in C++ STL (Standard Template Library)(https://www.geeksforgeeks.org/containers-cpp-stl/)
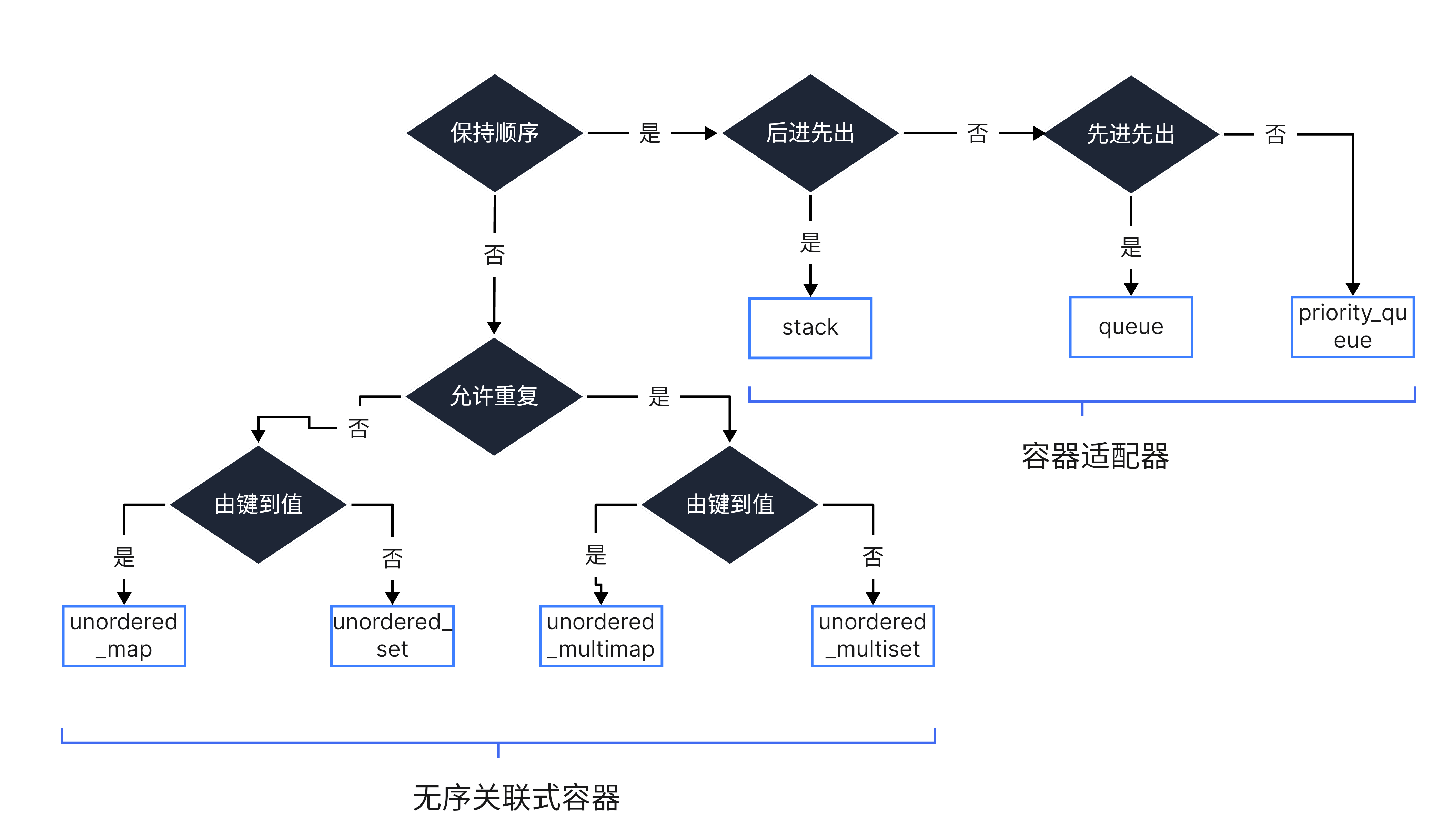
图 4.2 无序关联式容器和容器适配器选择流程图,改绘自参考文献[2] Containers in C++ STL (Standard Template Library)(https://www.geeksforgeeks.org/containers-cpp-stl/)
4.3.1 序列式容器
4.3.1.1 Vector
向量(Vector) 是一个序列式容器(sequence containers),表示可以改变大小的数组(Array)。与数组一样,向量的元素(elements)存储在连续的内存位置,因此可以使用指向其元素的常规指针偏移量来访问这些元素,访问效率与数组相同。但是,与数组不同的是向量的大小可以动态变化,容器会自动管理其存储。向量使用动态分配的数组来存储元素,当需要增加大小以插入新元素时,可能需要重新分配这个数组,意味着分配一个新数组并将所有元素移动过去。这是一项相对耗时的操作,因此向量不会在每次添加元素时都进行重新分配。相反,向量容器通常会预分配一些额外的存储空间,以适应未来可能的增长,因此其实际的容量(capacity)可能大于所需的元素存储空间(即其大小,size)。该库实现了不同的增长策略,以在内存使用和重新分配之间保持平衡。虽然向量比数组消耗更多内存,但换来了更有效的存储管理和动态增长能力。与其他动态序列式容器相比(如双端队列(deques)、链表(lists)和前向列表(forward lists)),向量在访问其元素时效率更高,并且在末尾添加和删除元素时性能也相对较好。然而,在向量的中间位置进行插入或删除操作时,其性能要逊于其他位置,且迭代器(iterators)和引用(references)的稳定性不如链表和前向链表。
下述示例展示了建立向量、添加元素、访问元素、迭代向量、移除元素、返回向量大小和容量,及清除向量和检查向量是否为空等常用方法。初始化一个向量时,可以传入一个列表(数组)给向量构造函数以创建指定元素的一个向量,其语法为std::vector<dataType> name({ value1, value2, value3 ....}); ;或者指定向量的大小,给定一个值来初始化向量的每一个元素,其语法为std::vector<dataType> name(size, value); ;亦可仅指定向量大小,则填充值默认为0,其语法为std::vector<dataType> name(size); ;也可以初始化一个其他向量的复制对象,其语法为std::vector<dataType> name(other_vec);。
#include <iostream>
#include <vector>
#include <string>
#include <format>
template<typename T>
void printVector(const std::vector<T>& vec,std::string varname) {
std::cout << varname << " = {";
/*
for (const auto& element : vec) {
std::cout << element << ",";
}
*/
for (size_t i = 0; i < vec.size(); i++) {
std::cout << vec[i];
if (i != vec.size() - 1) {
std::cout << ", ";
}
}
std::cout<<"}" << std::endl;
}
int main() {
// 建立 vector
std::vector<int> vec; // 建立一个空的 vector
std::vector<int> vec2(5); // 建立一个长度为 5 的 vector,初始化值默认为 0
std::vector<int> vec3(5, 10); // 建立一个长度为 5 的 vector,初始化值为 10
// 用定义的 printVector() 函数打印 vector
printVector(vec,"vec");
printVector(vec2,"vec2");
printVector(vec3,"vec3");
// 使用 push_back() 向 vector 对象添加元素
vec.push_back(1);
vec.push_back(2);
vec.push_back(3);
vec.push_back(4);
printVector(vec,"vec");
vec2.push_back(7);
printVector(vec2, "vec2");
// 访问元素
std::cout << std::format("Using index operator []: {}; or the at() method: {}", vec[1], vec.at(1))<<std::endl;
// 迭代 vector——使用 range-based for loop 方法
for (int value : vec) {
std::cout << value << " ";
}
std::cout << std::endl;
// 迭代 vector——使用迭代器(iterator)
for (std::vector<int>::iterator it = vec.begin();it != vec.end();++it){ // 可用 auto 替代 std::vector<int>::iterator
std::cout << *it << " ";
}
std::cout << std::endl;
// 迭代 vector——使用逆向迭代器(reverse_iterator)
for (std::vector<int>::reverse_iterator it = vec.rbegin(); it != vec.rend(); it++) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 移除元素——使用 pop_back()方法移除最后一个元素
vec.pop_back();
printVector(vec, "vec");
// 移除元素——使用 erase()方法移除指定的元素
vec.erase(vec.begin() + 1);
printVector(vec, "vec");
// size() 返回元素的数量
std::cout << std::format("vec size = {}", vec.size()) << std::endl;
// capacity() 返回 vector 容器在需要调整大小之前可以容纳的元素数量
std::cout << std::format("vec capacity = {}", vec.capacity()) << std::endl;
// clear() 从 vector 容器中移除所有元素
vec.clear();
// empty() 检查 vector 是否为空
std::cout << std::format("vec is empty = {}", vec.empty()) << std::endl;
return 0;
}
🡮
vec = {}
vec2 = {0, 0, 0, 0, 0}
vec3 = {10, 10, 10, 10, 10}
vec = {1, 2, 3, 4}
vec2 = {0, 0, 0, 0, 0, 7}
Using index operator []: 2; or the at() method: 2
1 2 3 4
1 2 3 4
4 3 2 1
vec = {1, 2, 3}
vec = {1, 3}
vec size = 2
vec capacity = 4
vec is empty = true
size_t 是 C++ 中用于表示对象大小或数组索引的一种无符号整数类型,其通常用于表示对象的大小(如内存分配的字节数)和容器的元素数量(如std::vector 的大小)。由于size_t是无符号类型,能有效的表示从 0 开始的数量,避免负数带来的潜在问题。size_t的大小和范围取决于系统架构(32 位或 64 位),这使得它在不同平台上具有良好的兼容性。
将&用于函数参数时,表示传递参数的引用。这种方式允许函数直接操作传入的变量,而不是对其进行复制。使用引用参数可以提高效率,尤其在处理大型数据结构时。又如下述示例:
#include <iostream>
void modify(int& num) {
num += 10;
std::cout << "Executed function modify().\n";
}
void modifyC(int num) {
num += 10;
std::cout << "Executed function modifyC().\n";
}
int main() {
int value = 5;
modify(value);
std::cout << "Modified value: " << value << std::endl;
modifyC(value);
std::cout << "Modified value: " << value << std::endl;
return 0;
}
🡮
Executed function modify().
Modified value: 15
Executed function modifyC().
Modified value: 15
将const关键字用于函数参数,是以确保在函数内部不修改该参数,其可用于基础数据类型和应用类型。例如修改上述代码modify(int& num)函数传入的参数为modify(const int& num),则会提示错误信息E0137 expression must be a modifiable lvalue和C3892 'num': you cannot assign to a variable that is const。
“Range-based for loop” 可以直接迭代容器中的所有元素,其语法可表示为for (data-type range_declaration : range_expression ),例如,
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec = { 0,1,2,3,4,5 };
for (auto i : vec)
std::cout << i << " ";
std::cout << std::endl;
return 0;
}
🡮
0 1 2 3 4 5
std::vector常用的成员函数如下表:
| 分类 | 序号 | 成员函数 | 解释 | 示例 |
|---|---|---|---|---|
|
迭代器(Iterators) |
1 |
|
返回一个指向向量中第1个元素的迭代器 |
|
| 2 |
|
返回一个指向向量中最后一个元素下一个位置的迭代器 |
||
| 3 |
|
返回一个指向向量最后一个元素的反向迭代器(反向开始)。它从最后一个元素移动到第一个元素 |
||
| 4 |
|
返回一个指向向量中第一个元素前一个位置(视为反向结束)的反向迭代器 |
||
| 5 |
|
返回一个指向向量中第一个元素的常量迭代器(constant iterator) |
||
| 6 |
|
返回一个指向向量中最后一个元素下一个位置的常量迭代器 |
||
| 7 |
|
返回一个指向向量最后一个元素的常量反向迭代器(反向开始)。它从最后一个元素移动到第一个元素 |
||
| 8 |
|
返回一个指向向量中第一个元素前一个位置(视为反向结束)的常量反向迭代器 |
||
|
容量(Capacity) |
1 |
|
返回向量中元素的个数 |
|
| 2 |
|
返回向量容器所能容纳的最大元素数 | ||
| 3 |
|
返回当前分配给向量容器存储空间的大小,以元素数表示 | ||
| 4 |
|
调整容器大小,使其包含 n 个元素 | ||
| 5 |
|
判断容器是否为空 |
||
| 6 |
|
减少容器的容量以适应其大小,并消除超出容量的所有元素 | ||
|
7 |
|
使得向量容器容量至少足以容纳 n 个元素 |
||
| 元素访问(Element access) | 1 |
|
返回向量中于 g 位置元素的引用 |
|
| 2 |
|
返回向量中索引为 idx 所指的元素,如果 idx 越界则抛出异常 out_of_range |
||
| 3 |
|
返回向量中第一个元素的引用 | ||
| 4 |
|
返回向量中最后一个元素的引用 | ||
| 5 |
|
返回一个直接指向向量内用于存储其所拥有元素的内存数组指针 | ||
|
编辑向量(Modifiers) |
1 |
|
替换向量中的元素 |
|
| 2 |
|
在向量最后添加一个元素 | ||
| 3 |
|
移除向量中的最后一个元素 | ||
| 4 |
|
在指定位置的元素之前插入一个新元素 | ||
| 5 |
|
用于从指定位置或给定的区间内删除容器中的元素 | ||
| 6 |
|
相同数据类型的两个向量内容互换,其大小可能不同 | ||
| 7 |
|
移除向量容器中的所有元素 | ||
| 8 |
|
指定位置插入元素来扩展容器 | ||
| 9 |
|
在向量容器的末尾插入一个新元素 |
对向量各种操作的时间复杂度(Time Complexity)[附2]为:
- 随机访问:常数(constant)阶 O(1)
- 在末尾插入或移除元素:常数阶 O(1)
- 插入或移除元素:与到向量末端的距离呈线性关系 O(N)
- 计算向量大小:常数阶 O(1)
- 调整向量大小:线性阶 O(N)
4.3.1.2 List
链表(List)是 C++ 中的一种序列式容器,允许在序列中的任意位置进行O(1)常量时间的插入和删除操作。并支持双向迭代。链表容器实现为双向链表,可以在不相关的存储位置中存储每个独立的元素。元素的顺序通过链接维持,每个元素包含一个指向前一个元素的链接和一个指向下一个元素的链接。链表与前向链表(forward_list)非常相似,主要区别在于前向链表是单链表,只能进行单向迭代,因而在存储空间和效率上略优。与 STL(标准模板库)中的其他序列式容器(array、vector 和 deque 等)相比,链表在任意位置插入、删除以及移动已获得迭代器的元素方面通常表现的更佳,因此在需要大量使用迭代器的算法(如排序算法)中具有优势。而链表和前向链表主要缺点在于无法通过位置直接访问元素。如要访问链表中的第6个元素,必须从已知位置(开始或末尾)迭代到该位置,这会随着距离线性增加执行时间。另外,链表还需要额外的内存来存储每个元素的链接信息。
下述示例包含了链表的常用方法。在向量部分定义了一个函数printVector()来辅助打印向量,该函数传入的参数为std::vector<T>& vec,只能处理向量打印的任务。为了能够通用打印容器包含的vector、list、deque、set等数据结构,定义printContainer()函数实现。示例中包括了声明链表、声明并初始化链表、访问元素、迭代链表、移除(指定位置)元素、(指定位置)插入元素、清空链表、检查链表是否为空、排序和反转链表等操作。
#include <iostream>
#include <list>
#include <format>
template <typename Container>
void printContainer(const Container& container) {
std::cout << "{";
for (auto it = container.begin(); it != container.end(); ++it) {
std::cout << *it;
if (std::next(it) != container.end()) {
std::cout << ",";
}
}
std::cout << "}" << std::endl;
}
int main() {
// 声明一个链表
std::list<int> myListA;
// 用 push_front() 和 push_back() 在首尾追加元素
myListA.push_front(7);
myListA.push_back(9);
printContainer(myListA);
// 声明并初始化一个链表
std::list<int> myListB = { 2,3,1,5,4 };
printContainer(myListB);
std::list<int> myListC { 6,7,8,9,10 };
printContainer(myListC);
std::list<int> myListD({ 11,12,13,14,15 });
printContainer(myListD);
// 访问元素。因为链表的元素不是连续存储在内存中,不能使用 [] 运算符随机访问元素,需要使用迭代器或 front() 和 back() 等方法
int firstElement = myListB.front();
int lastElement = myListB.back();
std::cout << std::format("first element = {}; last element = {}\n", firstElement, lastElement);
// 迭代一个链表——Range-based for loop
for (int num : myListD) {
std::cout << num << ' ';
}
std::cout << std::endl;
// 迭代一个链表——使用迭代器
for (std::list<int>::iterator it = myListC.begin(); it != myListC.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 移除元素
myListD.pop_front();
myListD.pop_back();
printContainer(myListD);
// 使用 erase()方法,配合迭代器移除指定位置的元素
auto it = myListC.begin();
std::advance(it, 2); // 移动迭代器到指定位置,这里为开始位置后的第2位
myListC.erase(it);
printContainer(myListC);
// 指定位置插入元素
auto it2 = myListC.end();
std::advance(it2, -2); // 用 std::advance()传入负数反向移动迭代器
myListC.insert(it2, 8);
printContainer(myListC);
// 清空链表,即移除所有元素
myListC.clear();
// 检查列表是否为空
if (myListC.empty())
std::cout << "myListC is empty." << std::endl;
// 排序和反转链表
myListB.sort();
printContainer(myListB);
myListB.reverse();
printContainer(myListB);
return 0;
}
🡮
{7,9}
{2,3,1,5,4}
{6,7,8,9,10}
{11,12,13,14,15}
first element = 2; last element = 4
11 12 13 14 15
6 7 8 9 10
{12,13,14}
{6,7,9,10}
{6,7,8,9,10}
myListC is empty.
{1,2,3,4,5}
{5,4,3,2,1}
std::list 成员函数如下表:
| 序号 | 函数 | 解释 |
|---|---|---|
| 1 | front() |
返回链表中第一个元素值 |
| 2 | back() |
返回链表中最后一个元素值 |
| 3 | push_front() |
向链表开始位置追加一个新元素 |
| 4 | push_back() |
向链表末端追加一个新元素 |
| 5 | pop_front() |
移除链表的第一个元素,并且链表大小减少1 |
| 6 | pop_back() |
移除链表的最后一个元素,并且链表大小减少1 |
| 7 | begin() |
返回一个指向链表第一个元素的迭代器 |
| 8 | end() |
返回一个指向链表最后一个元素下一位置的迭代器 |
| 9 | rbegin()和rend() |
rbegin()返回一个指向链表最后一个元素的反向迭代器;rend()返回一个指向链表开始元素前一位置的反向迭代器 |
| 10 | cbegin()和cend() |
cbegin()返回一个指向链表中第一个元素的常量迭代器;cend() 返回一个指向链表中最后一个元素下一个位置的常量迭代器。常量迭代器仅用于读取数据,无法修改容器中的元素,因此可以在不改变数据的情况下对容器进行遍历,保证数据的安全性 |
| 11 | crbegin()和crend() |
crbegin() 返回一个指向链表最后一个元素的常量反向迭代器(反向开始);crend() 返回一个指向链表中第一个元素前一个位置(视为反向结束)的常量反向迭代器 |
| 12 | empty() |
判断链表是否为空 |
| 13 | insert() |
向链表中指定位置的元素之前插入新元素 |
| 14 | erase() |
从链表中移除单个元素或一个区间多个元素 |
| 15 | assign() |
通过替换当前元素并调整链表大小来向链表分配新元素 |
| 16 | remove_if() |
按特定条件移除链表中所有符合条件的元素 |
| 17 | reverse() |
反转链表 |
| 18 | size() |
返回链表中元素个数 |
| 19 | resize() |
调整链表容器大小 |
| 20 | sort() |
按递增顺序对链表进行排序 |
| 21 | max_size() |
返回链表容器可容纳的最大元素数 |
| 22 | unique() |
从链表中移除所有重复的连续元素 |
| 23 | emplace_front()和emplace_back() |
emplace_front()用于在链表的头部构造并插入一个元素。与 push_front() 不同的是,emplace_front() 可以直接传递构造函数所需的参数,从而在链表头部原地构造元素,减少临时对象的创建和拷贝;emplace_back() 用于在链表的尾部构造并插入一个元素 |
| 24 | emplace() |
用于在指定位置直接构造并插入一个元素。与 insert() 不同的是,emplace() 允许传递构造函数所需的参数,直接在目标位置原地构造对象,避免创建临时对象,进而提高效率 |
| 25 | clear() |
用于删除链表容器中的所有元素,从而使其大小为 0 |
| 26 | operator = |
此运算符用于通过替换现有内容为容器分配新内容,并根据新内容修改链表容器大小 |
| 27 | swap() |
用于互换一个链表与另一个链表的内容 |
| 28 | splice() |
用于将元素从一个链表转移到另一个列表 |
| 29 | merge() |
将两个排序的链表合并为一个 |
4.3.1.3 Deque
双端队列(double-ended queue,Deque)是一种可以在两端(队列的前端和后端)进行扩展或缩减,具有动态大小的序列式容器。不同库的双端队列实现方式可能不同,一般双端队列以某种形式的动态数组实现。然而在任何情况下,都可以通过随机访问迭代器直接访问各个元素,存储空间的扩展和缩减也由容器自动管理。因此双端队列的功能类似于向量(Vector),但在序列的开始和末尾插入或移除元素都能保持较高的效率。与向量不同的是,双端队列并不保证所有元素存储在连续的存储位置,因此通过偏移指针访问双端队列中的其他元素会导致未定义的行为。双端队列和向量都提供非常相似的接口(interface),可以用于相似的目的,但其内部实现方式大不相同:向量使用一个单独的数组,在扩展时需要偶尔重新分配空间;而双端队列的元素可以分散存储在不同的内存块中,容器内部会保存必要的信息,以便在常量时间(constant time)内直接访问任意元素,并通过迭代器提供统一的顺序接口。因此,双端队列的内部结构比向量要稍微复杂些,但在处理非常长的序列等情况下可以更有效的增长;在重新分配上也具有更明显的优势。
下述示例包含了双端队列的常用方法,有声明和初始化双端队列、添加元素、迭代双端队列、删除元素、访问元素、计算双端队列大小和判断是否为空等。
#include <iostream>
#include <deque>
#include <format>
template <typename Container>
void printContainer(const Container& container) {
std::cout << "{";
for (auto it = container.begin(); it != container.end(); ++it) {
std::cout << *it;
if (std::next(it) != container.end()) {
std::cout << ",";
}
}
std::cout << "}" << std::endl;
}
int main() {
// 声明双端队列
std::deque<int> myDequeA;
//声明并初始化双端队列
std::deque<int> myDequeB = { 1,2,3,4,5 };
// 指定大小和默认值声明并初始化双端队列
std::deque<int> myDequeC(5, 10);
// 向双端队列中添加元素
myDequeA.push_front(9);
myDequeA.push_back(7);
myDequeA.push_front(8);
myDequeA.push_back(6);
// 打印双端队列元素
printContainer(myDequeA);
printContainer(myDequeB);
printContainer(myDequeC);
// Range-based for loop 方法迭代双端队列
std::cout << "myDequeB element: ";
for (int element : myDequeB)
std::cout << element << " ";
std::cout << "\n";
// 移除双端队列开端和末端的元素
myDequeB.pop_front();
myDequeB.pop_back();
printContainer(myDequeB);
// 访问元素
int firstElementIdx = myDequeB[0];
int firstElementAt = myDequeB.at(0);
std::cout << std::format("Using idx: {}; Using at: {}", firstElementIdx, firstElementAt) << std::endl;
int frontElement = myDequeB.front();
int backElement = myDequeB.back();
std::cout << std::format("front(): {}; back(): {}", frontElement, backElement) << std::endl;
// 双端队列大小和是否为空
std::cout << "Size of myDequeB: " << myDequeB.size() << "\n";
std::cout << std::format("Is myDequeB empty ? {}\n", myDequeB.empty());
return 0;
}
🡮
{8,9,7,6}
{1,2,3,4,5}
{10,10,10,10,10}
myDequeB element: 1 2 3 4 5
{2,3,4}
Using idx: 2; Using at: 2
front(): 2; back(): 4
Size of myDequeB: 3
Is myDequeB empty ? false
双端队列执行各类操作的时间复杂度上,访问元素为O(1);在队列中间插入或移除元素为O(N);在开始或结束处插入或移除元素为O(1)。std:deque 的成员函数包括:
constructor)、(destructor)、operator=
Iterators(迭代器): begin()、end()、rbegin()、rend()、cbegin()、cend()、crbegin()、crend()
Capacity(容量): size()、max_size()、resize()、empty()、shrink_to_fit
Element access(元素访问):operator[]、at()、front()、 back()
Modifiers(修改器):assign()、push_back()、push_front()、pop_back()、pop_front()、insert()、erase()、swap()、clear() 、emplace()、emplace_front()、emplace_back()
4.3.2 关联式容器
4.3.2.1 Set 和 Multiset
集合(Set)是遵循特定顺序用于存储唯一元素的容器。在集合中,元素的值即是其标识(值本身是键(key),类型为 T),且每个值都必须唯一。集合中的元素类型是 const类型,无法修改,但可以插入或者从容器中移除。在集合内部,元素始终按照由其内部的比较对象(类型为Compare)决定的严格弱序标准排序(weak ordering criterion)。相较于 Unordered_set 容器,Set 容器在通过键访问单个元素时通常较慢,但其允许基于顺序直接遍历子集。集合通常由二叉搜索树(binary search trees)实现。
下述示例包含了集合的常用方法,有声明和初始化集合、迭代集合、查找元素、移除元素、检查集合大小、清空集合、检查集合是否为空、自定义排序、寻找不小于或者大于给定值集合中的第一个元素、合并两个集合,即比较集合等操作。
#include <iostream>
#include <set>
#include <format>
template <typename Container>
void printContainer(const Container& container) {
std::cout << "{";
for (auto it = container.begin(); it != container.end(); ++it) {
std::cout << *it;
if (std::next(it) != container.end()) {
std::cout << ",";
}
}
std::cout << "}" << std::endl;
}
int main() {
// 声明集合并插入元素
std::set<int> mySetA;
mySetA.insert(7);
mySetA.insert(3);
mySetA.insert(7); //重复的元素并不会被加入集合中
printContainer(mySetA);
// 声明并初始化集合
std::set<int> mySetB = { 1,2,3,4,5 };
printContainer(mySetB);
std::set<int> mySetC { 6,7,8,9,10 };
printContainer(mySetC);
std::set<int> mySetD({ 11,12,13,14,15 });
printContainer(mySetD);
// 迭代集合
for (auto it = mySetB.begin(); it != mySetB.end(); ++it) {
std::cout << *it << " ";
}
std::cout << "\n";
// range-based for loop 方法迭代集合
for (int x : mySetC) {
std::cout << x << " ";
}
std::cout << "\n";
// 查找元素。 find()函数搜索一个元素并返回一个迭代器。如果未找到该元素则返回 mySet.end()
auto it = mySetD.find(13);
if (it != mySetD.end()) {
std::cout << std::format("Found {}\n", *it);
}
else {
std::cout << "13 not found" << std::endl;
}
// 移除元素。可以直接移除值,或直接移除迭代器
mySetD.erase(13);
mySetD.erase(mySetD.begin());
printContainer(mySetD);
// 检查集合大小
std::cout << std::format("mySetD Size: {}\n", mySetD.size());
// 移除集合中的所有元素并检查是否为空
mySetD.clear();
std::cout << std::format("mySetD is empty: {}\n", mySetD.empty());
// 自定义排序。默认情况下。std::set 按升序对元素排序,可以使用自定义比较器(comparator)降序创建一个集合
std::set<int, std::greater<int>> mySetDescending;
mySetDescending.insert(7);
mySetDescending.insert(3);
printContainer(mySetDescending);
// 范围操作(range operations)。
auto lower = mySetC.lower_bound(8); // 返回第一个不小于 x 的元素的迭代器
auto upper = mySetC.upper_bound(8); // 返回第一个大于 x 的元素的迭代器
if (lower != mySetC.end()) {
std::cout << std::format("(mySetC) Lower bound of 8: {}\n", *lower);
}
if (upper != mySetC.end()) {
std::cout << std::format("(mySetC) Upper bound of 8: {}\n", *upper);
}
// 合并两个集合。重复的元素仅保留一个
mySetA.insert(mySetB.begin(), mySetB.end());
printContainer(mySetA);
// 比较运算符。== 和!=
std::set<int> mySetF = { 1,2,3,4,5,7 };
if (mySetA == mySetF) {
std::cout << "mySetA is equal to mySetF\n";
}
else if (mySetA != mySetF){
std::cout << "mySetA is not equal to mySetF\n";
}
return 0;
}
🡮
{3,7}
{1,2,3,4,5}
{6,7,8,9,10}
{11,12,13,14,15}
1 2 3 4 5
6 7 8 9 10
Found 13
{12,14,15}
mySetD Size: 3
mySetD is empty: true
{7,3}
(mySetC) Lower bound of 8: 8
(mySetC) Upper bound of 8: 9
{1,2,3,4,5,7}
mySetA is equal to mySetF
std::set的成员函数包括:
(constructor)、(destructor)、operator=
Iterators(迭代器): begin()、end()、rbegin()、rend()、cbegin()、cend()、crbegin、crend()
Capacity(容量): empty()、size()、max_size()
Modifiers(修改器): insert()、erase()、swap()、clear()、emplace()、emplace_hint()
Observers(观察组):key_comp()、value_comp()
Operations:(运算):find()、count()、lower_bound()、upper_bound()、equal_range()
Allocator:(分配器):get_allocator()
多重集合(Multiset)和 集合(Set)都属于关联式容器(Associative containers),与集合不同的是多重集合允许存储重复的元素,如下示例,
#include <iostream>
#include <set>
#include <format>
template <typename Container>
void printContainer(const Container& container) {
std::cout << "{";
for (auto it = container.begin(); it != container.end(); ++it) {
std::cout << *it;
if (std::next(it) != container.end()) {
std::cout << ",";
}
}
std::cout << "}" << std::endl;
}
int main() {
// 声明并初始化多重集合
std::multiset<int> myMultiset = { 1,2,2,2,3,3,4,5 };
printContainer(myMultiset);
std::cout << std::format("Counting element 2: {}\n", myMultiset.count(2));
myMultiset.insert(2);
std::cout << std::format("After inserting an additional 2, counting element 2: {}\n", myMultiset.count(2));
return 0;
}
🡮
{1,2,2,2,3,3,4,5}
Counting element 2: 3
After inserting an additional 2, counting element 2: 4
4.3.2.2 Map 和 Multimap
映射(Map)属于关联式容器,用于存储由键值(key value)和映射值(mapped value)组合而成的元素,并遵循特定顺序。键值为唯一标识并通常用于对元素进行排序;而映射值存储与该键相关的内容。键(键值)和值(映射值)的类型可以不同,在成员类型value_type中组合在一起,为typedef pair<const Key, T> value_type;。映射值始终根据键按照由其内部的比较对象(类型为Compare)决定的严格弱序标准排序。映射容器在按键访问单个元素时通常比无序映射(unordered_map)容器慢,但允许基于顺序直接迭代子集。映射中的映射值可以通过相应的键使用中括号运算符operator[]直接访问。映射通常由二叉搜索树实现。
下述示例包含了映射的常用方法,有声明和初始化映射、根据键访问对应键的值、迭代键值对、查找元素、移除元素、返回键值对数量、清空映射容器、自定义排序等。
#include <iostream>
#include <map>
#include <format>
template<typename K, typename V, typename F>
void printMap(const std::map<K, V, F>& myMap) {
std::cout << "{";
for (auto it = myMap.begin(); it != myMap.end(); ++it) {
std::cout << it->first << ":" << it->second;
if (std::next(it) != myMap.end()) {
std::cout << ", ";
}
}
std::cout << "}" << std::endl;
}
struct CustomCompare {
bool operator()(const std::string& a, const std::string& b) const {
return a > b; // /按降序排序
}
};
int main() {
//声明空的映射
std::map<std::string, int> myMapA;
//用 insert() 和 operator[] 增加键值对
myMapA.insert({ "apple", 5 });
myMapA["orange"]= 7;
myMapA["banana"] = 13;
printMap(myMapA);
// 根据键访问映射值
std::cout << std::format("Value for key 'apple': {}; 'banana': {}\n", myMapA["apple"], myMapA.at("banana"));
// 迭代键值对
for (const auto& pair:myMapA) {
std::cout << std::format("{}:{} ", pair.first, pair.second);
}
std::cout << "\n";
std::map<std::string, int>::iterator it_map = myMapA.begin();
while (it_map != myMapA.end()) {
std::cout << std::format("{}:{} ", it_map->first, it_map->second);
++it_map;
}
std::cout << "\n";
// 查找元素
auto it = myMapA.find("orange");
if (it != myMapA.end()) {
std::cout << std::format("Found orange with value: {}\n", it->second);
}
else {
std::cout << "Orange not found\n";
}
// 移除元素
myMapA.erase("banana");
printMap(myMapA);
// 检查键值对数量
std::cout << std::format("Size: {}\n", myMapA.size());
// 清除映射容器中的所有元素
myMapA.clear();
std::cout << std::format("myMapA is empty: {}\n",myMapA.empty());
// 自定义排序
std::map<std::string, int, CustomCompare> myCustomMap = {
{"Henry",21},
{"Oliver",19},
{"Lily",33}
};
myCustomMap["Emily"] = 67;
myCustomMap.emplace("Amelia", 39); // 允许原地构造元素,从而避免不必要的复制或移动
printMap(myCustomMap);
return 0;
}
🡮
{apple:5, banana:13, orange:7}
Value for key 'apple': 5; 'banana': 13
apple:5 banana:13 orange:7
apple:5 banana:13 orange:7
Found orange with value: 7
{apple:5, orange:7}
Size: 2
myMapA is empty: true
{Oliver:19, Lily:33, Henry:21, Emily:67, Amelia:39}
std::map 的成员函数包括:
(constructor)、(destructor)、operator=
Iterators(迭代器): begin()、end()、rbegin()、rend()、cbegin()、cend()、crbegin、crend()
Capacity(容量): empty()、size()、max_size()
Element access(访问元素): operator[]、at()
Modifiers(修改器): insert()、erase()、swap()、clear()、emplace()、emplace_hint()
Observers(观察组):key_comp()、value_comp()
Operations:(运算):find()、count()、lower_bound()、upper_bound()、equal_range()
Allocator:(分配器):get_allocator()
多重映射(Multimap)和映射(Map)都属于关联式容器(Associative containers),与映射不同的是多个映射值可以有相同的键,其键值对不一定是唯一的,如下示例,
#include <iostream>
#include <map>
template<typename K, typename V, typename F>
void printMultiMap(const std::multimap<K, V, F>& myMap) {
std::cout << "{";
for (auto it = myMap.begin(); it != myMap.end(); ++it) {
std::cout << it->first << ":" << it->second;
if (std::next(it) != myMap.end()) {
std::cout << ", ";
}
}
std::cout << "}" << std::endl;
}
int main() {
std::multimap<int, std::string> myMultiMap = {
{1,"Amelia"},
{1, "Amelia"},
{3,"Emily"},
{4,"Henry"},
{3,"Emily"},
{5,"Lily"}
};
printMultiMap(myMultiMap);
myMultiMap.emplace(3, "Oliver");
printMultiMap(myMultiMap);
return 0;
}
🡮
{1:Amelia, 1:Amelia, 3:Emily, 3:Emily, 4:Henry, 5:Lily}
{1:Amelia, 1:Amelia, 3:Emily, 3:Emily, 3:Oliver, 4:Henry, 5:Lily}
4.3.3 无序关联式容器
无序集合(std::unordered_set)和无序多重集合(std::unordered_multiset)是基于哈希表的无序关联式容器(Unordered associative containers),其中的元素没有特定的顺序,一个用于存储仅含唯一元素的集合容器;另一个可以存储有重复元素的集合容器。
无序映射(std::unordered_map)和无序多重映射(std::unordered_multimap)是基于哈希表的无序关联式容器,是以键值对的形式存储元素,其中的元素没有特定的顺序,一个用于存储仅含唯一键的映射容器;另一个可以存储有相同键的映射容器。
下述为无序关联式容器数据结构的一个简单示例,
#include <iostream>
#include <unordered_set>
#include <unordered_map>
int main() {
std::unordered_set<int> myUnorderedSet = { 3,2,5,4,1 };
std::cout << "Contents of unordered_set: ";
for (const auto& element : myUnorderedSet)
std::cout << element << " ";
std::cout << std::endl;
std::unordered_multiset<int> myUnorderedMultiset = { 3,2,3,5,4,1,5,5 };
std::cout << "Contents of unordered_multiset: ";
for (const auto& element : myUnorderedMultiset)
std::cout << element << " ";
std::cout << std::endl;
std::unordered_map<std::string, int> myUnorderedMap = { {"apple",9},{"orange",23} };
std::cout << "Contents of unordered_map: ";
for (const auto& pair : myUnorderedMap)
std::cout << pair.first << ":" << pair.second << " ";
std::cout << std::endl;
std::unordered_multimap<std::string, int> myUnorderedMultimap = { {"apple",9},{"orange",23},{"orange",7} };
std::cout << "Contents of unordered_multimap: ";
for (const auto& pair : myUnorderedMultimap)
std::cout << pair.first << ":" << pair.second << " ";
std::cout << std::endl;
return 0;
}
🡮
Contents of unordered_set: 3 2 5 4 1
Contents of unordered_multiset: 3 3 2 5 5 5 4 1
Contents of unordered_map: apple:9 orange:23
Contents of unordered_multimap: apple:9 orange:23 orange:7
4.3.4 容器适配器
4.3.4.1 stack
栈(stack)是一种专门设计用于后进先出(last-in first-out,LIFO)场景的容器适配器类型,其中元素只能在容器的一端插入和移出。容器适配器是一类使用特定容器类作为其底层容器(underlying container)的封装对象,并提供一组特定的成员函数来访问其元素。元素在容器的尾部(back)进行压入(pushed)/弹出(popped)操作,这个尾部在栈中称为栈顶。底层可以是任何标准类模板,或其他专门设计的容器类。底层容器需要支持以下操作:
empty:检查容器是否为空。size:获取容器的元素数量。back:访问元素的最后一个元素(栈顶)。push_back:将元素插入容器尾部(栈顶)。pop_back:移除容器尾部(栈顶)的元素。
标准容器类vector、deque和list都满足这些要求。默认情况下,如果栈类实例化时未指定容器类,则将使用deque标准容器。下述示例包括声明一个栈、向栈中追加元素、访问栈顶元素、检查栈是否为空、通过弹出打印所有栈中元素等操作。
#include <iostream>
#include <stack>
#include <format>
int main() {
// 声明一个栈
std::stack<int> myStack;
// 将元素压入堆栈
myStack.push(10);
myStack.push(20);
myStack.emplace(30);
std::cout << std::format("Stack size after pushes: {}\n", myStack.size());
// 访问栈顶元素
std::cout << std::format("Top element: {}\n", myStack.top());
// 从栈中移除元素
myStack.pop();
std::cout << std::format("Top element after one top: {}\n", myStack.top());
// 检查栈是否为空
if (!myStack.empty()) {
std::cout << "The stack is not empty.\n";
}
else {
std::cout << "The stack is empty.\n";
}
// 通过弹出 pop() 打印所有元素
std::cout << "Popping all elements from stack: ";
while (!myStack.empty()) {
std::cout << myStack.top() << " ";
myStack.pop();
}
std::cout << std::endl;
return 0;
}
🡮
Stack size after pushes: 3
Top element: 30
Top element after one top: 20
The stack is not empty.
Popping all elements from stack: 20 10
4.3.4.2 queue 和 priority_queue
队列(queue)与栈(stack)类似,但是是一种专门设计用于先进先出(first-in first-out,FIFO)场景的容器适配器类型,即元素从容器的一端插入,而从另一端移出,其底层容器需要支持的操作包括,empty、size、front(访问容器的第一个元素)、back、push_back和pop_front(移除容器头部的元素)。
优先(级)队列(priority_queue)具有队列的所有特性,但元素被赋予了优先级,当访问元素时,具有最高优先级的元素最先被删除,即最高优先出的特征。在下述示例中通过向std::priority_queue<>传入参数实现由优先队列创建最小堆(min heap),其语法为priority_queue <int, std::vector<int>, std::greater<int>> gq;,其中参数,
int,是要存储在优先级队列中的元素类型。示例中为整数型,根据具体情况需替换成所需要的类型。std::vector<int>,是用于存储这些元素的底层容器类型。std::priority_queue不是容器,而只是容器适配器,用其包装其他容器。在这个示例中使用的是向量(Vector)作为底层容器,也可以选择其他的容器类型,只需要支持front()、push_back()和pop_back()的方法。std::greater<int>,是一个自定义比较函数,其决定了元素在优先级队列中排序的方式。这个示例为最小堆,意味最小的元素会在队列的顶部。std::priority_queue默认为最大堆。
#include <iostream>
#include <queue>
#include <format>
template <typename T, typename V, typename G>
void printPQueue(std::priority_queue<T,V,G> pq) {
std::cout << "{";
if (!pq.empty()) {
std::cout << pq.top();
pq.pop();
}
while (!pq.empty()) {
std::cout << "," << pq.top();
pq.pop();
}
std::cout << "}" << std::endl;
}
int main() {
// 声明一个队列,并将元素压入队列
std::queue<int> myQueue;
myQueue.push(10);
myQueue.push(20);
myQueue.emplace(30);
myQueue.emplace(40);
// 说明先进先出(FIFO)
std::cout << std::format("Front element: {}; Back element: {}\n", myQueue.front(), myQueue.back());
myQueue.pop();
std::cout << std::format("Front element after one pop: {}\n", myQueue.front());
// 将数组元素压入声明的优先队列
int arrayA[6] = { 23,10,3,6,7,5 };
std::priority_queue<int> myPriorityQueueA;
for (int i = 0; i < sizeof(arrayA) / sizeof(arrayA[0]); i++)
myPriorityQueueA.push(arrayA[i]);
// 优先级队列在 c++ 中默认实现为最大堆(heap)
printPQueue(myPriorityQueueA);
// 在创建优先级队列时传递参数 std::greater<int>,将其更改为最小堆
std::priority_queue<int, std::vector<int>, std::greater<int>> myPriorityQueueB(arrayA, arrayA + sizeof(arrayA) / sizeof(arrayA[0]));
printPQueue(myPriorityQueueB);
return 0;
}
🡮
Front element: 10; Back element: 40
Front element after one pop: 20
{23,10,7,6,5,3}
{3,5,6,7,10,23}
4.4 C# 的集合[Collection]
相似的数据在以集合的形式存储和操作时,通常更高效。可以从System.Array类、或位于System.Collections、System.Collections.Generic、System.Collections.Concurrent和System.Collections.Immutable命名空间中的类来添加、删除和修改集合中的单个或多个元素。集合主要分为两种类型,泛型集合(generic collections)和非泛型集合(non-generic collections)。泛型集合在编译时是类型安全的,因此通常提供更好的性能。创建泛型集合时,需要传入一个类型参数;添加或删除集合中的元素时不需要进行类型转换。非泛型集合则以Object类型存储元素,需要进行类型转换。位于System.Collections.Concurrent命名空间中的集合提供了高效的线程安全操作,允许从多个线程访问集合元素。而System.Collections.Immutable命名空间中的不可变集合类(NuGet 包)在原始集合的副本上进行操作,而原始集合不能修改,具有线性安全性。
- 选择适合的集合
通常情况下,应该使用泛型集合(System.Collections.Generic)。下述表描述了常用的集合场景,及适用于这些场景的集合类。
表 选择集合 表引自 microsoft .NET:集合和数据结构
| 场景 | 泛型集合选项 | 非泛型集合选项 | 线程安全或不可变集合选项 |
|---|---|---|---|
| 将项(元素)存储为键/值对以通过键进行快速查找 | Dictionary<TKey,TValue> |
Hashtable (根据键的哈希代码组织的键/值对的集合。) |
ConcurrentDictionary<TKey,TValue> ReadOnlyDictionary<TKey,TValue> ImmutableDictionary<TKey,TValue> |
| 按索引访问项 | List<T> |
ArrayArrayList |
ImmutableList<T> ImmutableArray |
| 使用元素先进先出 (FIFO) | Queue<T> |
Queue |
ConcurrentQueue<T> ImmutableQueue<T> |
| 使用元素后进先出 (LIFO) | Stack<T> |
Stack |
ConcurrentStack<T> ImmutableStack<T> |
| 按顺序访问项 | LinkedList<T> |
无建议 | 无建议 |
删除集合中的项或向集合添加项时接收通知。 (实现 INotifyPropertyChanged 和 INotifyCollectionChanged) |
ObservableCollection<T> |
无建议 | 无建议 |
| 已排序的集合 | SortedList<TKey,TValue> |
SortedList |
ImmutableSortedDictionary<TKey,TValue> ImmutableSortedSet<T> |
| 数学函数的一个集 | HashSet<T>SortedSet<T> |
无建议 | ImmutableHashSet<T> ImmutableSortedSet<T> |
- 集合的算法复杂度
在选择集合类时,需要考虑性能上的权衡。下表列出了各种可变集合类型与其对应的不可变集合类型在算法复杂度上的对比。不可变集合类型的性能通常较低,但提供了不可变性,在某些情况下有重要的优势。
表 集合的复杂度 表引自 microsoft .NET:集合和数据结构
| 可变(Mutable) | 分期(Amortized) | 最坏情况 (Worst Case) | 不可变(Immutable) | 复杂度 (Complexity) |
|---|---|---|---|---|
| Stack |
O(1) | O(n) | ImmutableStack |
O(1) |
| Queue |
O(1) | O(n) | ImmutableQueue |
O(1) |
| List |
O(1) | O(n) | ImmutableList |
O(log n) |
| List |
O(1) | O(1) | ImmutableList |
O(log n) |
| List |
O(n) | O(n) | ImmutableList |
O(log n) |
| HashSet |
O(1) | O(n) | ImmutableHashSet |
O(log n) |
| SortedSet |
O(log n) | O(n) | ImmutableSortedSet |
O(log n) |
| Dictionary |
O(1) | O(n) | ImmutableDictionary |
O(log n) |
| Dictionary |
O(1) | O(1) - 或者从严格意义上说, O(n) | ImmutableDictionary |
O(log n) |
| SortedDictionary |
O(log n) | O(n log n) | ImmutableSortedDictionary |
O(log n) |
4.4.1 List<T>
列表 List<T> 属于System.Collections.Generic命名空间,是 C# 中常用的泛型集合(generic collections)类型,类似于动态数组,可以存储任何类型的对象,并支持动态扩展。下述示例代码包括了创建和初始化List<T>、添加元素、访问元素、插入和移除元素、搜索元素、排序和反转列表、遍历列表和获取列表信息等操作。并定义PrintCollection()方法用于打印列表等序列对象。
using System;
using System.Collections.Generic;
class Program
{
public static void PrintCollection<T>(IEnumerable<T> collection)
{
string formatted = "[" + string.Join(",", collection) + "]";
Console.WriteLine(formatted);
}
static void Main()
{
// 创建 List<T> 后追加元素
List<int> numbers = new List<int>(); // 整型
List<string> names = new List<string>(); // 字符串
// 添加元素——单个元素
numbers.Add(30);
numbers.Add(50);
names.Add("Amelia");
names.Add("Lily");
names.Add("Amelia");
PrintCollection(numbers);
PrintCollection(names);
// 添加元素——添加多个元素
numbers.AddRange(new int[] { 70, 60, 80 });
numbers.AddRange([110, 100, 120]);
PrintCollection(numbers);
// 创建和初始化 List<T>
List<string> language = ["C", "C++", "C#", "Python"];
PrintCollection(language);
// 通过索引访问元素
int secondNumber = numbers[1];
string firstName = names[0];
Console.WriteLine($"second number: {secondNumber} \nfirst name: {firstName}");
// 在指定索引处插入元素
names.Insert(2, "Henry");
PrintCollection(names);
// 移除元素
names.Remove("Amelia"); // 移除第1次出现的指定元素
PrintCollection(names);
names.RemoveAt(1); // 移除指定索引处的元素
PrintCollection(names);
names.Clear(); // 清除所有元素
PrintCollection(names);
// 搜索元素
int found = numbers.Find(x => x > 70); // 查找符合条件的第一个元素。=> 为 lambda 运算符或箭头运算符
Console.WriteLine($"(x > 70 in numbers) found the first element: {found}");
List<int> allNumbersGreaterThan70 = numbers.FindAll(x => x>70); // 查找符合条件的所有元素
Console.Write("(x > 70 in numbers) found all elements: ");
PrintCollection(allNumbersGreaterThan70);
int index = language.IndexOf("C#"); // 查找元素,返回第一次出现该元素的索引
Console.WriteLine($"Found the index of the first occurence of C#: {index}");
bool hasCShape = language.Contains("C#"); // 检查一个特定的元素是否在列表中
Console.WriteLine($"C# in language list: {hasCShape}");
// 排序和反转
numbers.Sort(); // 按升序对元素进行排序
numbers.Reverse(); // 反转元素的顺序
PrintCollection(numbers);
// 遍历列表
foreach (string lan in language) // 用 foreach 方法
{
Console.Write($"{lan} ");
}
Console.WriteLine();
for (int i = 0; i< language.Count; i++) // 用 for 循环
{
Console.Write($"{language[i]} ");
}
Console.WriteLine();
// 获取列表信息
Console.WriteLine($"Get the number of elements in the list: {numbers.Count}"); // 获取元素数量
Console.WriteLine($"Gets or sets the total number of elements the list can hold before resizing: {numbers.Capacity}");
}
}
🡮
[30,50]
[Amelia,Lily,Amelia]
[30,50,70,60,80,110,100,120]
[C,C++,C#,Python]
second number: 50
first name: Amelia
[Amelia,Lily,Henry,Amelia]
[Lily,Henry,Amelia]
[Lily,Amelia]
[]
(x > 70 in numbers) found the first element: 80
(x > 70 in numbers) found all elements: [80,110,100,120]
Found the index of the first occurence of C#: 2
C# in language list: True
[120,110,100,80,70,60,50,30]
C C++ C# Python
C C++ C# Python
Get the number of elements in the list: 8
Gets or sets the total number of elements the list can hold before resizing: 8
下述表列出了List<T>的构造函数(Constructors)、属性(Properties)和方法(Methods)。
表 List
| 构造函数 | |
|---|---|
| List |
初始化 List |
| List |
初始化 List |
| List |
初始化 List |
| 属性 | |
| Capacity | 获取或设置内部数据结构可以在不调整大小的情况下保留的元素总数。 |
| Count | 获取 List |
| Item[Int32] | 获取或设置指定索引处的元素。 |
| 方法 | |
| Add(T) | 将对象添加到 List |
| AddRange(IEnumerable |
将指定集合的元素添加到 List |
| AsReadOnly() | 返回当前集合的只读 ReadOnlyCollection |
| BinarySearch(Int32, Int32, T, IComparer |
使用指定的比较器在排序 List |
| BinarySearch(T) | 使用默认比较器搜索整个排序 List |
| BinarySearch(T, IComparer |
使用指定的比较器搜索整个排序 List |
| Clear() | 从 List |
| Contains(T) | 确定元素是否在 List |
| ConvertAll |
将当前 List |
| CopyTo(Int32, T[], Int32, Int32) | 从 List |
| CopyTo(T[]) | 从目标数组的开头开始,将整个 List |
| CopyTo(T[], Int32) | 将整个 List |
| EnsureCapacity(Int32) | 确保此列表的容量至少为指定的 capacity。 如果当前容量小于 capacity,则它至少增加到指定的 capacity。 |
| Equals(Object) | 确定指定的对象是否等于当前对象。(继承自 Object) |
| Exists(Predicate |
确定 List |
| Find(Predicate |
搜索与指定谓词定义的条件匹配的元素,并返回整个 List |
| FindAll(Predicate |
检索与指定谓词定义的条件匹配的所有元素。 |
| FindIndex(Int32, Int32, Predicate |
搜索与指定谓词定义的条件匹配的元素,并返回从指定索引开始且包含指定数量的元素的 List |
| FindIndex(Int32, Predicate |
搜索与指定谓词定义的条件匹配的元素,并在从指定索引扩展到最后一个元素的 List |
| FindIndex(Predicate |
搜索与指定谓词定义的条件匹配的元素,并返回整个 List |
| FindLast(Predicate |
搜索与指定谓词定义的条件匹配的元素,并返回整个 List |
| FindLastIndex(Int32, Int32, Predicate |
搜索与指定谓词定义的条件匹配的元素,并返回 List |
| FindLastIndex(Int32, Predicate |
搜索与指定谓词定义的条件匹配的元素,并返回从第一个元素扩展到指定索引的 List |
| FindLastIndex(Predicate |
搜索与指定谓词定义的条件匹配的元素,并返回整个 List |
| ForEach(Action |
对 List |
| GetEnumerator() | 返回循环访问 List |
| GetHashCode() | 用作默认哈希函数。(继承自 Object) |
| GetRange(Int32, Int32) | 在源 List |
| GetType() | 获取当前实例的 Type。(继承自 Object) |
| IndexOf(T) | 搜索指定的对象,并返回整个 List |
| IndexOf(T, Int32) | 搜索指定的对象,并返回从指定索引扩展到最后一个元素的 List |
| IndexOf(T, Int32, Int32) | 搜索指定的对象,并返回从指定索引开始且包含指定数量的元素的 List |
| Insert(Int32, T) | 将元素插入指定索引处的 List |
| InsertRange(Int32, IEnumerable |
将集合的元素插入到指定索引处的 List |
| LastIndexOf(T) | 搜索指定的对象,并返回整个 List |
| LastIndexOf(T, Int32) | 搜索指定的对象,并返回从第一个元素扩展到指定索引的 List |
| LastIndexOf(T, Int32, Int32) | 搜索指定的对象,并返回 List |
| MemberwiseClone() | 创建当前 Object的浅表副本。(继承自 Object) |
| Remove(T) | 从 List |
| RemoveAll(Predicate |
删除与指定谓词定义的条件匹配的所有元素。 |
| RemoveAt(Int32) | 移除 List |
| RemoveRange(Int32, Int32) | 从 List |
| Reverse() | 反转整个 List |
| Reverse(Int32, Int32) | 反转指定区域中元素的顺序。 |
| Slice(Int32, Int32) | 在源 List |
| Sort() | 使用默认比较器对整个 List |
| Sort(Comparison |
使用指定的 Comparison |
| Sort(IComparer |
使用指定的比较器对整个 List |
| Sort(Int32, Int32, IComparer |
使用指定的比较器对 List |
| ToArray() | 将 List |
| ToString() | 返回一个表示当前对象的字符串。(继承自 Object) |
| TrimExcess() | 将容量设置为 List |
| TrueForAll(Predicate |
确定 List |
4.4.2 Dictionary<TKey,TValue>
字典 Dictionary<TKey, TValue>属于System.Collections.Generic命名空间的泛型集合类,是存储键-值对(key-value pairs)的集合,允许基于键快速检索值,这使得根据键快速查找、添加和删除值非常高效。TKey表示字典中键的类型;TValue表示字典中值的类型。键不能为空,但值类型为引用类型(reference type)时可以为空。
下述示例包括了创建和初始化字典、添加元素、访问元素、移除元素、检查元素、遍历字典、返回键或值的集合、获取字典信息和更新字典元素等操作。并定义了PrintDictionary()方法打印输出字典的键值对。
using System;
using System.Collections.Generic;
class Program
{
public static void PrintDictionary<TKey,TValue>(Dictionary<TKey,TValue> dictionary)
{
string formatted = "{" + string.Join(",", dictionary.Select(kv => $"{kv.Key}:{kv.Value}")) + "}";
Console.WriteLine(formatted);
}
public static void PrintCollection<T>(IEnumerable<T> collection)
{
string formatted = "[" + string.Join(",", collection) + "]";
Console.WriteLine(formatted);
}
static void Main()
{
// 创建一个空字典后添加键值对
Dictionary<int, string> numberNames= new Dictionary<int, string>();
Dictionary<string,string> capitals = new Dictionary<string,string>();
// 添加元素——用 Add() 方法添加键值对
numberNames.Add(7, "seven");
numberNames.Add(9, "nine");
numberNames.Add(11, "eleven");
// 添加元素——使用索引器(indexer),通过键直接赋值来添加或更新元素
capitals["China"] = "Beijing";
capitals["USA"] = "Washington";
capitals["France"] = "Paris";
PrintDictionary(numberNames);
PrintDictionary(capitals);
// 创建并初始化字典
Dictionary<string, int> score = new Dictionary<string, int>
{
{"Henry",99 },
{"Oliver",86 },
{"Emily",91 },
{"Lily",76 }
};
PrintDictionary(score);
// 访问元素。通过键访问字典中的值
string name = numberNames[9];
Console.WriteLine($"9:{name}");
Console.WriteLine($"Emily:{score["Emily"]}");
// 移除元素
score.Remove("Lily"); // 按键移除键值对
PrintDictionary(score);
score.Clear(); // 清除所有元素(键值对)
PrintDictionary(score);
// 检查元素
bool hasKey = capitals.ContainsKey("USA"); // 检查字典中是否存在指定的键
bool hasValue = capitals.ContainsValue("Washington"); // 检查字典中是否存在指定的值
Console.WriteLine($"has key 'USA':{hasKey}; has value 'Washington':{hasValue}");
// 遍历字典(键值对)
foreach (var kvp in capitals) // 用 var 推断变量的数据类型
{
Console.WriteLine($"Country: {kvp.Key}, Capital: {kvp.Value}");
}
foreach (KeyValuePair<int,string> kvp in numberNames){ // 用 KeyValuePair<> 指明变量数据类型
Console.WriteLine($"Country: {kvp.Key}, Capital: {kvp.Value}");
}
// 返回字典键或值的集合
ICollection<int> numberNames_keys = numberNames.Keys;
ICollection<string> numberNames_values=numberNames.Values;
PrintCollection(numberNames_keys);
PrintCollection(numberNames_values);
// 获取字典信息——键值对的数量
Console.WriteLine($"key-value pairs number: {numberNames.Count}");
// 更新字典元素
numberNames[11] = "5+6";
PrintDictionary(numberNames);
}
}
🡮
{7:seven,9:nine,11:eleven}
{China:Beijing,USA:Washington,France:Paris}
{Henry:99,Oliver:86,Emily:91,Lily:76}
9:nine
Emily:91
{Henry:99,Oliver:86,Emily:91}
{}
has key 'USA':True; has value 'Washington':True
Country: China, Capital: Beijing
Country: USA, Capital: Washington
Country: France, Capital: Paris
Country: 7, Capital: seven
Country: 9, Capital: nine
Country: 11, Capital: eleven
[7,9,11]
[seven,nine,eleven]
key-value pairs number: 3
{7:seven,9:nine,11:5+6}
下述表列出了Dictionary<TKey,TValue>的构造函数(Constructors)、属性(Properties)和方法(Methods)。
表 List
| 构造函数 | |
|---|---|
| Dictionary<TKey,TValue>() | 初始化为空的 Dictionary<TKey,TValue> 类的新实例,具有默认的初始容量,并为键类型使用默认相等比较器。 |
| Dictionary<TKey,TValue>(IDictionary<TKey,TValue>) | 初始化 Dictionary<TKey,TValue> 类的新实例,该实例包含从指定 IDictionary<TKey,TValue> 复制的元素,并使用键类型的默认相等比较器。 |
| Dictionary<TKey,TValue>(IDictionary<TKey,TValue>, IEqualityComparer |
初始化 Dictionary<TKey,TValue> 类的新实例,该实例包含从指定 IDictionary<TKey,TValue> 复制的元素,并使用指定的 IEqualityComparer |
| Dictionary<TKey,TValue>(IEnumerable<KeyValuePair<TKey,TValue») | 初始化 Dictionary<TKey,TValue> 类的新实例,该实例包含从指定的 IEnumerable |
| Dictionary<TKey,TValue>(IEnumerable<KeyValuePair<TKey,TValue», IEqualityComparer |
初始化 Dictionary<TKey,TValue> 类的新实例,该实例包含从指定 IEnumerable |
| Dictionary<TKey,TValue>(IEqualityComparer |
初始化 Dictionary<TKey,TValue> 类的新实例,该实例为空,具有默认的初始容量,并使用指定的 IEqualityComparer |
| Dictionary<TKey,TValue>(Int32) | 初始化 Dictionary<TKey,TValue> 类的新实例,该实例为空,具有指定的初始容量,并使用键类型的默认相等比较器。 |
| Dictionary<TKey,TValue>(Int32, IEqualityComparer |
初始化 Dictionary<TKey,TValue> 类的新实例,该实例为空,具有指定的初始容量,并使用指定的 IEqualityComparer |
| Dictionary<TKey,TValue>(SerializationInfo, StreamingContext) | 已过时。使用序列化的数据初始化 Dictionary<TKey,TValue> 类的新实例。 |
| 属性 | |
| Comparer | 获取用于确定字典键相等性的 IEqualityComparer<T>。 |
| Count | 获取 Dictionary<TKey,TValue>中包含的键/值对数。 |
| Item[TKey] | 获取或设置与指定键关联的值。 |
| Keys | 获取包含 Dictionary<TKey,TValue>中的键的集合。 |
| Values | 获取一个集合,该集合包含 Dictionary<TKey,TValue>中的值。 |
| 方法 | |
| Add(TKey, TValue) | 将指定的键和值添加到字典。 |
| Clear() | 从 Dictionary<TKey,TValue>中删除所有键和值。 |
| ContainsKey(TKey) | 确定 Dictionary<TKey,TValue> 是否包含指定的键。 |
| ContainsValue(TValue) | 确定 Dictionary<TKey,TValue> 是否包含特定值。 |
| EnsureCapacity(Int32) | 确保字典可以容纳指定数量的条目,而无需进一步扩展其备用存储器。 |
| Equals(Object) | 确定指定的对象是否等于当前对象。(继承自 Object) |
| GetEnumerator() | 返回循环访问 Dictionary<TKey,TValue>的枚举数。 |
| GetHashCode() | 用作默认哈希函数。(继承自 Object) |
| GetObjectData(SerializationInfo, StreamingContext) | 已过时。实现 ISerializable 接口并返回序列化 Dictionary<TKey,TValue> 实例所需的数据。 |
| GetType() | 获取当前实例的 Type。(继承自 Object) |
| MemberwiseClone() | 创建当前 Object的浅表副本。(继承自 Object) |
| OnDeserialization(Object) | 实现 ISerializable 接口,并在反序列化完成时引发反序列化事件。 |
| Remove(TKey) | 从 Dictionary<TKey,TValue>中删除具有指定键的值。 |
| Remove(TKey, TValue) | 从 Dictionary<TKey,TValue>中删除具有指定键的值,并将元素复制到 value 参数。 |
| ToString() | 返回一个表示当前对象的字符串。(继承自 Object) |
| TrimExcess() | 将此字典的容量设置为最初使用其所有条目进行初始化时应采用的容量。 |
| TrimExcess(Int32) | 设置此字典的容量,以保留指定数量的条目,而无需进一步扩展其备用存储器。 |
| TryAdd(TKey, TValue) | 尝试将指定的键和值添加到字典。 |
| TryGetValue(TKey, TValue) | 获取与指定键关联的值。 |
4.4.3 HashSet<T>
哈希集合 HashSet<T> 属于System.Collections.Generic命名空间的泛型集合类,是一个存储唯一元素的集合,并提供高效的集合操作,如并(union)、交(intersection)和差(difference)等。在下述示例中包括声明和初始化哈希集合、添加元素、移除元素、检查元素、遍历集合、集合运算和返回集合中元素的数量等操作。
using System;
using System.Collections.Generic;
class Program
{
public static void PrintCollection<T>(IEnumerable<T> collection)
{
string formatted = "[" + string.Join(",", collection) + "]";
Console.WriteLine(formatted);
}
static void Main()
{
// 声明空的哈希集合
HashSet<int> numbers = new HashSet<int>();
PrintCollection(numbers);
HashSet<string> fruits = new HashSet<string>();
// 添加元素
numbers.Add(36);
numbers.Add(6);
numbers.Add(20);
numbers.Add(6);
fruits.Add("Cherry");
fruits.Add("Peach");
fruits.Add("Lemon");
fruits.Add("Grape");
PrintCollection(numbers);
PrintCollection(fruits);
// 声明并初始化集合
HashSet<string> names = new HashSet<string> { "Oliver", "Lily", "Henry", "Emily", "Amelia" };
PrintCollection(names);
// 移除元素
fruits.Remove("Lemon"); // 移除指定的元素
PrintCollection(fruits);
fruits.Clear(); // 清空集合
PrintCollection(fruits);
// 检查元素
bool hasEmily = names.Contains("Emily");
Console.WriteLine($"Emily exists in the names set: {hasEmily}");
// 遍历集合
foreach (var name in names)
{
Console.Write($"{name} ");
}
Console.WriteLine();
// 集合运算。HashSet<T> 支持多种集合运算,如并集(UnionWith)、交集(IntersectWith)、差集(ExceptWith)和对称差运算(SymmetricExceptionWith)等
HashSet<int> num1 = new HashSet<int> { 1, 2, 3, 4, 5 };
HashSet<int> copiedNum1=new HashSet<int> (num1);
HashSet<int> num2 = new HashSet<int> { 3, 4, 5, 6, 7 };
HashSet<int> num3 = new HashSet<int> { 11,12,13,14,15 };
num1.UnionWith(num2); // 并集(Union),组合两个集合,并仅保留一个重复元素
PrintCollection(num1);
num1.IntersectWith(num2); //交集(Intersection),只保留两个集合中都存在的元素
PrintCollection(num1);
num2.ExceptWith(copiedNum1); //差集(Difference),删除在另一个集合中可以找到的元素
PrintCollection(num2);
copiedNum1.SymmetricExceptWith(num1); // 对称差运算(Symmetric Difference),保留两个集合中非交集的部分
PrintCollection(copiedNum1);
// 返回集合中元素的数量
Console.WriteLine($"The number of names: {names.Count}");
}
}
🡮
[]
[36,6,20]
[Cherry,Peach,Lemon,Grape]
[Oliver,Lily,Henry,Emily,Amelia]
[Cherry,Peach,Grape]
[]
Emily exists in the names set: True
Oliver Lily Henry Emily Amelia
[1,2,3,4,5,6,7]
[3,4,5,6,7]
[6,7]
[1,2,7,6]
The number of names: 5
下述表列出了HashSet<T>的构造函数(Constructors)、属性(Properties)和方法(Methods)。
表 HashSet
| 构造函数 | |
|---|---|
| HashSet |
初始化 HashSet |
| HashSet |
初始化 HashSet |
| HashSet |
初始化 HashSet |
| HashSet |
初始化 HashSet |
| HashSet |
初始化 HashSet |
| HashSet |
初始化 HashSet |
| HashSet |
已过时。使用序列化的数据初始化 HashSet |
| 属性 | |
| Comparer | 获取用于确定集合中值的相等性 IEqualityComparer |
| Count | 获取集中包含的元素数。 |
| 方法 | |
| Add(T) | 将指定的元素添加到集合。 |
| Clear() | 从 HashSet |
| Contains(T) | 确定 HashSet |
| CopyTo(T[]) | 将 HashSet |
| CopyTo(T[], Int32) | 从指定的数组索引开始,将 HashSet |
| CopyTo(T[], Int32, Int32) | 从指定的数组索引开始,将 HashSet |
| CreateSetComparer() | 返回一个 IEqualityComparer 对象,该对象可用于 HashSet |
| EnsureCapacity(Int32) | 确保此哈希集可以保留指定数量的元素,而无需进一步扩展其备用存储器。 |
| Equals(Object) | 确定指定的对象是否等于当前对象。(继承自 Object) |
| ExceptWith(IEnumerable |
从当前 HashSet |
| GetEnumerator() | 返回循环访问 HashSet |
| GetHashCode() | 用作默认哈希函数。(继承自 Object) |
| GetObjectData(SerializationInfo, StreamingContext) | 已过时。实现 ISerializable 接口并返回序列化 HashSet |
| GetType() | 获取当前实例的 Type。(继承自 Object) |
| IntersectWith(IEnumerable |
修改当前 HashSet |
| IsProperSubsetOf(IEnumerable |
确定 HashSet |
| IsProperSupersetOf(IEnumerable |
确定 HashSet |
| IsSubsetOf(IEnumerable |
确定 HashSet |
| IsSupersetOf(IEnumerable |
确定 HashSet |
| MemberwiseClone() | 创建当前 Object的浅表副本。(继承自 Object) |
| OnDeserialization(Object) | 实现 ISerializable 接口,并在反序列化完成时引发反序列化事件。 |
| Overlaps(IEnumerable |
确定当前 HashSet |
| Remove(T) | 从 HashSet |
| RemoveWhere(Predicate |
从 HashSet |
| SetEquals(IEnumerable |
确定 HashSet |
| SymmetricExceptWith(IEnumerable |
修改当前 HashSet |
| ToString() | 返回一个表示当前对象的字符串。(继承自 Object) |
| TrimExcess() | 将 HashSet |
| TryGetValue(T, T) | 在集合中搜索给定的值并返回它找到的相等的值(如果有的话) |
| UnionWith(IEnumerable |
修改当前 HashSet |
4.4.4 Queue<T>
哈希集合 Queue<T> 属于System.Collections.Generic命名空间的泛型集合类,是一个代表先进先出(first-in first-out,FIFO)数据结构的集合,适合于按添加元素顺序管理项目的应用。下述示例中包括创建和初始化队列、添加元素、移除元素、查看元素、返回队列中元素的数量、检查队列中是否包含指定元素、清空队列和遍历队列等操作。
using System;
using System.Collections.Generic;
class Program
{
public static void PrintCollection<T>(IEnumerable<T> collection)
{
string formatted = "[" + string.Join(",", collection) + "]";
Console.WriteLine(formatted);
}
static void Main()
{
// 创建和初始化队列
Queue<int> numbers = new Queue<int>();
Queue<string> names = new Queue<string>(new[] { "Oliver", "Lily", "Henry", "Emily", "Amelia" });
// 添加元素
numbers.Enqueue(1);
numbers.Enqueue(7);
numbers.Enqueue(5);
numbers.Enqueue(9);
numbers.Enqueue(18);
PrintCollection(numbers);
PrintCollection(names);
// 移除元素
int firstNumber = numbers.Dequeue();// 移除并返回队列中最前面的元素。队列为空时调用此方法会抛出 InvalidOperationException
Console.WriteLine(firstNumber);
PrintCollection(numbers);
// 查看元素
int nextNumber = numbers.Peek(); // 查看队列中最前面的元素,但不移除它。队列为空时调用此方法会抛出 InvalidOperationException
Console.WriteLine(nextNumber);
PrintCollection(numbers);
// 检查队列状态
Console.WriteLine($"The number of elements in numbers: {numbers.Count}"); // 返回队列中元素的数量
Console.WriteLine($"If Henry in names: {names.Contains("Henry")}"); // 检查队列中是否包含指定元素
// 清空队列
numbers.Clear();
bool isEmpty = numbers.Count == 0;
Console.WriteLine(isEmpty);
// 遍历队列
foreach (string name in names)
{
Console.Write($"{name} ");
}
Console.WriteLine();
}
}
🡮
[1,7,5,9,18]
[Oliver,Lily,Henry,Emily,Amelia]
1
[7,5,9,18]
7
[7,5,9,18]
The number of elements in numbers: 4
If Henry in names: True
True
Oliver Lily Henry Emily Amelia
下述表列出了Queue<T>的构造函数(Constructors)、属性(Properties)和方法(Methods)。
表 Queue
| 构造函数 | |
|---|---|
| Queue |
初始化 Queue |
| Queue |
初始化 Queue |
| Queue |
初始化 Queue |
| 属性 | |
| Count | 获取 Queue |
| 方法 | |
| Clear() | 从 Queue |
| Contains(T) | 确定元素是否在 Queue |
| CopyTo(T[], Int32) | 从指定的数组索引开始,将 Queue |
| Dequeue() | 删除并返回 Queue |
| Enqueue(T) | 将对象添加到 Queue |
| EnsureCapacity(Int32) | 确保此队列的容量至少为指定的 capacity。 如果当前容量小于 capacity,则它至少增加到指定的 capacity。 |
| Equals(Object) | 确定指定的对象是否等于当前对象。(继承自 Object) |
| GetEnumerator() | 返回循环访问 Queue |
| GetHashCode() | 用作默认哈希函数。(继承自 Object) |
| GetType() | 获取当前实例的 Type。(继承自 Object) |
| MemberwiseClone() | 创建当前 Object的浅表副本。(继承自 Object) |
| Peek() | 返回 Queue |
| ToArray() | 将 Queue |
| ToString() | 返回一个表示当前对象的字符串。(继承自 Object) |
| TrimExcess() | 将容量设置为 Queue |
| TryDequeue(T) | 删除 Queue |
| TryPeek(T) | 返回一个值,该值指示 Queue |
4.4.5 Stack<T>
哈希集合 Stack<T> 属于System.Collections.Generic命名空间的泛型集合类,表示一个后进先出(last-in first-out,LIFO)的集合,适合于需要按照相反顺序处理元素的场景。下述示例代码包括创建和初始化、添加元素、移除元素、查看元素、返回栈中元素的数量、检查栈中是否包含指定的元素、清空栈、遍历栈、复制栈和栈到数组等操作。
using System;
using System.Collections.Generic;
class Program
{
public static void PrintCollection<T>(IEnumerable<T> collection)
{
string formatted = "[" + string.Join(",", collection) + "]";
Console.WriteLine(formatted);
}
static void Main()
{
// 创建和初始化 Stack<T>
Stack<int> numbers = new Stack<int>();
Stack<string> names = new Stack<string>(new[] { "Oliver", "Lily", "Henry", "Emily", "Amelia" });
// 添加元素
numbers.Push(1);
numbers.Push(7);
numbers.Push(5);
numbers.Push(9);
numbers.Push(18);
PrintCollection(numbers);
PrintCollection(names);
// 移除元素
int topNumber = numbers.Pop(); // 移除并返回栈顶的元素。栈为空时调用此方法会抛出 InvalidOperationException
Console.WriteLine(topNumber);
PrintCollection(numbers);
// 查看元素
int nextTopNumber = numbers.Peek(); // 查看栈顶的元素,但不移除它。栈为空时调用此方法会抛出 InvalidOperationException
Console.WriteLine(nextTopNumber);
PrintCollection(numbers);
// 检查栈状态
Console.WriteLine($"The number of elements in the stack: {numbers.Count}"); // 返回栈中元素的数量
Console.WriteLine($"If Henry in names: {names.Contains("Henry")}"); // 检查栈中是否包含指定的元素
// 清空栈
numbers.Clear();
bool isEmpty = numbers.Count == 0;
Console.WriteLine($"numbers is empty: {isEmpty}");
// 遍历栈
foreach (var name in names)
{
Console.Write($"{name} ");
}
Console.WriteLine();
// 复制栈
Stack<string> copiedNames=new Stack<string>(names.ToArray());
PrintCollection(copiedNames);
// 栈到数组
string[] arrayName=new string[names.Count*2];
names.CopyTo(arrayName, names.Count);
PrintCollection(arrayName);
}
}
🡮
[18,9,5,7,1]
[Amelia,Emily,Henry,Lily,Oliver]
18
[9,5,7,1]
9
[9,5,7,1]
The number of elements in the stack: 4
If Henry in names: True
numbers is empty: True
Amelia Emily Henry Lily Oliver
[Oliver,Lily,Henry,Emily,Amelia]
[,,,,,Amelia,Emily,Henry,Lily,Oliver]
下述表列出了Stack<T>的构造函数(Constructors)、属性(Properties)和方法(Methods)。
表 Stack
| 构造函数 | |
|---|---|
| Stack |
初始化 Stack |
| Stack |
初始化 Stack |
| Stack |
初始化 Stack |
| 属性 | |
| Count | 获取 Stack |
| 方法 | |
| Clear() | 从 Stack |
| Contains(T) | 确定元素是否在 Stack |
| CopyTo(T[], Int32) | 从指定的数组索引开始,将 Stack |
| EnsureCapacity(Int32) | 确保此 Stack 的容量至少为指定的 capacity。 如果当前容量小于 capacity,则它至少增加到指定的 capacity。 |
| Equals(Object) | 确定指定的对象是否等于当前对象。(继承自 Object) |
| GetEnumerator() | 返回 Stack |
| GetHashCode() | 用作默认哈希函数。(继承自 Object) |
| GetType() | 获取当前实例的 Type。(继承自 Object) |
| MemberwiseClone() | 创建当前 Object的浅表副本。(继承自 Object) |
| Peek() | 返回 Stack |
| Pop() | 删除并返回 Stack |
| Push(T) | 在 Stack |
| ToArray() | 将 Stack |
| ToString() | 返回一个表示当前对象的字符串。(继承自 Object) |
| TrimExcess() | 将容量设置为 Stack |
| TryPeek(T) | 返回一个值,该值指示 Stack |
| TryPop(T) | 返回一个值,该值指示 Stack |
4.4.6 LinkedList<T>
链表 LinkedList<T> 属于System.Collections.Generic命名空间的泛型集合类,表示一个双向链表的集合,意味着每个元素(或节点)都包含对序列中下一个和前一个节点的引用。这种结构允许从列表的两端进行高效的插入和删除,使其非常适合需要频繁更新集合的场景。下述示例代码包括创建和初始化链表、添加元素、移除元素、查找元素、遍历链表、获取链表节点等操作。
using System;
using System.Collections.Generic;
using System.Net.Http.Headers;
class Program
{
public static void PrintCollection<T>(IEnumerable<T> collection)
{
string formatted = "[" + string.Join(",", collection) + "]";
Console.WriteLine(formatted);
}
static void Main()
{
// 创建和初始化链表
LinkedList<int> numbers = new LinkedList<int>();
LinkedList<string> names= new LinkedList<string>(new[] { "Oliver", "Lily", "Henry", "Emily", "Amelia" });
// 添加元素
numbers.AddFirst(1); // List: 1 在列表的开头添加一个元素
numbers.AddFirst(2); // List: 2 -> 1
numbers.AddLast(3); // List: 2 -> 1 -> 3 在列表的末尾添加一个元素
numbers.AddLast(4); // List: 2 -> 1 -> 3 -> 4
PrintCollection(numbers);
var node1 = numbers.Find(1);
Console.WriteLine(node1);
numbers.AddAfter(node1, 5); // List: 2 -> 1 -> 5-> 3 -> 4 在指定的现有节点之后添加一个新节点
numbers.AddBefore(node1, 6); // List: 2 -> 6 -> 1 -> 5-> 3 -> 4 在指定的现有节点之前添加一个新节点
PrintCollection(numbers);
// 移除元素
numbers.Remove(1); // 移除指定节点
PrintCollection(numbers);
numbers.RemoveFirst(); // 删除列表中的第一个节点
numbers.RemoveLast(); // 删除列表中的最后一个节点
PrintCollection(numbers);
// 查找元素
bool hasFive = numbers.Contains(5);
Console.WriteLine($"5 in numbers: {hasFive}");
// 遍历链表
foreach (int number in numbers)
{
Console.Write($"{number} ");
}
Console.WriteLine();
// 获取链表节点
LinkedListNode<int> node = numbers.Find(5);
if (node != null)
{
Console.WriteLine($"Found node: {node}");
}
}
}
🡮
[2,1,3,4]
System.Collections.Generic.LinkedListNode`1[System.Int32]
[2,6,1,5,3,4]
[2,6,5,3,4]
[6,5,3]
5 in numbers: True
6 5 3
Found node: System.Collections.Generic.LinkedListNode`1[System.Int32]
下述表列出了LinkedList<T>的构造函数(Constructors)、属性(Properties)和方法(Methods)。
表 LinkedList
| 构造函数 | |
|---|---|
| LinkedList |
初始化 LinkedList |
| LinkedList |
初始化 LinkedList |
| LinkedList |
已过时。初始化使用指定的 SerializationInfo 和 StreamingContext可序列化的 LinkedList |
| 属性 | |
| Count | 获取实际包含在 LinkedList |
| First | 获取 LinkedList |
| Last | 获取 LinkedList |
| 方法 | |
| AddAfter(LinkedListNode |
在 LinkedList |
| AddAfter(LinkedListNode |
在 LinkedList |
| AddBefore(LinkedListNode |
在 LinkedList |
| AddBefore(LinkedListNode |
在 LinkedList |
| AddFirst(LinkedListNode |
在 LinkedList |
| AddFirst(T) | 在 LinkedList |
| AddLast(LinkedListNode |
在 LinkedList |
| AddLast(T) | 在 LinkedList |
| Clear() | 从 LinkedList |
| Contains(T) | 确定值是否在 LinkedList |
| CopyTo(T[], Int32) | 从目标数组的指定索引处开始,将整个 LinkedList |
| Equals(Object) | 确定指定的对象是否等于当前对象。(继承自 Object) |
| Find(T) | 查找包含指定值的第一个节点。 |
| FindLast(T) | 查找包含指定值的最后一个节点。 |
| GetEnumerator() | 返回循环访问 LinkedList |
| GetHashCode() | 用作默认哈希函数。(继承自 Object) |
| GetObjectData(SerializationInfo, StreamingContext) | 已过时。实现 ISerializable 接口并返回序列化 LinkedList |
| GetType() | 获取当前实例的 Type。(继承自 Object) |
| MemberwiseClone() | 创建当前 Object的浅表副本。(继承自 Object) |
| OnDeserialization(Object) | 实现 ISerializable 接口,并在反序列化完成时引发反序列化事件。 |
| Remove(LinkedListNode |
从 LinkedList |
| Remove(T) | 从 LinkedList |
| RemoveFirst() | 删除 LinkedList |
| RemoveLast() | 删除 LinkedList |
| ToString() | 返回一个表示当前对象的字符串。(继承自 Object) |
4.5 Python 数据结构
4.5.1 Lists
列表(Lists)是 Python 内置的一种基本数据结构,用于存储多个元素。这些元素可以是任何类型的对象,包括数值、字符串、布尔值、甚至其他列表,乃至函数或类对象。列表具有可变性(mutable):列表中的元素可以被修改,例如添加、删除 或者更新元素等;具有有序性:列表中的元素是顺序的,每个元素都有一个固定的索引值,并从索引值 0 开始,递增1计算(0,1,2,...,n),也可以逆序(-1,-2,-3,...,-n);列表具有可重复性:即列表可以包含重复的元素。列表可表示为[v0,v1,v2,...,vn]。列表的常用操作如下示例。
# 创建列表
my_list = [] # 用 [] 建立一个空列表
fruits = [
"apple",
"banana",
"orange",
"Cherry",
"Peach",
] # 建立仅包含字符串(元素)的列表
mixed = [3.141, "Lemon", 7, True] # 创建一个混合类型的列表
letters = list("Hello!") # 用 list 创建一个列表
numbers = list(range(0, 10, 1)) # 用 list 传入 range() 区间建立序列列表
names = list(
enumerate(["Oliver", "Lily", "Henry", "Emily", "Amelia"], start=1)
) # 传入可迭代对象建立列表
print(
f"my_list={my_list}\nfruits={fruits}\nmixed={mixed}\nletters={letters}\nnumbers={numbers}\nnames={names}"
)
# 访问列表元素——使用索引值,列表索引值从 0 开始;为正数从前向后计数;为负数时,从后向前计数
print(f"fruits[0]={fruits[0]}\nfruits[3]={fruits[3]}\nfruits[-2]={fruits[-2]}")
# 修改元素
fruits[3] = "Plum"
# 添加元素
fruits.append("Grape") # 在末尾添加元素
print(fruits)
fruits.extend(["Kiwi", "Mango", "orange"]) # 追加另一个列表的元素
print(fruits)
fruits.insert(1, "Lemon") # 在指定位置添加元素
print(fruits)
# 删除元素
fruits.remove("apple") # 直接删除元素
print(fruits)
popped_fruit = fruits.pop(
3
) # 按索引删除元素并返回该索引对应的元素;如果不指定索引则删除并返回最后一个元素
print(popped_fruit)
print(fruits)
del fruits[0] # 用 del 直接删除指定索引的元素
print(fruits)
# 复制列表
copiedMixed = mixed.copy() # 用方法 copy() 返回列表的浅复制(shallow copy)
print(copiedMixed)
# 元素计数
print(f"The number of times 'orange' in fruits list: {fruits.count("orange")}")
# 反转列表
copiedMixed.reverse() # in place
print(copiedMixed)
# 返回元素索引值
print(
f"The index of the first item whose value is equal to 'orange': {fruits.index("orange")}"
)
print(
f"To a particular subsequence of the fruits list, 'orange' index: {fruits.index("orange",3)}"
)
# 列表切片/分片(List Slicing)。给始末索引值及步幅值,语法为list[a:b:c],a为开始值,b为结束值,C为步幅值(默认为1)。三个参数可以配置负值逆序。a 或 b 忽略时则默认为从始或到末
# Slicing——访问列表元素
subset_1 = numbers[1:5:2]
print(subset_1)
print(numbers[:3])
print(numbers[-3:-1])
print(numbers[-3:])
print(numbers[:])
# Slicing——分片赋值
numbers[5:8] = list(range(10, 13))
print(numbers)
numbers[2:2] = [101, 102, 103] # 相当于在索引 2 处插入了另一个列表
print(numbers)
# Slicing——删除元素
del numbers[2:8]
print(numbers)
# 排序列表
numbers.sort() # in place
print(numbers)
# 内置函数:求最大值、最小值、求和、计算列表的长度
print(
f"Max value: {max(numbers)}; Min vvalue: {min(numbers)}; Sum: {sum(numbers)};list length: {len((numbers))}"
)
# 清空列表
numbers.clear()
print(len(numbers))
# 嵌套列表
nested_list = [[1, 2], [3, 4]]
print(nested_list[1][0])
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
flipped_matrix = [
[row[i] for row in matrix] for i in range(4)
] # 使用了列表推导式(参语句考循环部分)
print(flipped_matrix)
🡮
<9> my_list=[]
<9> fruits=['apple', 'banana', 'orange', 'Cherry', 'Peach']
<9> mixed=[3.141, 'Lemon', 7, True]
<9> letters=['H', 'e', 'l', 'l', 'o', '!']
<9> numbers=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
<9> names=[(1, 'Oliver'), (2, 'Lily'), (3, 'Henry'), (4, 'Emily'), (5, 'Amelia')]
<12> fruits[0]=apple
<12> fruits[3]=Cherry
<12> fruits[-2]=Cherry
<18> ['apple', 'banana', 'orange', 'Plum', 'Peach', 'Grape']
<20> ['apple', 'banana', 'orange', 'Plum', 'Peach', 'Grape', 'Kiwi', 'Mango', 'orange']
<22> ['apple', 'Lemon', 'banana', 'orange', 'Plum', 'Peach', 'Grape', 'Kiwi', 'Mango', 'orange']
<26> ['Lemon', 'banana', 'orange', 'Plum', 'Peach', 'Grape', 'Kiwi', 'Mango', 'orange']
<28> Plum
<29> ['Lemon', 'banana', 'orange', 'Peach', 'Grape', 'Kiwi', 'Mango', 'orange']
<32> ['banana', 'orange', 'Peach', 'Grape', 'Kiwi', 'Mango', 'orange']
<36> [3.141, 'Lemon', 7, True]
<39> The number of times 'orange' in fruits list: 2
<43> [True, 7, 'Lemon', 3.141]
<46> The index of the first item whose value is equal to 'orange': 1
<47> To a particular subsequence of the fruits list, 'orange' index: 6
<52> [1, 3]
<53> [0, 1, 2]
<54> [7, 8]
<55> [7, 8, 9]
<56> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
<60> [0, 1, 2, 3, 4, 10, 11, 12, 8, 9]
<62> [0, 1, 101, 102, 103, 2, 3, 4, 10, 11, 12, 8, 9]
<66> [0, 1, 10, 11, 12, 8, 9]
<70> [0, 1, 8, 9, 10, 11, 12]
<73> Max value: 12; Min vvalue: 0; Sum: 51;list length: 7
<77> 0
<81> 3
<90> [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
上述示例包括了列表的内置函数(len(),max(),min(),sum()等),也展示了列表的内置方法。对于内置方法总结如下表。
| 方法 | 解释 |
|---|---|
list.append(x) |
在列表末尾添加一个元素,相当于 a[len(a):] = [x] |
list.extend(iterable) |
用可迭代对象的元素扩展列表。相当于 a[len(a):] = iterable |
list.insert(i, x) |
在指定位置插入元素。第一个参数是插入元素的索引,因此,a.insert(0, x) 在列表开头插入元素, a.insert(len(a), x) 等同于 a.append(x) |
list.remove(x) |
从列表中删除第一个值为 x 的元素。未找到指定元素时,触发 ValueError 异常 |
list.pop([i]) |
移除列表中给定位置上的元素,并返回该元素。 如果未指定索引号,则 a.pop() 将移除并返回列表中的最后一个元素。 如果列表为空或索引号在列表索引范围之外则会引发 IndexError |
list.clear() |
删除列表里的所有元素,相当于 del a[:] |
list.index(x[, start[, end]]) |
返回列表中第一个值为 x 的元素的索引。未找到指定元素时,触发 ValueError 异常。可选参数 start 和 end 是切片符号,用于将搜索限制为列表的特定子序列(子集)。返回的索引是相对于整个列表的索引,而不是 start 参数 |
list.count(x) |
返回列表中元素 x 出现的次数 |
list.sort(*, key=None, reverse=False) |
就地排序列表中的元素 |
list.reverse() |
翻转列表中的元素 |
list.copy() |
返回列表的浅拷贝 |
4.5.2 Tuples
元组的语法为(v0,v1,v2,...,vn),不同于列表的中括号,为小括号表示,中间逗号隔开。元组不能够修改数据是其主要特性,即元组是不可变的(immutable)。元组的建立方法一种是2,5,6,在成员对象末尾直接加一个逗号;或则使用tuple(iterable=(), /)函数,参数为可迭代对象;亦可直接敲入元组语法(2,5,6)。元组含有两个方法,一个是count(),用于统计给定元素的数量;另一个是index(),用于返回给定元素第一个出现该元素的索引值。列表中具有保持序列不变性的方法同样适用于元组。元组的常用操作如下示例。
# 建立元组
tup = (
2,
5,
6,
)
print(tup)
print(type(tup))
print(type((2, 5, 6)))
print(3 * (20 * 3)) # 为表达式
print(3 * (20 * 3,)) # 为元组
tup_0 = tuple([5, 8, 9])
print(tup_0)
tup_1 = tuple((5, 8, 9))
print(tup_1)
tup_0N1 = tup_0 + tup_1
print(tup_0N1)
print(tup_0N1.count(5))
print(tup_0N1.index(8))
# 元组可以嵌套(嵌套元组)
nested_tup = tup, (11, 12, 13)
print(nested_tup)
# 列表中具有保持序列不变性的方法同样适用于元组
print(tup[1])
print(tup[:2])
print(
f"Max value: {max(tup)}; Min vvalue: {min(tup)}; Sum: {sum(tup)};list length: {len((tup))}"
)
# 元组是不可变对象
tup_0N1[2] = (
9999 # 尝试修改项值时,将提示错误,TypeError: 'tuple' object does not support item assignment
)
🡮
(2, 5, 6)
<class 'tuple'>
<class 'tuple'>
180
(60, 60, 60)
(5, 8, 9)
(5, 8, 9)
(5, 8, 9, 5, 8, 9)
2
1
((2, 5, 6), (11, 12, 13))
5
(2, 5)
Max value: 6; Min vvalue: 2; Sum: 13;list length: 3
4.5.3 Dictionaries
字典(Dictionaries)是 Python 内置的一种基本数据结构,与 C++ 中的 Map 和 C# 中的Dictionary<TKey,TValue>均属于一种映射类型,为可变对象。字典语法为{k0:v0,k1:v1,k2:v2,...,kn:vn},其中k为键,v为值,键值对之间:冒号分割,大括号括起。键的类型可以为数值型或者字符串类型等不可变类型。字典是无序的,键值对的位置可能会发生变动。可以把字典理解为键值对(key-value pairs)的集合,但字典的键必须是唯一的。字典的主要用途是通过键存储、提取值。字典的常用操作如下示例。
# 建立字典
score = {"Henry": 99, "Oliver": 86, "Emily": 91, "Lily": 76} # 使用 {} 建立字典
capitals = dict(
China="Beijing", USA="Washington", France="Paris"
) # 使用 dict() 建立字典
# 建立空字典并添加元素
numberNames = {}
numberNames[7] = "seven"
numberNames[9] = "nine"
numberNames[11] = "eleven"
print(f"score={score}\ncapitals={capitals}\nnumberNames={numberNames}")
# 其它建立字典的方式
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
f = dict({'one': 1, 'three': 3}, two=2)
print(a == b == c == d == e == f)
# 访问字典元素
name = numberNames[9]
print(name)
print(f"{capitals["China"]}")
print(
f"{capitals.get("UK","Not Found!")}"
) # 通过键提取元素,如果键不存在则会引发 KeyError 异常,可以使用 get()方法安全访问
print(f"{capitals.get("USA","Not Found!")}")
# 添加或更新键值对
numberNames[11] = "5+6"
numberNames[13] = "thirteen"
print(numberNames)
# 删除键值对——使用 pop() 方法,返回键对应的元素
eleven = numberNames.pop(11)
print(eleven)
# 删除键值对——使用 popitem() 方法,删除并返回最后一个插入的键值对
last_item = numberNames.popitem()
print(last_item)
# 删除键值对——使用 del 关键字
del numberNames[7]
print(numberNames)
# 检查字典是否有给定的键
if "Lily" in score:
print("Lily exists in the score dictionary.")
# 计算字典键值对的数量
print(f"The number of kvps: {len(score)}")
# 遍历字典
for key in score: # 遍历键。或 for key in score.keys()
print(f"{key}: {score[key]}", end=" ")
print()
for value in score.values(): # 遍历值
print(f"{value}", end=" ")
print()
for key, value in score.items(): # 遍历键值对
print(f"{key}:{value}", end=" ")
print()
# 复制字典
copied_score = score.copy() # 为浅复制(shallow copy)
# 更新字典
score_supplementary = dict(Oliver=150, Amelia=59)
score.update(
score_supplementary
) # 用 update() 更新字典,如果已存在键,则更新其元素;否则,增加该键值对
print(score)
copied_score.setdefault(
"Amelia", 59
) # setdefault() 方法仅能增加当前字典中不存在的键。如果传入了已有的键,则不更新,可以避免对原有参数无意中的修改
copied_score.setdefault("Olive", 150)
print(copied_score)
tel1 = {"jack": 4098, "sape": 4139}
tel2 = {"guido": 4127, "sape": 0000}
tel = tel1 | tel2 # 在 Python 3.9 及以后版本中,可以使用 | 操作符合并字典
print(tel)
# 清空字典
tel.clear()
print(tel)
# 嵌套字典
nested_dict = {
"person1": {"name": "Alice", "age": 25},
"person2": {"name": "Bob", "age": 30},
}
print(nested_dict["person1"]["name"])
🡮
score={'Henry': 99, 'Oliver': 86, 'Emily': 91, 'Lily': 76}
capitals={'China': 'Beijing', 'USA': 'Washington', 'France': 'Paris'}
numberNames={7: 'seven', 9: 'nine', 11: 'eleven'}
True
nine
Beijing
Not Found!
Washington
{7: 'seven', 9: 'nine', 11: '5+6', 13: 'thirteen'}
5+6
(13, 'thirteen')
{9: 'nine'}
Lily exists in the score dictionary.
The number of kvps: 4
Henry: 99 Oliver: 86 Emily: 91 Lily: 76
99 86 91 76
Henry:99 Oliver:86 Emily:91 Lily:76
{'Henry': 99, 'Oliver': 150, 'Emily': 91, 'Lily': 76, 'Amelia': 59}
{'Henry': 99, 'Oliver': 86, 'Emily': 91, 'Lily': 76, 'Amelia': 59, 'Olive': 150}
{'jack': 4098, 'sape': 0, 'guido': 4127}
{}
Alice
下表为字典的内置方法。
| 方法 | 解释 |
|---|---|
clear() |
清除字典中所有的键/值项,但是这个方法属于原地操作,并不返回值 |
copy() |
可以复制字典,但是属于浅复制,当复制的字典已有键/值发生改变时,被复制的字典也会随之发生改变。如果增加新的键值对,则不会发生变化 |
get() |
可以根据指定的键返回值,但是如果指定的键在被访问的字典中没有,则不返回任何值 |
items() |
将所有的字典项即键/值对以列表方式返回 |
keys() |
返回字典的键对象列表 |
values() |
返回字典的值对象列表 |
pop() |
根据指定的键返回值,并同时移除字典中对应的键值对 |
popitem() |
移除并返回字典中的最后一个键值对 |
setdefault() |
更新的键值对,其键不在原有字典键列表中,则增加该键值对,否则不增加 |
update() |
用一个字典更新另一字典,键值相同的项将被替换 |
4.5.4 Sets
集合(Sets)最大的特点是集合中不含重复的元素,如果通过序列数据构建集合时存在重复元素,则构建的集合会只保留一个。集合不具有像列表索引值的属性,不能用索引值提取项值。集合元素的唯一性,及集合间的运算,可以非常方便的处理一些元素具有唯一性变化的数据。集合可以用于成员检测、消除重复元素,支持并集(union)、交集(intersection)、差集(difference)和对称差分(symmetric difference)等数学运算。创建集合用{}或set()方法。集合与列表一样为可变序列对象,如果像元组一样变为不可变序列对象,则可以使用 frozenset()构建不可变集合。集合的常用操作如下示例。
# 建立集合。重复的元素会被移除
num1 = {1, 2, 3, 4, 5} # 使用 {} 建立集合
num2 = set([3, 3, 4, 5, 6, 7]) # 使用 set() 函数
num3 = {11, 12, 13, 14, 15}
empty_set = set() # 建立空的集合
print(f"num1={num1}\nnum2={num2}\nnum3={num3}\nempty_set={empty_set}")
# 添加元素
empty_set.add(14) # add() 方法添加单个元素
empty_set.update([15, 16, 17, 18]) # 用 update()方法添加多个元素
print(empty_set)
# 循环遍历集合来访问集合元素
for item in num1:
print(f"{item}", end=" ")
print()
# 删除元素
empty_set.remove(14) # 用 remove() 根据值删除元素。如果元素不存在,会引发 KeyError
print(empty_set)
empty_set.discard(16) # 用discard() 根据值删除元素。如果元素不存在,不会引发错误
print(empty_set)
removed_item = (
empty_set.pop()
) # 随机删除并返回一个元素。由于集合是无序的,无法预测删除哪个元素
print(f"removed item: {removed_item}; empty_set: {empty_set}")
empty_set.clear() # 清空集合
print(empty_set)
# 浅复制
copied_num3 = num3.copy()
# 获取集合的元素数量
print(f"The number of elements in copied_num3 set: {len(copied_num3)}")
# 成员运算符
print(f"If 13 in copied_num3: {13 in copied_num3}")
# 集合到列表
unique_list = list(num3)
print(unique_list)
# 集合的运算
S_1 = set([1, 2, 3, 4, 5])
S_2 = set([4, 5, 6, 7, 8])
S_1_copy1, S_1_copy2, S_1_copy3 = [S_1.copy() for i in range(3)]
S_2_copy1, S_2_copy2, S_2_copy3 = [S_2.copy() for i in range(3)]
print(S_1)
print(S_2)
print("_" * 50)
## 并集
print(S_1 | S_2)
print(S_1.union(S_2))
print("_" * 50)
## 交集
print(S_1 & S_2)
print(S_1.intersection(S_2))
print("_" * 50)
## 差集
print(S_1 - S_2)
print(S_1.difference(S_2))
print(S_2 - S_1)
print(S_2.difference(S_1))
print("_" * 50)
## symmetric对称差集
print(S_1 ^ S_2)
print(S_1.symmetric_difference(S_2))
print("_" * 50)
print("#" * 50)
S_1_copy1.intersection_update(S_2_copy1)
print(S_1_copy1)
S_1_copy2.difference_update(S_2_copy2)
print(S_1_copy2)
S_1_copy3.symmetric_difference_update(S_2_copy3)
print(S_1_copy3)
print("_" * 50)
print(S_1.isdisjoint(S_2))
print(set([1, 2]).issubset(S_1))
print(S_1.issuperset(set([1, 2])))
# frozenset()——不可变(immutable)集合
FS_1 = frozenset([1, 2, 3, 4, 5])
FS_2 = frozenset([4, 5, 6, 7, 8])
print("_" * 50)
print(FS_1.isdisjoint(FS_2))
print(FS_1.difference(FS_2))
print(FS_1 | FS_2)
🡮
num1={1, 2, 3, 4, 5}
num2={3, 4, 5, 6, 7}
num3={11, 12, 13, 14, 15}
empty_set=set()
{14, 15, 16, 17, 18}
1 2 3 4 5
{15, 16, 17, 18}
{15, 17, 18}
removed item: 15; empty_set: {17, 18}
set()
The number of elements in copied_num3 set: 5
If 13 in copied_num3: True
[11, 12, 13, 14, 15]
{1, 2, 3, 4, 5}
{4, 5, 6, 7, 8}
__________________________________________________
{1, 2, 3, 4, 5, 6, 7, 8}
{1, 2, 3, 4, 5, 6, 7, 8}
__________________________________________________
{4, 5}
{4, 5}
__________________________________________________
{1, 2, 3}
{1, 2, 3}
{8, 6, 7}
{8, 6, 7}
__________________________________________________
{1, 2, 3, 6, 7, 8}
{1, 2, 3, 6, 7, 8}
__________________________________________________
##################################################
{4, 5}
{1, 2, 3}
{1, 2, 3, 6, 7, 8}
__________________________________________________
False
True
True
__________________________________________________
False
frozenset({1, 2, 3})
frozenset({1, 2, 3, 4, 5, 6, 7, 8})
下表为集合的内置方法。
| 方法 | 解释 |
|---|---|
add() |
向集合中增加元素 |
clear() |
移除所有元素,清空集合 |
copy() |
浅复制集合 |
pop() |
随机删除并返回一个元素。由于集合是无序的,无法预测删除哪个元素 |
remove() |
移除一个集合元素,如果输入参数值不在集合中,则引发KeyError异常 |
discard() |
移除一个集合元素,如果输入参数值不在集合中,则无变化,也并提示错误 |
update() |
更新集合,输入参数为序列或集合。如果存在相同元素则保持不变 |
S1.uion(S2) |
两个集合的并集运算,同符号| |
S1.intersection(S2) |
,两个集合的交集运算,同符号& |
S1.difference(S2) |
两个(多个)集合的差集运算,同符号- |
S1.symmetric_difference(S2) |
返回两个集合中不重复的元素为一个新集合,同符号^ |
S1.intersection_update(S2) |
同S1.intersection(S2),只是对S1本地更新 |
S1.differnce_update(S2) |
同S1.difference(S2),只是对S1本地更新 |
S1.symmetric_difference_update(S2) |
同S1.symmetric_difference(S2),只是对S1本地更新 |
S.isdisjoint() |
判断两个集合是否包括相同的元素,如果包含返回False,不包含返回True |
S.issubset() |
判断一个数据集是否是另一个的子集,同符号<= |
S.issuperset() |
判断一个数据集是否是另一个的超集(父集),同符号>= |
4.5.5 collections 库
Python 容器(Container)数据类型库collections实现了一些专门化的容器,提供了对 Python 内置容器 dict、list、set和tuple的补充,如下解释和示例,
| 容器 | 解释 | 示例 |
|---|---|---|
|
|
具名元组赋予每个位置一个含义,提供可读性和自文档性,可以用于任何普通元组,能够通过索引和名称获取值 |
|
|
|
有序字典是字典的子类,保持元素的插入顺序。Python 3.7 及以后的版本中,内置字典默认也保持插入顺序,但 OrderedDict 提供了额外的方法 |
|
|
|
默认字典是字典的子类,为字典中的每个键提供默认值,但需要提供一个函数,指明默认值的类型。 |
|
|
|
用于将多个字典(或其他映射类型)组合在一起,形成一个视图,允许在多个字典之间进行查找操作,优先使用第一个字典中的值,如果在第一个字典中找不到,就继续查找下一个字典。适用于需要在多个上下文中查找值的场景,比如配置管理、环境变量、局部和全局变量等 |
|
|
|
为双端队列,支持从两端快速添加和删除元素,适合需要频繁在两端操作的场景,其方法有 |
|
|
|
是一个字典的子类,用于计数可哈希对象。常用于统计元素出现的频率 |
|
[附1]C++ 的标准模板库和泛型编程
标准模板库/泛型库( Standard Template Library,STL)是 C++ 编程语言的一个软件库,其架构主要由 Alexander Stepanov 构建。1979年,他开始提出泛型编程(generic programming)的想法, 旨在通过使用类型参数化的方式来编写通用算法和数据结构,从而提高代码的重用性和灵活性。即在泛型编程中,可以创建与特定数据类型无关的函数或类,从而在不同的上下文中重复使用相同的代码,例如,
#include <iostream>
#include <format>
//定义一个模板函数,用于交换两个变量的值
template <typename T>
void swap(T& a, T& b) {
T temp = a; // 使用临时变量保存值
a = b;
b = temp;
}
int main() {
int x = 5, y = 10;
std::cout << std::format("Before swap: x={};y={}", x, y) << std::endl;
swap(x, y);
std::cout << std::format("After swap: x={};y={}", x, y) << std::endl;
double a = 1.5, b = 3.7;
std::cout << std::format("Before swap: a={};b={}", a, b) << std::endl;
swap(a, b);
std::cout << std::format("After swap: a={};b={}", a, b) << std::endl;
return 0;
}
🡮
Before swap: x=5;y=10
After swap: x=10;y=5
Before swap: a=1.5;b=3.7
After swap: a=3.7;b=1.5
作为强类型语言(strongly-typed language),C++ 要求所有变量都具有特定类型,显示声明或者由编译器推导。但是许多数据结构和算法对多种数据类型都是适用的,因此可以定义函数模板,模板(Templates)是 C++ 中泛型编程的基础,例如swap()函数是一个用template <typename T>定义的一个泛型函数的模板函数(template function),该函数可以接受任何类型的参数,如示例中传入的整型和浮点型数据。
Stepanov 认识到泛型编程的潜力,说服他当时所在通用电气研究和开发部门(General Electric Research and Development)的同事,以泛型编程作为软件开发的基础。在1993年11月,向 ANSI/ISO 委员会(C++ 标准化会议)展示了一个以泛型编程为基础的库(即STL),并于1994年2月正式成为 ANSI/ISO C++ 的一部分。STL 的出现促使 C++ 的编程思维更多朝向泛型编程发展,STL 也不断得到扩展和改进。STL 的的设计概念是泛型编程,允许开发者编写与数据类型无关的代码而提高代码的重用性,同时借助模板把常用的数据结构(要执行操作的数据)及其算法(在数据上执行的操作)分离,对应概念有,
-
容器(Containers),是存储数据的对象,包括序列式容器(sequence containers)和关联式容器(associative containers)。标准的序列式容器包括
vector、deque和list;标准的关联式容器包括set、multiset、map、multimap、hash_set、hash_multiset、hash_map和hash_meltimap。以及使用其他容器作为实现具有特定接口的容器适配器(container adaptors),包括queue、priority_queue和stack。 -
迭代器(Iterators),可以操作数据结构而无需关心其内部实现,以遍历容器中存储的元素,根据操作方式可以分为输入迭代器(input iterators)(只能用于读取值序列),输出迭代器(output iterators)(只能用于写入值序列),前向迭代器(forward iterators)(可以读取、写入和移动),双向迭代器(bidirectional iterators)(类似于前向迭代器,但可以向后移动)和随机访问迭代器(random-access iterators)(可以向后移动)。
-
算法(Algorithms),是要执行的操作,并与数据结构的实现进行了分离。STL 提供了一系列算法,通常以函数模板的形式实现,可以对容器中的数据执行各种操作,例如使用
std::count计算特定值的出现次数,使用std::sort对vector进行排序,使用std::accumulate计算容器元素值总和等。
STL 也提供了函数对象/仿函数(functors),是一个重载了 operator()的类或结构体实例,可以像普通函数一样通过操作符()进行调用,可以包含数据成员,用于存储状态,使得其在调用时能够使用内部数据,并可以通过重载多个operator()来实现不同的行为,例如,
#include <iostream>
#include <vector>
#include <algorithm>
// 定义一个函数对象,用于比较两个整数的大小
class Compare {
public:
// 重载运算符()
bool operator()(int a, int b)const {
return a > b; // 降序排序
}
};
int main() {
std::vector<int> vec = { 5,3,8,6,2 };
// 使用函数对象进行排序
std::sort(vec.begin(), vec.end(), Compare());
std::cout << "Sorted vector in descending order: ";
for (int num : vec) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
🡮
Sorted vector in descending order: 8 6 5 3 2
[附2]时间复杂度
O(1)、O(n)、$O(n^2)$、O(logn)和O(nlogn)是算法分析中时间复杂度(time complexity)术语,具体指算法的执行时间(计算工作量)或空间(计算所需内存空间)需求如何随输入大小(n)的增加而变化。这些术语属于大O表示法(Big O notation),用于描述算法的效率。O 后面括号中的函数指明了某个算法耗时/耗空间与数据增长量之间的关系。其中 n 代表输入数据的量。
-
O(1):常数时间复杂度(常数阶)。最低的时空复杂度,其执行时间(耗时)与输入数据的大小无关,即无论输入数据增大多少倍,执行时间/空间都不变。通过索引访问向量中的元素其时间复杂度即为O(1);哈希算法插入、查找和删除平均情况下时间复杂度也为O(1)。 -
O(n):线性时间复杂度(线性阶)。执行时间随着输入大小 n 的增长而呈现线性增长。例如遍历向量/数组或链表中的所有元素。 -
$O(n^2)$:平方时间复杂度(平方阶)。执行时间与输入大小的平方成正比。例如嵌套循环,及冒泡排序、插入排序和选择排序等。
-
O(logn):对数时间复杂度(对数阶)。执行时间随着输入规模的增加呈对数级增长,即每次处理后数据规模减少到原来的一部分,如数据增大256倍时,执行时间只增大8倍。例如二分查找等。 -
O(nlogn):线性对数时间复杂度(线性对数阶)。通常出现在需要log(n)次分解并且每次分解处理n个元素的情况,如数据增大256倍时,执行时间为$256 \times 8 = 2048$,其复杂度高于线性阶而低于平方阶。
[附3]C++ 容器成员函数地图
下表是C++中不同容器中不同成员函数的对比图:
表 序列式容器成员函数 表引自 cplusplus
| Headers | array |
vector |
deque |
forward_list |
list |
|
|---|---|---|---|---|---|---|
| Members | array | vector | deque | forward_list | list | |
| constructor | implicit | vector | deque | forward_list | list | |
| destructor | implicit | ~vector | ~deque | ~forward_list | ~list | |
| operator= | implicit | operator= | operator= | operator= | operator= | |
| iterators | begin | begin | begin | begin | begin | begin |
| before_begin | ||||||
| end | end | end | end | end | end | |
| rbegin | rbegin | rbegin | rbegin | rbegin | ||
| rend | rend | rend | rend | rend | ||
| const iterators | cbegin | cbegin | cbegin | cbegin | cbegin | cbegin |
| cbefore_begin | ||||||
| cend | cend | cend | cend | cend | cend | |
| crbegin | crbegin | crbegin | crbegin | crbegin | ||
| crend | crend | crend | crend | crend | ||
| capacity | size | size | size | size | size | |
| max_size | max_size | max_size | max_size | max_size | max_size | |
| empty | empty | empty | empty | empty | empty | |
| resize | resize | resize | resize | resize | ||
| shrink_to_fit | shrink_to_fit | shrink_to_fit | ||||
| capacity | capacity | |||||
| reserve | reserve | |||||
| element access | front | front | front | front | front | front |
| back | back | back | back | back | ||
| operator[] | operator[] | operator[] | operator[] | |||
| at | at | at | at | |||
| modifiers | assign | assign | assign | assign | assign | |
| emplace | emplace | emplace | emplace_after | emplace | ||
| insert | insert | insert | insert_after | insert | ||
| erase | erase | erase | erase_after | erase | ||
| emplace_back | emplace_back | emplace_back | emplace_back | |||
| push_back | push_back | push_back | push_back | |||
| pop_back | pop_back | pop_back | pop_back | |||
| emplace_front | emplace_front | emplace_front | emplace_front | |||
| push_front | push_front | push_front | push_front | |||
| pop_front | pop_front | pop_front | pop_front | |||
| clear | clear | clear | clear | clear | ||
| swap | swap | swap | swap | swap | swap | |
| list operations | splice | splice_after | splice | |||
| remove | remove | remove | ||||
| remove_if | remove_if | remove_if | ||||
| unique | unique | unique | ||||
| merge | merge | merge | ||||
| sort | sort | sort | ||||
| reverse | reverse | reverse | ||||
| observers | get_allocator | get_allocator | get_allocator | get_allocator | get_allocator | |
| data | data | data |
表 关联式容器成员函数 表引自 cplusplus
| Headers | set |
map |
unordered_set |
unordered_map |
|||||
|---|---|---|---|---|---|---|---|---|---|
| Members | set |
multiset |
map |
multimap |
unordered_set |
unordered_multiset |
unordered_map |
unordered_multimap |
|
| constructor | set | multiset | map | multimap | unordered_set | unordered_multiset | unordered_map | unordered_multimap | |
| destructor | ~set | ~multiset | ~map | ~multimap | ~unordered_set | ~unordered_multiset | ~unordered_map | ~unordered_multimap | |
| assignment | operator= | operator= | operator= | operator= | operator= | operator= | operator= | operator= | |
| iterators | begin | begin | begin | begin | begin | begin | begin | begin | begin |
| end | end | end | end | end | end | end | end | end | |
| rbegin | rbegin | rbegin | rbegin | rbegin | |||||
| rend | rend | rend | rend | rend | |||||
| const iterators | cbegin | cbegin | cbegin | cbegin | cbegin | cbegin | cbegin | cbegin | cbegin |
| cend | cend | cend | cend | cend | cend | cend | cend | cend | |
| crbegin | crbegin | crbegin | crbegin | crbegin | |||||
| crend | crend | crend | crend | crend | |||||
| capacity | size | size | size | size | size | size | size | size | size |
| max_size | max_size | max_size | max_size | max_size | max_size | max_size | max_size | max_size | |
| empty | empty | empty | empty | empty | empty | empty | empty | empty | |
| reserve | reserve | reserve | reserve | reserve | |||||
| element access | at | at | at | ||||||
| operator[] | operator[] | operator[] | |||||||
| modifiers | emplace | emplace | emplace | emplace | emplace | emplace | emplace | emplace | emplace |
| emplace_hint | emplace_hint | emplace_hint | emplace_hint | emplace_hint | emplace_hint | emplace_hint | emplace_hint | emplace_hint | |
| insert | insert | insert | insert | insert | insert | insert | insert | insert | |
| erase | erase | erase | erase | erase | erase | erase | erase | erase | |
| clear | clear | clear | clear | clear | clear | clear | clear | clear | |
| swap | swap | swap | swap | swap | swap | swap | swap | swap | |
| operations | count | count | count | count | count | count | count | count | count |
| find | find | find | find | find | find | find | find | find | |
| equal_range | equal_range | equal_range | equal_range | equal_range | equal_range | equal_range | equal_range | equal_range | |
| lower_bound | lower_bound | lower_bound | lower_bound | lower_bound | |||||
| upper_bound | upper_bound | upper_bound | upper_bound | upper_bound | |||||
| observers | get_allocator | get_allocator | get_allocator | get_allocator | get_allocator | get_allocator | get_allocator | get_allocator | get_allocator |
| key_comp | key_comp | key_comp | key_comp | key_comp | |||||
| value_comp | value_comp | value_comp | value_comp | value_comp | |||||
| key_eq | key_eq | key_eq | key_eq | key_eq | |||||
| hash_function | hash_function | hash_function | hash_function | hash_function | |||||
| buckets | bucket | bucket | bucket | bucket | bucket | ||||
| bucket_count | bucket_count | bucket_count | bucket_count | bucket_count | |||||
| bucket_size | bucket_size | bucket_size | bucket_size | bucket_size | |||||
| max_bucket_count | max_bucket_count | max_bucket_count | max_bucket_count | max_bucket_count | |||||
| hash policy | rehash | rehash | rehash | rehash | rehash | ||||
| load_factor | load_factor | load_factor | load_factor | load_factor | |||||
| max_load_factor | max_load_factor | max_load_factor | max_load_factor | max_load_factor |
参考文献(Reference):
[1] cplusplus(https://cplusplus.com/).
[2] GeeksforGeeks(https://www.geeksforgeeks.org/).
[3] Microsoft Ignite(https://learn.microsoft.com/en-us/).
[4] Python Documentation(https://docs.python.org/3/contents.html).