[数据检索]GIS 数据库(文件索引与预览)
📚 GIS 数据库(文件索引与预览)· 操作手册
面板:数据库 核心实现:
dm/sqlite_core.py(SQLite 管理)、dm/data_preview.py(文件预览)、tab_database.py(UI) 设计目标:以轻量 SQLite 管理项目中的栅格/矢量/表格/NPZ 等文件的索引、元数据与预览,支持批量导入/查询/编辑/导出/恢复,并与“数据根目录”配合使用实现相对路径存储及跨机器可移植。
① 功能与数据
目的
- 建立可搜索的数据目录(Catalog):统一记录名称、类型、格式、路径、关键词、CRS、几何类型/波段数、范围、NoData、大小、来源、描述、引用及语义分类等字段。
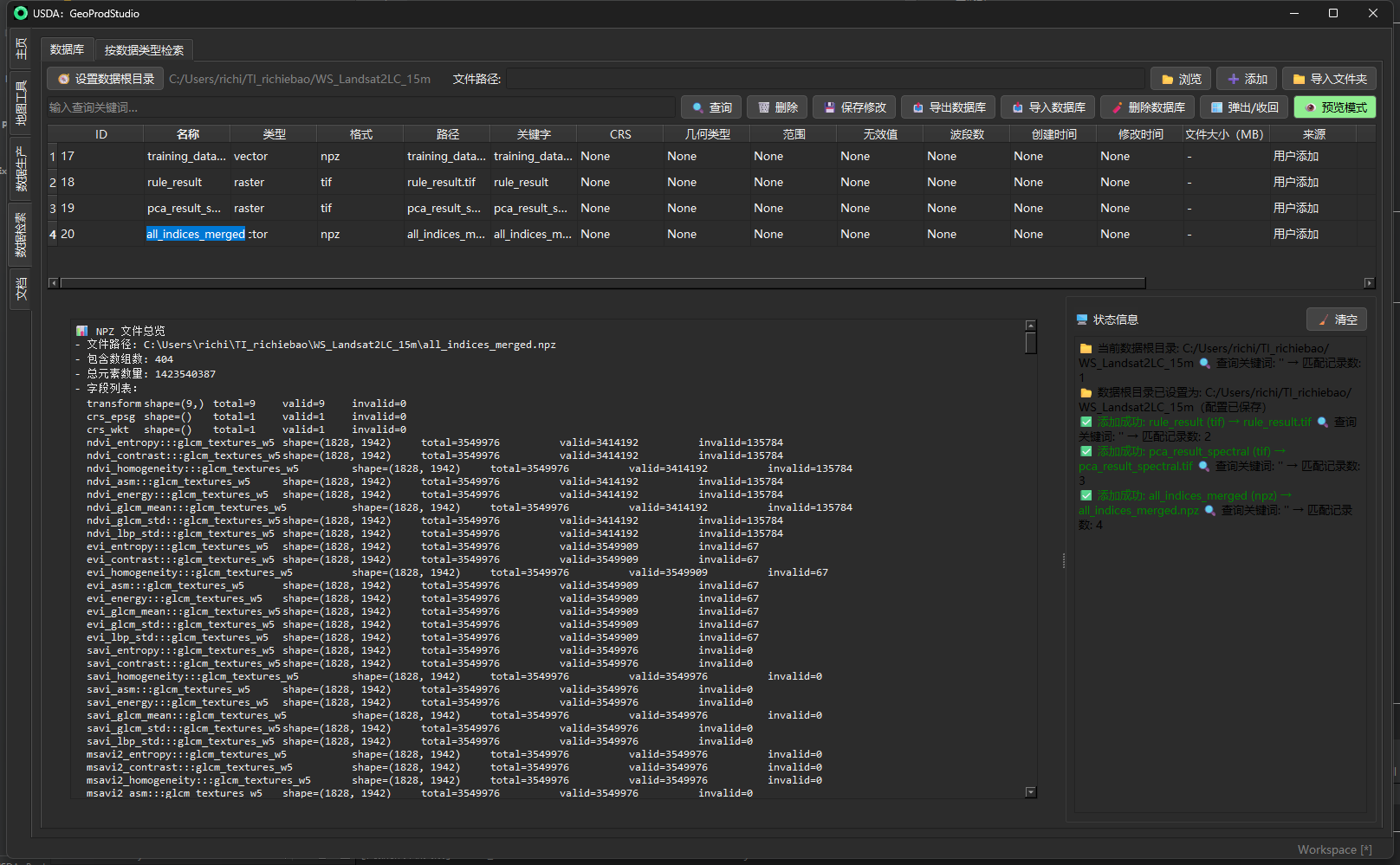
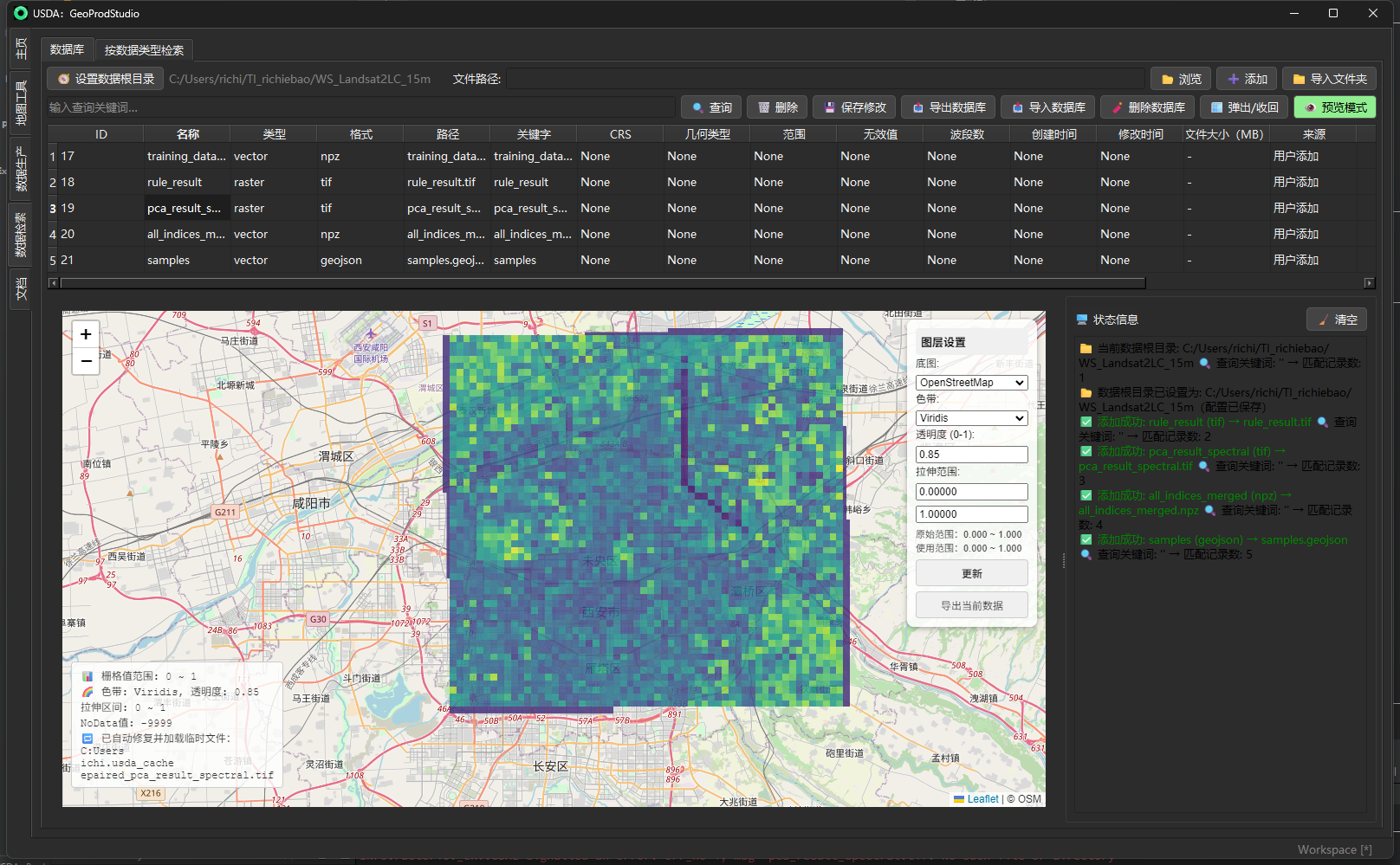
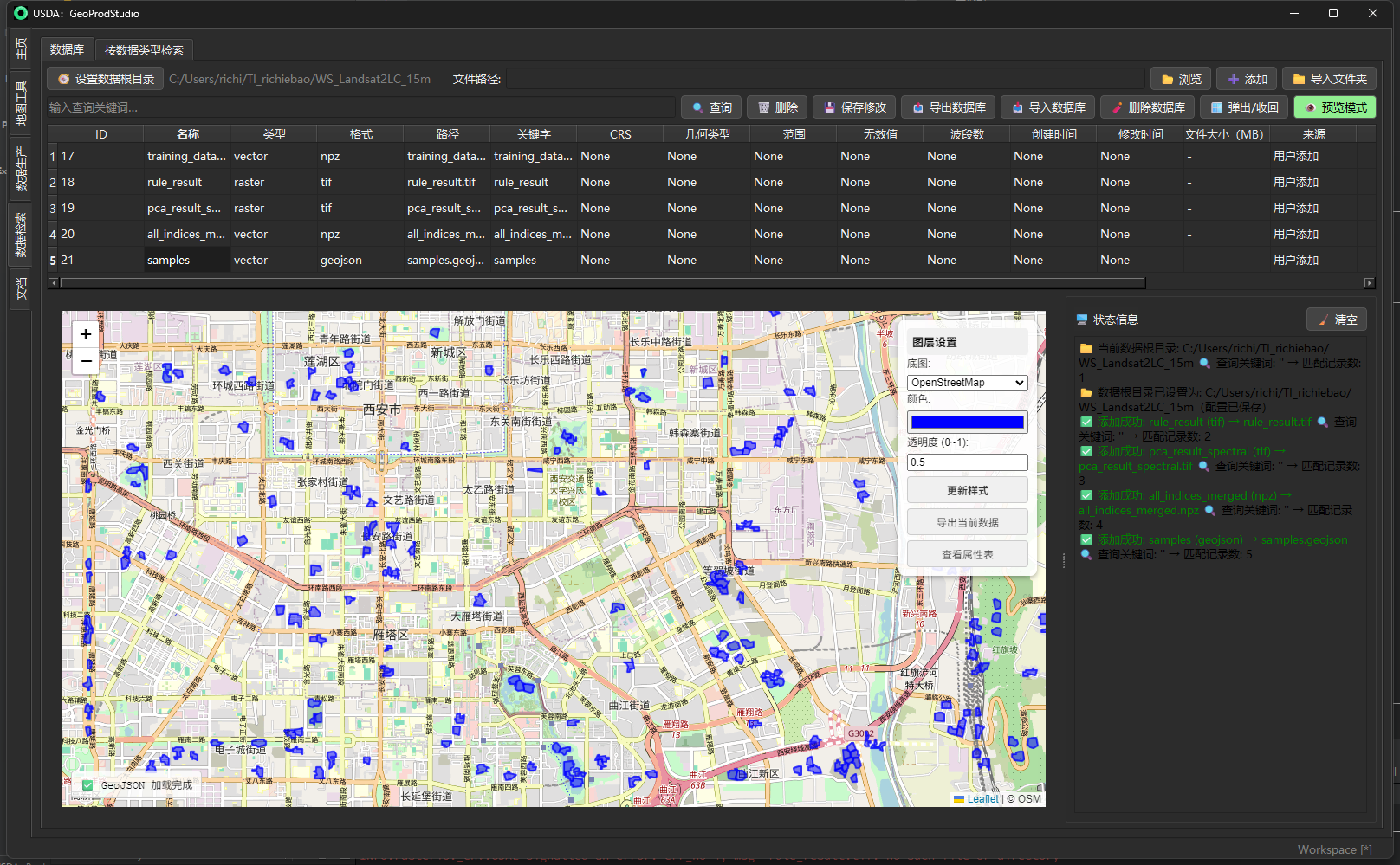
- 一键 预览:CSV/Excel、文本/JSON、矢量(Leaflet 预览与属性表)、栅格(自动拉伸渲染)、NPZ(数组结构/统计)。
- 提供可编辑表格、弹出编辑窗口、导入/导出数据库等工程化操作。
机制 / 实现(概要)
-
SQLite 表结构:
gis_files表含 18 个字段(见下),若表不存在自动创建。 -
相对路径策略:配合“数据根目录
data_root”保存相对路径,提升可移植性(跨盘符/设备)。 -
重复导入防护:同一路径只入库一次;批量导入会跳过重复项。
-
自动元数据抓取:
- 栅格:CRS、波段数、NoData、范围(bounds)。
- 矢量:CRS、几何类型、范围(total_bounds)。
- 统计:创建/修改时间、文件大小(字节)。
-
语义分类(自动打标):基于名称/关键词/描述做关键词匹配,归入“土地覆盖/水文/地形/生态…”等预设类别。
-
预览器:按扩展名分派,支持 CSV/TSV/XLS/XLSX、TXT/JSON/XML、Shapefile/GeoJSON/GPKG、GeoTIFF、NPZ 等。
② 面板与交互
布局
- 顶部工具条:设置/显示数据根目录、单文件添加、导入文件夹、关键词查询、删除/保存、导出/导入数据库、删除数据库、弹出/收回窗口、编辑/预览模式切换。
- 中部表格:
gis_files的可视化清单;双击某行在下方打开预览。 - 底部分栏:左侧预览容器,右侧状态信息(含清空按钮,限制最大宽度避免挤占预览区)。
- 弹出编辑窗口:将表格与工具条独立成外部窗口,便于大屏编辑;关闭时回收并刷新主面板。
常用操作(流程)
- 设置数据根目录 → 自动记入
config.json,后续导入全部使用相对路径存储。 - 添加或导入文件夹 → 自动判别类型/格式、提取元数据、分配语义分类、去重入库;批量导入含进度条,可随时取消。
- 关键词查询 → 在“查询关键词”输入框检索(名称/格式/关键词),回车或点“查询”。
- 双击预览 → 根据文件类型调用对应预览器;矢量支持弹出属性表并可导出 CSV。
- 编辑/保存 → 切换“编辑模式”,修改行内字段,点击“保存修改”批量提交。不可手改
id / file_size。 - 导出/导入数据库 → 复制
.db文件实现备份/恢复;导入会覆盖现有库。 - 删除数据库 → 需二次确认,删除后自动重建空库。
③ 字段与参数(面板字段一览)
| 字段 | 类型 | 示例/默认 | 说明 |
|---|---|---|---|
| 数据根目录 | 目录 | D:/WS_Landsat2LC_Final | 作为相对路径基准;写入 config.json。 |
| 文件路径(添加) | 文件 | …/data/a.tif | 单文件入库(自动转相对路径)。 |
| 导入文件夹 | 目录 | …/data/ | 递归扫描全部文件,带进度条与可取消。 |
| 查询关键词 | 文本 | water / ndvi | 支持名称/格式/关键词模糊匹配。 |
| 预览/编辑模式 | 开关 | 预览/编辑 | 预览:双击打开;编辑:双击可改并保存。 |
| 导出/导入/删除数据库 | 按钮 | — | 备份/恢复/重建。 |
数据库表字段(gis_files)
id, name, type, format, path, keywords, crs, geometry_type, layer_extent, no_data_value, band_count, created_time, last_modified, file_size, source, description, citation, semantic_category。创建时自动确保表存在。
④ 机制 / 实现(训练/预测对应的“执行逻辑”)
本节对应“如何写入/查询/预览/导出”的内部流程,便于排错与二次开发。
-
写入 / 去重
insert(...)写入前先SELECT COUNT(*) WHERE path=?,若已存在则跳过。- 栅格/矢量会尝试读取 CRS / 几何 / 范围 / 波段 / NoData。
- 记录创建/修改时间和文件大小;自动推断语义分类。
-
批量导入
- 遍历目录,按扩展名判别:
tif/tiff → raster,shp/geojson → vector,其他generic。 - 统一转为相对路径,存在即跳过;估算文件大小并再次语义分类。
- 遍历目录,按扩展名判别:
-
查询
- 以关键词模糊匹配
name/keywords/format;无关键词则返回全部。 - UI 显示时将
file_size转换为MB。
- 以关键词模糊匹配
-
更新
- 行内编辑后,通过
update_full(row_id, data_dict)批量提交。禁止手改id/file_size。
- 行内编辑后,通过
-
删除
- 按
id删除记录,不动原始数据文件。
- 按
-
预览(双击)
- 栅格:Leaflet 自动拉伸渲染;
- 矢量:Leaflet 浏览 + “属性表”弹窗(支持导出 CSV);
- CSV/Excel:表格控件载入前 N 行;
- TXT/JSON/XML:只读文本;
- NPZ:列出数组清单、shape/dtype、有效/无效元素统计,并显示前若干行。
⑤ 状态信息(日志与排错)
-
线程安全 UI 日志:使用发射器追加 HTML 彩色行(info/success/warning/error),并提供“一键清空”。
-
常见日志
📁 当前数据根目录: ...:确认相对路径基准。✅ 已导入: path → 语义分类: X:批量导入成功。⚠️ 已存在,跳过: path:去重生效。❌ 导入失败: path → ...:读取失败;常见于损坏文件或驱动缺失。📤 数据库已导出到: ... / 📥 已导入数据库: ...:备份/恢复成功。
⑥ 使用建议(实践优选)
- 务必先设置数据根目录:确保跨设备路径稳定(相对路径),避免后续迁移失联。
- 批量导入前先清理无关文件:尤其是临时缓存/日志;可以显著加快导入。
- 统一命名与关键词:便于语义分类与检索(如
LC08_..._ndvi.tif、hydro_river.geojson)。 - 表内编辑时段落保存:编辑模式下建议按批次“保存修改”,避免误关窗口丢失。
- 矢量属性表较大时:优先使用“查询关键词+双击预览”,必要时再导出 CSV 做离线统计。
⑦ 附:字段含义速查
| 字段 | 含义 |
|---|---|
type |
raster/vector/generic(由扩展名推断) |
format |
tif/tiff/shp/geojson…(扩展名) |
path |
相对路径(相对 data_root);显示时自动还原为绝对路径 |
crs |
坐标参考(EPSG:xxxx / WKT) |
geometry_type |
矢量要素类型(Point/LineString/Polygon…) |
layer_extent |
空间范围(xmin,ymin,xmax,ymax) |
no_data_value |
栅格 NoData 值 |
band_count |
栅格波段数 |
file_size |
字节;UI 中转换为 MB |
source |
数据来源(用户添加/批量导入/爬取等) |
semantic_category |
语义分类(预置词典匹配) |
description/citation |
数据描述与引用信息 |