[数据生产]Landsat-8/9 遥感影像分割解译
🛰️ Landsat-8/9 遥感影像分割解译·操作手册
Version:2.0.0 [2025.12.01]
示例数据下载地址[20.9GB]:https://pan.baidu.com/s/1DTmbzRi0TS1IlLtqalrUTA?pwd=e2tg
$$ \mathrm{NDVI}=\frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{RED}}}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{RED}}} $$
[1] 数据准备
下文对应软件界面“Landsat-土地覆盖(LC)→数据准备”页的 6 个分区(①~⑥),并结合代码实现逐项说明目的、功能/机制、输入输出、参数含义与推荐配置,以及常见日志/错误排查要点。本文档与实现一一对应(DataPreparationPanel,异步任务、日志、参数持久化、波段栈叠与 DEM 合并裁切等),便于研发与使用统一理解。
总览:本步骤产出什么?
- 波段栈叠影像(可选剪裁到项目边界):把所选 Landsat 8/9 多个波段与 QA 像元质量层合成为单个多波段 GeoTIFF,文件名在原始名后附加后缀(如
_7bands),写到模块工作空间。 - DEM 融合与裁切(可选剪裁到项目边界):把多张 DEM 合并(拼接/镶嵌)并在需要时按边界裁切,输出为单张
merged_dem.tif。
两类产物都将被后续的“指数计算、样本过滤、模型训练/预测、结果融合”直接引用。
① 模块工作空间
目的
为当前工程设定一个集中读写目录,后续所有中间结果与最终输出都写入此处,保证可复现与可迁移。
机制/实现
- UI 按钮**“选择…”写入
workspace;参数通过临时配置对象ModuleTempConfig**持久化(键为landsat2LC),在会话间保留。 - 选择成功后即刻在状态信息中记录路径。
输入/输出与参数
| 名称 | 含义 | 取值/格式 | 默认 | 说明 |
|---|---|---|---|---|
工作空间 (workspace) |
当前工程目录 | 文件夹路径 | 空 | 后续所有结果默认写入此处 |
使用建议
- 为每个地区/项目建立独立工作空间(例如:
D:/WS_Landsat2LC/Shanghai_USDA_LC_2020)。 - 建议目录保持无中文与空格,避免 GDAL/驱动兼容性问题。
② Landsat 数据源
目的
把待处理的 Landsat 8/9 数据(压缩包或已解压文件夹)纳入任务列表,可批量异步处理。
机制/实现
-
支持两类来源:
- 压缩包(
.zip/.tar/.gz/.rar); - 包含影像的文件夹(已解压)。
- 压缩包(
-
列表支持增/删;所有路径以
landsat_sources持久化保存。 -
真正执行在“④栈叠参数与执行”。
输入/输出与参数
| 名称 | 含义 | 格式 | 默认 |
|---|---|---|---|
Landsat 压缩包/文件夹列表 (landsat_sources) |
每个元素是一景影像的载体 | 绝对路径 | 空 |
使用建议
- 同一地区、同一年份的多景影像可一次性加入列表,后续并行栈叠,节省时间。
- 解压与否均可;若使用压缩包,栈叠逻辑会在任务中完成必要读取/展开。
③ 分析边界(GeoJSON)
目的
限定运算区域:在栈叠与DEM 合并时可选“只处理边界内”,减少无效像元与计算量。
机制/实现
- 通过“选择…”指定GeoJSON 多边形文件,路径保存为
boundary_path。 - 后续在波段栈叠与DEM 合并任务中按需传入
clip_geojson/clip_path开启裁切。
输入/输出与参数
| 名称 | 含义 | 格式 | 默认 |
|---|---|---|---|
分析边界 (boundary_path) |
裁切/限定范围 | .geojson |
空(不裁切) |
使用建议
- 建议使用投影坐标系且与影像一致的边界;若坐标不一致,底层工具通常会尝试重投影,但为稳妥起见请保持一致。
- 边界应尽量简单/单部件,避免无效自交或洞导致的裁切失败。
④ 栈叠参数与执行(Landsat 波段 → 多波段影像)
目的
对列表中的每景 Landsat 影像完成波段选择、对齐、裁切(可选)与写出,得到一张多波段 GeoTIFF,供指数计算直接使用。
机制/实现(关键点)
-
“执行影像栈叠”会为列表中的每一个输入提交异步任务到
QThreadPool;- 每个任务调用**
stack_landsat_bands**(工具函数); - 通过TaskRunner发出
result/error/finished信号,UI 实时写日志并统计剩余任务数; - 全部完成后输出“🏁 全部 Landsat 栈叠处理完成”。
- 每个任务调用**
-
任务提交前会把临时配置中的
stacked_output_list清空,便于后续模块读取“最新一批产物”。
输入/输出与参数
| 名称 | 含义 | 取值/示例 | 默认 | 说明 |
|---|---|---|---|---|
波段列表 (bands) |
需要合成到同一影像的波段 | B2,B3,B4,B5,B6,B7,QA_PIXEL |
B2,B3,B4,B5,B6,B7,QA_PIXEL |
逗号分隔;与 Landsat 8/9 标准命名一致 |
输出后缀 (suffix) |
写出的文件名后缀 | _7bands/_LC8sel |
_7bands |
用于区分不同栈叠方案 |
裁切边界 (clip_geojson) |
是否按边界裁切 | 见③ | 空(不裁切) | 传入则启用裁切 |
| 输出 | 多波段 GeoTIFF | 写入工作空间 | — | 文件名通常为“输入名+后缀” |
Landsat 8/9 常用波段含义 B2: 蓝、B3: 绿、B4: 红、B5: 近红外(NIR)、B6: SWIR1、B7: SWIR2、
QA_PIXEL: 像元质量掩膜(云/阴影/积雪/填充值等位标记),后续样本过滤与阈值法可直接利用。
推荐配置
- 地物分类的典型最小集:
B2,B3,B4,B5,B6,B7,QA_PIXEL(配合后续指数/纹理); - 如需加粗略云检测,可保留
QA_PIXEL备用;若另有专门云掩膜流程,也可暂不纳入。
日志/错误排查
- “⚠️ 请先选择工作空间。”:未设定①。
- “⚠️ 请至少选择一个 Landsat 文件/文件夹。”:②为空。
- “❌ 栈叠失败:…”:查看源数据是否缺失所选波段、文件损坏、坐标元数据异常;尝试先解压为文件夹再处理。
⑤ DEM 处理(合并与裁切)
目的
把多幅 DEM(如分幅 SRTM/ASTER/ALOS 等)拼接为一张“覆盖研究区的高程影像”,并可选按项目边界裁切,为地形相关特征(坡度/坡向/地形位等)或阴影矫正等预处理提供输入。
机制/实现
- 列表中添加若干
.tifDEM; - 点击“合并 DEM 并裁切”后提交单个异步任务,内部调用**
merge_rasters**; - 写出到工作空间固定文件名
merged_dem.tif;流程结束有“🏁 DEM 合并裁切流程结束”。
输入/输出与参数
| 名称 | 含义 | 取值/格式 | 默认 |
|---|---|---|---|
DEM 文件列表 (dem_files) |
待合并 DEM 影像 | 多个 .tif |
空 |
裁切边界 (boundary_path) |
是否按边界裁切 | 见③ | 空(不裁切) |
| 输出 | 合并(及裁切)后的 DEM | merged_dem.tif(写入工作空间) |
— |
使用建议
- DEM 与影像的空间参考尽量一致(投影/分辨率);若不一致,合并函数通常会重采样/对齐,但建议在数据准备前统一。
- 若后续只在分类中使用指数,不依赖地形特征,也可跳过 DEM 步骤。
日志/错误排查
- “⚠️ 请至少选择一个 DEM 文件。”:未添加 DEM。
- “❌ DEM 合并失败:…”:常见为不同 CRS/分辨率冲突或损坏文件;逐个检查并尝试重投影到统一网格。
⑥ 状态信息(日志)
目的
无阻塞地跟踪各任务(栈叠/合并)的进展、结果与错误,支持一键清空以复用面板。
机制/实现
-
采用线程安全 UI 日志桥(
get_threadsafe_logger),配合 TaskRunner + QThreadPool 的信号槽打印:- 提交任务、单景完成、全部完成;
- 错误堆栈;
- 参数摘要(bands/suffix/是否裁切等)。
-
“🧹 清空”仅清视图,不影响已产出的文件。
运行流程(操作清单)
-
选择工作空间(①)。
-
添加 Landsat 数据源(②),可混合压缩包与文件夹;可移除误选项。
-
(可选)选择分析边界(③)。
-
在“④ 栈叠参数与执行”中:
- 确认波段列表与输出后缀;
- 点击“执行影像栈叠”,观察日志直至“全部完成”。
-
(如需)在“⑤ DEM 处理”中:
- 添加 DEM 列表;
- 点击“合并 DEM 并裁切”,等待完成。
-
在“⑥ 状态信息”中确认所有任务成功,必要时“清空”以继续下一批数据。
参数与默认值一览(便于快速查阅)
| 分区 | 参数键 | UI 标签 | 默认值 | 说明 |
|---|---|---|---|---|
| ① | workspace |
工作空间 | — | 结果写入目录 |
| ② | landsat_sources |
Landsat 数据源列表 | — | 压缩包/文件夹 |
| ③ | boundary_path |
边界(GeoJSON) | — | 可选裁切 |
| ④ | bands |
波段列表 | B2,B3,B4,B5,B6,B7,QA_PIXEL |
逗号分隔 |
| ④ | suffix |
输出后缀 | _7bands |
写出文件名标记 |
| ⑤ | dem_files |
DEM 文件列表 | — | .tif 多选 |
| ⑤ 输出 | — | merged_dem.tif |
— | DEM 合并裁切结果 |
质量与性能建议
- 批处理:多景影像在“④”会被并行化到线程池;大量任务时请关注内存/IO 峰值。
- QA_PIXEL:建议保留,用于后续云/阴影/积雪过滤;如自行实现云掩膜也可在后续步骤进行。
- 命名与版本:通过
suffix清晰区分不同方案(如_7bands_clip、_8bands_sr等)。 - 可复现性:项目内统一保留工作空间与边界文件,保证他人能一键重跑。
[2] 指数计算
① 数据选择
目的
在不做任何计算的前提下,仅选择用于指数计算的输入栈影像(基准/参考)及输出位置,确保后续能一次性批量对所选影像计算指数。此步骤不触发任何指数计算。
机制 / 实现要点
- 面板提供对单个基准栈影像与多个参考栈影像的选择;这些路径在后续指数计算中被逐一读入并计算所选指数,产出对应
.npz字段。 - 选择仅建立“待处理清单”,不会产生计算或磁盘写入(计算发生在后续指数计算步骤中)。
- 波段必须为反射率尺度且满足 L8/9 映射。波段符号遵循 L8/9 栈影像映射:
BLUE=B2, GREEN=B3, RED=B4, NIR=B5, SWIR1=B6, SWIR2=B7。
输入 / 输出与参数(面板字段一览)
| 字段 / 控件 | 类型 | 必选 | 说明 / 取值规则 | 操作要点 / 按钮 | 示例值(与界面一致风格) |
|---|---|---|---|---|---|
| 模块工作空间 | 文件夹路径 | 是 | 作为当前工程的集中读写目录;后续 .npz/.tif 等统一写入此处的子路径 |
右侧 “浏览” 选择文件夹 | D:/WS_Landsat2LC_Val/训练样本25.9.12/Shanghai_USDA_LC_2020 |
| 基准栈影像 | GeoTIFF(单文件) | 是 | 作为几何/投影与波段映射的参照影像;建议为已裁剪/统一分辨率的 7 波段(B2–B7 + QA_PIXEL 可存在但本步不使用) | 右侧 “浏览” 选择单个 .tif |
…/LC08_L2SP_…_B2B3B4B5B6B7QA_PIXEL_7bands_clipped.tif |
| 参考栈影像(可多选) | GeoTIFF 列表 | 否 | 0–N 个与基准同域、同分辨率、同投影的多时相影像;用于在后续步骤对每一景分别计算指数 | 下拉框显示当前选择;“添加” 逐个加入,“浏览” 替换当前项,“移除” 删除当前项 | …/LC08_L2SP_…_20200816_20200920_…_7bands_clipped.tif 等 |
| DEM 文件 | GeoTIFF 列表 | 否 | 记录用于后续地形指数或其他模块的 DEM;可添加多幅(拼接/裁切在 DEM 面板进行),本步仅登记路径 | 右侧 “选择 DEM” 按钮添加;下拉框列出已选 DEM | …/merged_dem.tif(或多条 DEM 路径) |
| 输出 | — | — | 此步骤不产生任何输出文件(只生成“待处理清单”,实际写入发生在 ② 计算光谱指数) | — | — |
提示
- “基准栈影像”与所有“参考栈影像”应 同一投影/分辨率/裁切范围,且波段顺序遵循 L8/9 映射(
B2=Blu…B7=SWIR2);否则 ② 步光谱指数计算及后续统计/纹理会报尺寸或配准错误。 - DEM 在此处仅登记,真正的 DEM 合并/裁切在 DEM 面板完成;光谱指数计算(②)不直接用到 DEM。
小贴士:若后续还要做 ⑤两两差分/⑥时序统计,建议在同一地区与空间范围下选入多期参考栈,便于后续自动对齐与批处理【】。
使用建议
- 只在此步做路径选择;任何指数计算和参数配置在后续具体指数计算窗口。
- 若区域有明显季节变化,尽量把代表性时相(枯/旺季)都放入参考列表,为后续 dNBR、NDVI_range 等统计提供基础。
② 计算光谱指数(Spectral Indices)
目的
对①中选定的每个栈影像,批量计算所勾选的光谱指数,并写入 .npz(键名小写)。这些指数是随机森林/深度模型分割解译的核心输入特征(植被/水体/城市裸地/扰动等)。
机制 / 实现要点
- 每个指数均按 L8/9 波段映射直接用像元比值/组合计算;所有除法都通过
safe_index(numer, denom)完成:当分母绝对值 ≤ 1e-5 时返回NaN,避免被 0 除并在后续统计中自动忽略。 - 指数清单在 UI 中可逐项添加/移除,候选包含植被/水体/建成区/干旱扰动/其它(含 NDSI);指数说明对常见条目给出简释。
- 计算过程中逐条输出进度与完成提示(“▶️ 计算 … / ✅ 完成 …”),便于监控批处理状态。
输入 / 输出与参数(面板字段一览)
| 字段 / 控件 | 类型 | 必选 | 说明 / 取值规则 | 操作要点 / 按钮 | 输出 / 副作用 | 示例值(界面风格) |
|---|---|---|---|---|---|---|
| 已选光谱指数 | 列表 | 是 | 显示当前将要计算的指数集合(顺序不影响结果) | 选中后可配合“移除 » / 全部移除 »” | 决定 .npz 中写入的字段 |
MSAVI2, ARVI, GNDVI, NDWI, MNDWI, AWEI_SH, AWEI_NSH, WRI, NDPI … |
| 指数候选 | 下拉框 | 否 | 从候选库选择单个指数名称 | 右侧 “« 添加” 将所选加入列表;“« 全部添加” 一键加入全部 | — | 右上默认 NDVI |
| 移除 » / 全部移除 » | 按钮 | 否 | 从“已选光谱指数”中删除选中项 / 清空全部 | 先在列表中选中后点击 | — | — |
| 指数说明 | 文本(只读) | 否 | 提示 L8/9 波段映射及常见指数的公式与典型阈值 | 随面板滚动查看 | — | L8/9: BLUE=B2, GREEN=B3, RED=B4, NIR=B5, SWIR1=B6, SWIR2=B7;NDVI, EVI… |
| 保存到 | 文本框(路径) | 是 | 选择输出文件名(.npz)。如①中含多景输入,程序会基于此自动派生各影像的输出名(如 _base_日期.npz / _ref_日期.npz) |
右侧 “选择保存路径” 打开文件对话框 | 产生 1∼N 个 .npz(按①的数据清单逐一写出;键名为所选指数的小写) |
D:/WS_…/Shanghai_USDA_LC_2020/spectral_indices.npz |
| 开始计算光谱指数 | 按钮 | 是 | 触发②的批量计算;进度/日志在面板底部输出 | 计算过程中按钮置灰,完成后恢复 | 按所选指数写入 .npz,并记录到任务列表供后续步骤使用 |
— |
提示
- ②只依据本面板的“已选光谱指数”与“保存到”执行计算;输入影像的选择严格来自①,不在此处配置。
- 输出
.npz的字段名统一为小写(如ndvi, mndwi, ndbi …);若需要导出为 GeoTIFF,请在后续“npz→tif”面板执行。 |
公式库(按功能分组)
记像元反射率为 $\rho_{\lambda}$($\lambda\in{\text{BLUE,GREEN,RED,NIR,SWIR1,SWIR2}}$)。所有比值类指数的理论取值范围约在 $[-1,1]$。实现与参数见各代码段与文档表述。
A. 植被(Vegetation)
-
NDVI
$$ \mathrm{NDVI}=\frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{RED}}}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{RED}}} $$
植被活力/覆盖度首选。
-
EVI
$$ \mathrm{EVI}=2.5\cdot \frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{RED}}}{\rho_{\mathrm{NIR}}+6\rho_{\mathrm{RED}}-7.5\rho_{\mathrm{BLUE}}+1} $$
高覆盖区不易饱和。
-
EVI2
$$ \mathrm{EVI2}=2.5\cdot \frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{RED}}}{\rho_{\mathrm{NIR}}+2.4\rho_{\mathrm{RED}}+1} $$
无蓝波段时的 EVI 近似。
-
SAVI($L=0.5$)
$$ \mathrm{SAVI}=\frac{(1+L),(\rho_{\mathrm{NIR}}-\rho_{\mathrm{RED}})}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{RED}}+L} $$
稀疏植被抑制土壤背景。
-
OSAVI
$$ \mathrm{OSAVI}=(1+0.16)\cdot\frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{RED}}}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{RED}}+0.16} $$
进一步弱化土壤。
-
MSAVI2
$$ \mathrm{MSAVI2}=\frac{2\rho_{\mathrm{NIR}}+1-\sqrt{(2\rho_{\mathrm{NIR}}+1)^2-8(\rho_{\mathrm{NIR}}-\rho_{\mathrm{RED}})}}{2} $$
干旱/裸地干扰下稳健。
-
ARVI
$$ \mathrm{ARVI}=\frac{\rho_{\mathrm{NIR}}-(2\rho_{\mathrm{RED}}-\rho_{\mathrm{BLUE}})}{\rho_{\mathrm{NIR}}+(2\rho_{\mathrm{RED}}-\rho_{\mathrm{BLUE}})} $$
抗气溶胶污染场景更稳。
-
GNDVI
$$ \mathrm{GNDVI}=\frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{GREEN}}}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{GREEN}}} $$
对叶绿素更敏感。
-
NDMI
$$ \mathrm{NDMI}=\frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{SWIR1}}}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{SWIR1}}} $$
植被含水量/湿度。
B. 水体(Water / Shadow)
-
NDWI
$$ \mathrm{NDWI}=\frac{\rho_{\mathrm{GREEN}}-\rho_{\mathrm{NIR}}}{\rho_{\mathrm{GREEN}}+\rho_{\mathrm{NIR}}} $$
基础水体指数。
-
MNDWI
$$ \mathrm{MNDWI}=\frac{\rho_{\mathrm{GREEN}}-\rho_{\mathrm{SWIR1}}}{\rho_{\mathrm{GREEN}}+\rho_{\mathrm{SWIR1}}} $$
城市水体更稳健。
-
AWEI_SH
$$ \mathrm{AWEI_{SH}}=\rho_{\mathrm{BLUE}}+2.5\rho_{\mathrm{GREEN}}-1.5(\rho_{\mathrm{NIR}}+\rho_{\mathrm{SWIR1}})-0.25\rho_{\mathrm{SWIR2}} $$
阴影场景水体增强。
-
AWEI_NSH
$$ \mathrm{AWEI_{NSH}}=4(\rho_{\mathrm{GREEN}}-\rho_{\mathrm{SWIR1}})-(0.25\rho_{\mathrm{NIR}}+2.75\rho_{\mathrm{SWIR2}}) $$
非阴影场景水体增强。
-
WRI
$$ \mathrm{WRI}=\frac{\rho_{\mathrm{GREEN}}+\rho_{\mathrm{RED}}}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{SWIR1}}} $$
浅/浑水辅助。
-
NDPI
$$ \mathrm{NDPI}=\frac{\rho_{\mathrm{SWIR1}}-\rho_{\mathrm{GREEN}}}{\rho_{\mathrm{SWIR1}}+\rho_{\mathrm{GREEN}}} $$
水体/阴影与建成区分离辅助。
C. 裸地 / 建成区(Bare soil & Built-up)
-
NDBI
$$ \mathrm{NDBI}=\frac{\rho_{\mathrm{SWIR1}}-\rho_{\mathrm{NIR}}}{\rho_{\mathrm{SWIR1}}+\rho_{\mathrm{NIR}}} $$
城市/裸地增强。
-
UI(Urban Index)
$$ \mathrm{UI}=\mathrm{NDBI}-\mathrm{NDVI} $$
城市 vs 植被区分;实现先算 NDBI/NDVI 再做差。
-
IBI
$$ \mathrm{IBI}=\frac{\mathrm{NDBI}-\frac{\mathrm{NDVI}+\mathrm{MNDWI}}{2}}{\mathrm{NDBI}+\frac{\mathrm{NDVI}+\mathrm{MNDWI}}{2}} $$
不透水面综合指数。
-
DBSI
$$ \mathrm{DBSI}=\mathrm{NDPI}-\mathrm{NDVI} $$
干旱裸地/盐碱地增强。
-
BSI
$$ \mathrm{BSI}=\frac{(\rho_{\mathrm{SWIR1}}+\rho_{\mathrm{RED}})-(\rho_{\mathrm{NIR}}+\rho_{\mathrm{BLUE}})}{(\rho_{\mathrm{SWIR1}}+\rho_{\mathrm{RED}})+(\rho_{\mathrm{NIR}}+\rho_{\mathrm{BLUE}})} $$
裸地—建成区组合。
D. 扰动 / 干旱 / 火烧(Disturbance & Drought)
-
NBR
$$ \mathrm{NBR}=\frac{\rho_{\mathrm{NIR}}-\rho_{\mathrm{SWIR2}}}{\rho_{\mathrm{NIR}}+\rho_{\mathrm{SWIR2}}} $$
火烧迹地/扰动检测。
-
NBR2
$$ \mathrm{NBR2}=\frac{\rho_{\mathrm{SWIR1}}-\rho_{\mathrm{SWIR2}}}{\rho_{\mathrm{SWIR1}}+\rho_{\mathrm{SWIR2}}} $$
对极端干旱/高温更敏感(可作 NBR 补充)。
E. 其它(根据区域需要)
-
NDSI(雪冰)
$$ \mathrm{NDSI}=\frac{\rho_{\mathrm{GREEN}}-\rho_{\mathrm{SWIR1}}}{\rho_{\mathrm{GREEN}}+\rho_{\mathrm{SWIR1}}} $$
雪/冰过滤,仅在有雪季才建议启用。
这些指数对 Landsat 分割解译的作用
下面把常用光谱指数在 Landsat 分割解译中的“作用与要点”按类别逐一说明——侧重它们擅长区分什么、容易混淆什么、适合搭配谁、阈值/范围的经验起点,便于直接落地到规则或作为模型输入时的特征认识。
植被类(Vegetation)
-
NDVI
- 作用:衡量绿植活力与覆盖度的首选指标;最直接地区分“植被 vs 非植被”。
- 优点:直观、稳定、跨地区可迁移性强。
- 局限:高覆盖区容易饱和;受土壤背景、薄云和气溶胶影响。
- 常见范围:水体与阴影多为负或接近 0;荒地 0–0.2;一般草灌 0.2–0.5;林地常见 >0.6。
- 搭配:与 NDBI 组合(UI)强化“城市–植被”的对立;与 NDMI 联用区分干湿植被。
-
EVI
- 作用:在高生物量区域克服 NDVI 饱和,提升林地层次区分。
- 优点:对大气和冠层结构更稳健。
- 局限:对蓝波段噪声敏感;非林区提升有限。
- 搭配:与 NDVI 并用,模型会自动学习两者差异;与 MSAVI2 在干旱–高覆盖场景互补。
-
EVI2
- 作用:蓝波段不可用时的 EVI 替代;在数据源受限项目中保证与 EVI 相近的判别力。
-
SAVI / OSAVI
- 作用:在稀疏植被或土壤背景强的地区更稳定。
- 区别:OSAVI 的常数更小,土壤校正更温和;SAVI 的 L=0.5 适合半干旱。
- 搭配:与 BSI/DBSI 联用,细分“稀疏植被–裸地”过渡带。
-
MSAVI2
- 作用:极稀疏或受裸地强干扰环境下的稳健植被指数。
- 场景:荒漠边缘、采矿区、碎斑绿地。
- 搭配:与 NDVI/EVI 形成“稀疏–高盖度”连续刻画。
-
ARVI
- 作用:在烟雾、沙尘或强气溶胶时增强植被判别稳定性。
- 场景:城郊、火点周边、春秋扬尘季。
-
GNDVI
- 作用:对叶绿素更敏感,能区分作物长势与部分树种差异。
- 搭配:用于细分“农田内部等级”,与 NDMI 联用识别旱情。
-
NDMI
- 作用:刻画植被含水量;对干旱、林火前后和湿地植被敏感。
- 搭配:与 NBR 进行扰动检测;与 NDVI 识别“低绿高水”与“高绿低水”的不同生态状态。
水体/阴影类(Water & Shadow)
-
NDWI
- 作用:基础水体识别;在非城市、植被与水体混布场景有效。
- 局限:城市阴影、深色屋面、柏油路会产生混淆。
- 搭配:城市场景优先用 MNDWI 或 AWEI 进行抑阴强化。
-
MNDWI
- 作用:城市和裸地背景下的稳健水体指数;能有效压制建筑与道路的干扰。
- 搭配:与 NDBI/IBI 联合阈值常可大幅减少“暗屋面→水体”的误判。
-
AWEI_SH / AWEI_NSH
- 作用:阴影场景水体增强(SH)与非阴影场景水体增强(NSH)。
- 场景:高楼阴影、山谷阴影、冬季低太阳高度。
- 使用:在建筑密集或山地峡谷优先考虑;MNDWI 与 AWEI 组合最稳。
-
WRI
- 作用:对浑水、浅水或水–裸地交错的边缘区有补充价值。
- 局限:易受土壤/植被混合像元影响;与 MNDWI 一起用于边缘精修。
-
NDPI
- 作用:利用 SWIR 与 GREEN 的差异来分离水体/阴影与建成区;对暗色屋面误检有一定抑制。
- 搭配:与 NDVI 结合为 DBSI,用于干旱与裸地细分。
城市/裸地类(Built-up & Bare Soil)
-
NDBI
- 作用:建成区、不透水面的主力指数;与 NDVI 方向相反。
- 局限:裸地、明亮土壤也可能高;需和 MNDWI/NDVI联合。
- 阈值起点:>0 往往说明不透水成分增加,但需本区标定。
-
UI(NDBI−NDVI)
- 作用:把“城市增强、植被降低”的双重信息合成一个尺度;对城乡过渡带效果好。
- 搭配:与 MNDWI 共同抑制水体与阴影。
-
IBI
- 作用:综合 NDBI、NDVI 与 MNDWI,进一步突出不透水面并抑制植被与水体。
- 场景:城郊混合地表、建筑与河网并存的区域。
-
BSI
- 作用:抓取裸地光谱特征,区分“裸土/沙地/盐碱地”等非植被亮色地物。
- 局限:在新建工地或裸土地膜覆盖变化大时需本地化阈值。
-
DBSI
- 作用:将干旱特征(NDPI)与植被强度(NDVI)结合,突出干旱、盐碱或稀疏植被的裸地。
- 场景:干旱区、盐湖周边、沙化地。
扰动/干旱/火烧(Disturbance & Drought)
-
NBR
- 作用:森林火烧、严重扰动监测的首选;前后时相做差(dNBR)可直接用于分级评估。
- 搭配:与 NDMI 联合可区分“热扰动–水分减少”和“季节性落叶”等非灾害变化。
- 注意:水体或深阴影也可能降值,需与 MNDWI/AWEI 交叉屏蔽。
-
NBR2
- 作用:对极端干旱、高温或高矿化地表更敏感;作为 NBR 的补充通道。
雪/冰(Snow & Ice)
-
NDSI
- 作用:雪冰掩膜的首要指标;在山区冬季或高原地区可显著降低“雪→水/城”的混淆。
- 注意:仅在确实存在季节雪/冰的区域启用,避免把亮色裸地或盐碱地错判。
组合与使用策略(落地经验)
-
最小可靠组合:NDVI + MNDWI + NDBI (+ NBR)。加上 3×3 或 5×5 、7×7的均值/标准差可显著稳边。
-
城市与阴影复杂区:MNDWI 或 AWEI(按是否阴影选择) + NDBI/IBI + UI;再配 NDVI/NDMI 保证绿地与湿地不被侵蚀。
-
干旱与过渡带:MSAVI2 或 OSAVI + BSI/DBSI;用 NDMI 监视湿度梯度,避免把湿地裸露泥滩当作纯裸地。
-
时序变化:对 NBR、NDVI、MNDWI 等做差分或方差统计,有助于识别烧毁、复绿、季节性水体。
-
阈值与规则(起点,需本区标定):
- 水体:MNDWI > 0 或 AWEI_NSH > 0,且 NDBI < 0。
- 建成区:NDBI > 0 且 NDVI < 0.2。
- 植被:NDVI > 0.5(林地常见 >0.6),NDMI 辅助区分湿润植被。
- 裸地:BSI 高、NDVI 低,且 MNDWI < 0。
- 火烧/扰动:dNBR 明显下降、NDMI 同期下降。
-
常见混淆与化解
- 暗屋面/阴影 ↔ 水体:优先 AWEI 或与 MNDWI 联合;再用 NDBI 或 UI 排除建成区。
- 亮色裸地 ↔ 建成区:NDBI 与 BSI 联用,并检查 NDVI 是否低于阈值。
- 稀疏植被 ↔ 裸地:MSAVI2/OSAVI 能稳定识别稀疏绿斑;加 5×5 均值或 IQR 进一步稳边。
把以上认识转化为模型特征时,建议:以这些核心指数为主干,叠加少量纹理(GLCM 对比度/熵,窗 5)和空间统计(均值/标准差,窗 3/5/7),再交给随机森林或深度模型学习;若做规则分割,则以“水体→建成/裸地→植被→扰动”的顺序设置阈值与排除条件,效果更稳定。
推荐勾选与组合
- 默认勾选(少而精,通用稳健):
NDVI, EVI2, MNDWI, NDBI, IBI, BSI, NDMI, NBR, NDSI;若城市/阴影多,额外勾选AWEI_SH/AWEI_NSH。 - 标准通用包:植被
NDVI,EVI,MSAVI2,NDMI;水体MNDWI,AWEI_SH,AWEI_NSH;城建/裸地NDBI,IBI,BSI,UI,DBSI;扰动NBR;建议叠加纹理/空间统计(win=5,levels=16;w=3/5/7 的 mean/std/iqr/p90)。 - 基础轻量:
NDVI + EVI + MNDWI + NDBI (+NBR)。 - 指数优先级(做空间窗口统计更稳):植被
NDVI > EVI > SAVI/OSAVI > MSAVI2 > GNDVI/ARVI > EVI2;水体MNDWI > NDWI > AWEI_SH > AWEI_NSH > WRI > NDPI;城建/裸地NDBI > UI > IBI > BSI > DBSI;扰动NBR > NDMI > NBR2。
细节与排错要点
- 除零/空值:所有比值通过
safe_index自动规避分母接近 0 的情况(阈值 $1\times10^{-5}$),结果置NaN便于后续统计/掩膜处理。 - 键名大小写:输出
.npz中的键名统一为小写,与 UI 勾选名(大写)不同,载入时注意对应关系。 - 波段映射:确保输入栈的波段顺序与 L8/9 映射一致,否则指数含义会错位。
③ 计算地形指数(Terrain Indices)
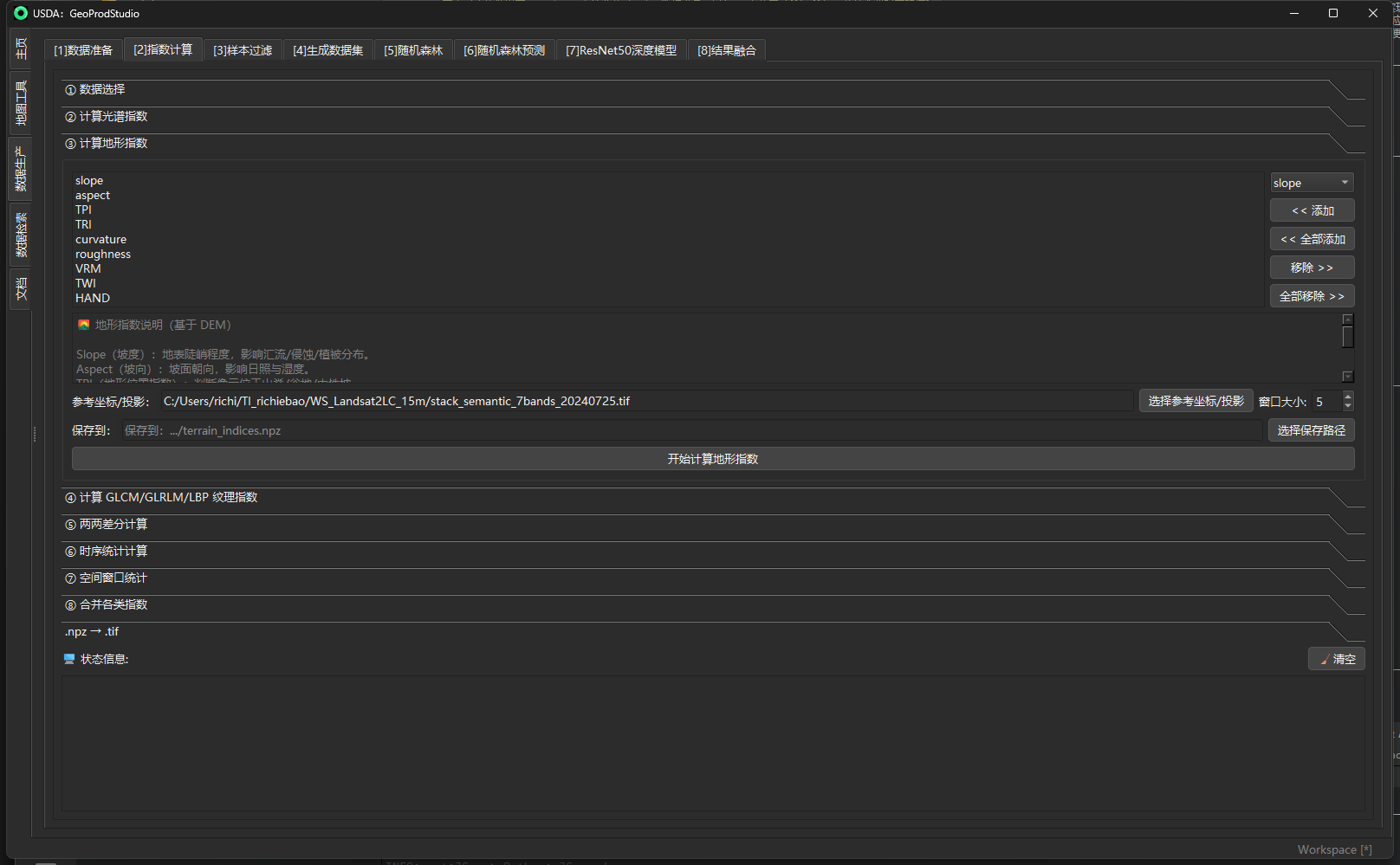
目的
从 DEM 构造地形形态/水文相关特征,增强地物分割对地势、湿度与微地形的判别力:
- 坡度/坡向影响林型、土壤与侵蚀;
- TPI/TRI/粗糙度/VRM/曲率刻画丘陵—谷地—脊线—台地等微地貌;
- TWI/HAND提供汇水与到河道的相对高程约束,对湿地/洪泛地/阶地识别显著有效。
机制 / 实现(关键点)
-
DEM 读取与对齐
- 若提供“参考坐标/投影”,并与 DEM 的 CRS 不一致,则自动重投影到参考网格(与光谱栈一致),保证后续能与光谱/纹理按像元对齐。
- 参考信息既可来自栅格(直接取其网格+CRS),也可来自矢量(取其 CRS,同时用基准栅格确定网格)。
-
稳健窗口与数值处理
- 窗口大小强制为奇数(≥3),并对 NaN 做安全均值/统计,避免边界与缺测带来的伪梯度/异常。
- 对 DEM 的极端动态范围或离群,按统计量自动选择 log 或 z-score 变换,使 TPI/TRI 更稳健。
-
指标批量计算与进度
- 统一调度
compute_all:逐项计算并打点“▶️ … / ✅ 完成 …”,TWI/HAND 还细分子阶段(流向、汇流、传播等)。
- 统一调度
-
保存
- 结果写入
.npz,键名为指标名;与光谱模块一致,同时写入 transform/CRS 对应网格,支持后续直接栅格化。
- 结果写入
输入 / 输出与参数(面板字段一览)
| 字段 / 控件 | 类型 | 必选 | 说明 / 取值规则 | 操作要点 / 按钮 | 输出 / 副作用 | 示例值 |
|---|---|---|---|---|---|---|
| 已选地形指数 | 列表 | 是 | 将要计算的指标集合 | 结合“移除 / 全部移除”维护列表 | 决定 .npz 字段 |
slope, aspect, TPI, TRI, curvature, roughness, VRM, TWI, HAND |
| 指数候选 | 下拉框 | 否 | 从候选库选择单项 | << 添加 / << 全部添加 |
— | slope |
| 移除 / 全部移除 | 按钮 | 否 | 从“已选地形指数”删除选中/全部 | 需先选中列表项 | — | — |
| 地形指数说明 | 文本(只读) | 否 | 简述每个指标的物理含义与场景 | 面板内滚动查看 | — | — |
| 参考坐标/投影 | 路径 | 否 | 参考栅格 .tif或矢量 .shp/.geojson。用于将 DEM 对齐到光谱栈的网格/CRS;未提供时默认采用基准栅格 | “选择参考坐标/投影” | 直接影响重投影与输出的 transform/CRS | …/LC08_…_7bands_clipped.tif |
| 窗口大小 | 整数 | 是 | 影响 TPI/TRI/roughness/VRM/曲率,强制奇数(自动纠正) | 数字框 | 窗口越大越平滑、越强调低频地形 | 5 |
| 保存到 | 路径 | 是 | 输出 .npz 文件路径 |
“选择保存路径” | 写出所选指标与 transform | …/terrain_indices.npz |
| 开始计算地形指数 | 按钮 | 是 | 执行批处理并打印进度 | 完成后按钮恢复 | 生成 .npz |
— |
高级参数(默认即可):HAND 河网阈值(汇流面积像元计数,默认
100)可通过代码接口/配置覆盖,用于控制“河网密度—HAND 效果”;该2.0.0版本为暴漏。
使用建议
- 默认组合:
slope + aspect + TPI + TRI + VRM;若涉及水体/湿地/洪泛地,建议再算TWI + HAND。丘陵/山区分类对TPI/TRI/VRM/curvature敏感。 - 窗口大小:平原/微起伏用
3–5;山地/宽平台面可用7–11。窗口越大越强调地貌大形,越小越突出微地形。 - 参考坐标/投影:优先选择基准光谱栅格作为参考,保证像元级对齐;若给矢量,只改变 CRS,不改变网格。
- HAND 阈值:
50–200为常用范围。阈值低→河网稠密、HAND 影响范围大;阈值高→仅主干河谷显著。 - 性能:TWI/HAND 计算量最大,建议先小范围试跑确认阈值与窗口,再全域批处理。
公式与解释
设 DEM 为 $z(x,y)$,像元分辨率为 $\Delta x,\Delta y$,窗口 $\mathcal{N}$ 为以中心像元 $z_0$ 的 $w\times w$ 邻域。
- Slope(坡度,°)
$$ \text{slope}=\arctan!\left(\sqrt{(\partial z/\partial x)^2+(\partial z/\partial y)^2}\right)\times\frac{180}{\pi} $$
实现:用 np.gradient 估计 $\partial z/\partial x,\partial z/\partial y$ 并换算为角度。
- Aspect(坡向,0°=北,顺时针)
$$ \theta=\operatorname{atan2}(-\partial z/\partial y,\ \partial z/\partial x)\ \ (\mathrm{deg}),\quad \text{aspect}=f(\theta)\in[0,360) $$
其中 $f$ 将数学坐标转换为地理方位(北=0°,顺时针)。实现中按象限做平移与取值修正。
- TPI(地形位置指数)
$$ \mathrm{TPI}=z_0-\frac{1}{|\mathcal{N}\setminus{z_0}|}\sum_{z_i\in\mathcal{N}\setminus{z_0}}z_i $$
实现:窗口内做稳健均值(去极端),边缘像元屏蔽。
- TRI(地形粗糙度指数,Riley)
$$ \mathrm{TRI}=\sqrt{\frac{1}{|\mathcal{N}\setminus{z_0}|}\sum_{z_i\in\mathcal{N}\setminus{z_0}}(z_i-z_0)^2} $$
实现:对差值作 RMS,带离群软裁剪。
- Curvature(曲率,近似拉普拉斯)
$$ \mathrm{curv}\approx\frac{\partial^2 z}{\partial x^2}+\frac{\partial^2 z}{\partial y^2} $$
实现:先求一阶梯度,再以 Sobel 型核近似二阶导并求和,随后 99.9 分位软裁剪。
- Roughness(粗糙度)
$$ \mathrm{roughness}=\max_{z_i\in\mathcal{N}} z_i-\min_{z_i\in\mathcal{N}} z_i $$
实现:窗口内 max-min,对 NaN 做保护。
- VRM(向量粗糙度)
$$ \text{设单位法向量 } \mathbf{n}(x,y)=(n_x,n_y,n_z),\ \overline{\mathbf{n}}=\frac{1}{|\mathcal{N}|}\sum_{\mathcal{N}}\mathbf{n},\ \mathrm{VRM}=1-|\overline{\mathbf{n}}| $$
实现:由坡面梯度推导单位法向量,并在窗口内做 NaN-mean 平均。
- TWI(地形湿度指数,D8)
$$ \mathrm{TWI}=\ln(a)-\ln(\tan\beta) $$
其中 $a$ 为比汇流面积,$\beta$ 为坡角。实现:用 D8 取得流向与像元汇流面积,采用 $\ln(1+a)$ 稳定化与 99.9 分位软上限;$\tan\beta$ 由局部坡度给出。
- HAND(至最近下游河道的相对高程)
$$ \mathrm{HAND}=z-\tilde z,\quad \tilde z=\text{沿 D8 至最近满足 } \text{acc}\ge \tau \text{ 的河段的“河床高程”} $$
其中 $\text{acc}$ 为汇流面积、$\tau$ 为阈值。实现:以阈值提取河网,构建上游拓扑,从河段做反向 BFS 传播河床高程,再与 DEM 相减并做 99.9 分位软裁剪。
日志与排错
-
对齐提示:若出现“DEM 投影与参考不一致,自动重投影以匹配参考栈 …”,表示已为你完成 CRS 对齐。
-
进度日志:
- “▶️ 计算 slope/aspect … / ✅ 完成 slope|aspect”;
- “▶️ 计算 TWI(D8 与坡度) … / ✅ 完成 TWI”;
- “▶️ 计算 HAND(到最近河道的相对高程) … / ✅ 完成 HAND”;
- “💾 保存地形指数到 … / ✅ 地形指数已保存”。
-
结果全 NaN / 极端值:检查窗口是否过小、参考网格是否与 DEM 严重错位;或区域过平坦时 TWI/HAND 可能退化,考虑提高 HAND 阈值、或改用更专业的水文库。
-
速度慢:TWI/HAND 计算最重,可先缩小 ROI 或降低阈值试跑;其余指标基本为窗口卷积级别。
④ 计算 GLCM/GLRLM/LBP 纹理指标
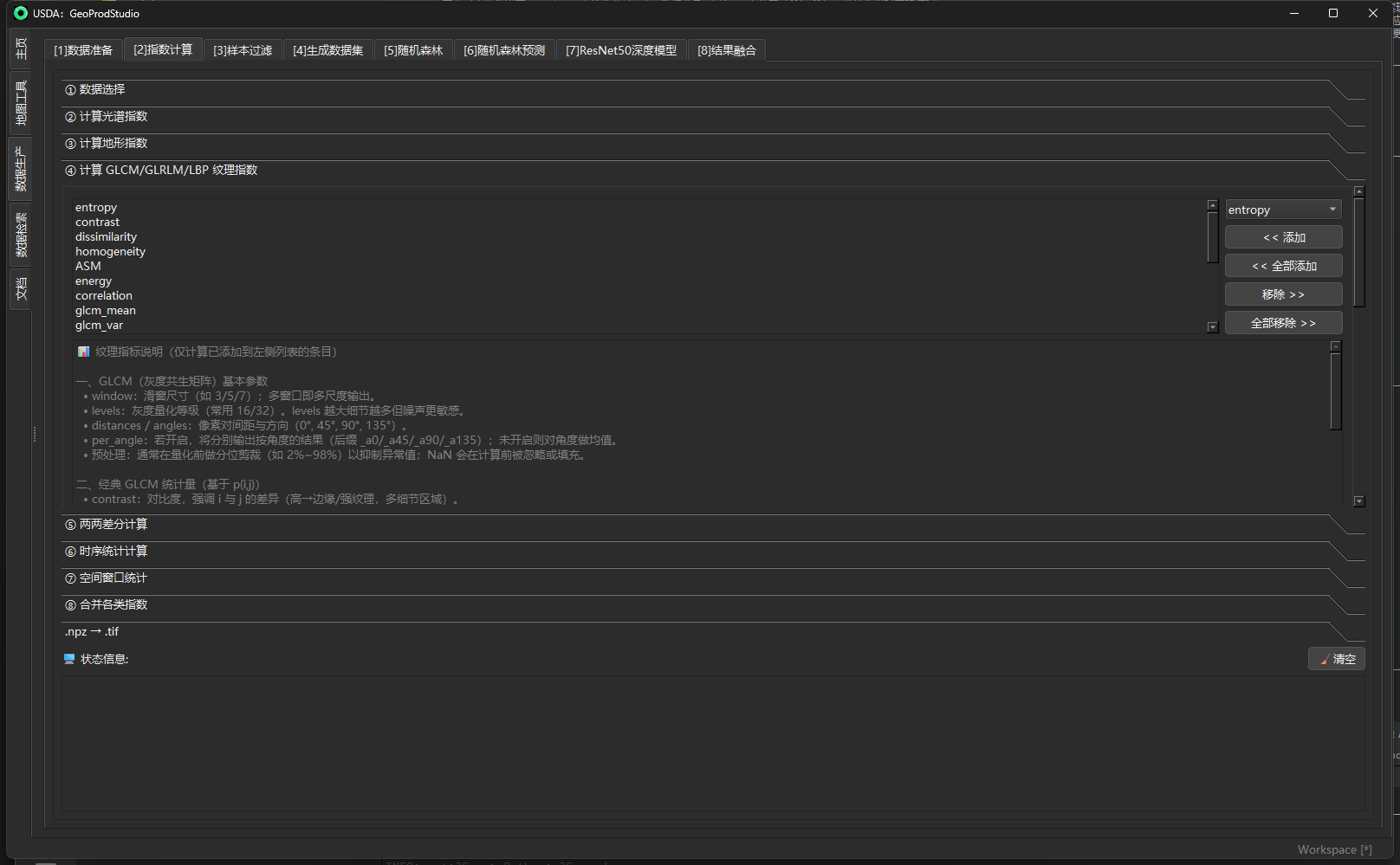
目的
从已计算好的光谱指数面(如 NDVI、MNDWI、NDBI…)上,按滑动窗口提取三类纹理特征:
- GLCM(灰度共生矩阵)经典属性与扩展统计,用于度量局部灰度关系与复杂度;
- GLRLM(灰度游程矩阵)用于度量纹理“块状/细碎”的连续性;
- LBP(局部二值模式)用于捕捉微结构/边缘。
面板支持单类或多类组合输出,并可选择按角度分别输出,以保留各向异性信息(输出键名自动带
_a0/_a45/_a90/_a135后缀)。
机制 / 实现(关键点)
-
输入与量化 读取一个或多个
.npz(来自“② 计算光谱指数”),取所选指数为二维数组;对每幅数组进行全局分位剪裁(默认 2%~98%)后量化到levels个灰度级(uint8),并保留有效像元掩膜。其后所有纹理计算均在窗口内完成,结果与输入同尺寸。 -
GLCM(共生矩阵) 对每个像元,取
size×size窗口,按distances与angles生成 GLCM(对称、归一化),计算所选属性;若未开启 per_angle,则对多角度/距离做均值,若开启则逐角度输出独立结果(如entropy_a90)。 -
GLRLM(游程矩阵) 沿每个方向扫描窗口的像元序列,统计同灰度的连续长度分布并形成矩阵 R(gray, run_length),据此计算 SRE/LRE/GLN/RLN/RP。支持按角度分别输出或对角度取均值。
-
LBP(局部二值模式) 用
P/R/method参数生成 LBP 编码,对窗口内有效像元的 LBP 直方图计算统计量(mean/std/entropy/uniform_ratio)。默认P=8,R=1,method='uniform'。 -
批处理与保存 支持多尺度窗口(如
3,5,7)循环计算;每个尺度独立写出.npz,键名形如ndvi_entropy、ndvi_entropy_a45或ndvi_entropy_w5(多尺度差分另有专门步骤)。
输入 / 输出与参数(面板字段一览)
| 字段 / 控件 | 类型 | 必选 | 说明 / 取值规则 | 操作要点 / 按钮 | 输出 / 副作用 | 默认/示例 |
|---|---|---|---|---|---|---|
| 选择光谱指数用于纹理计算 | 列表 | 是 | 参与纹理提取的光谱指数(来自②的 .npz 字段名;大小写不敏感) |
右侧“« 添加 / « 全部添加”“移除 » / 全部移除 »”维护 | 决定输出里出现的前缀,如 ndvi_entropy |
NDVI, MNDWI, NDBI, IBI, NDMI, BSI, NBR… |
| 输入光谱 .npz(可多选) | 路径或列表 | 是 | ②步骤生成的一个或多个 .npz;同名字段以先出现者优先 |
“浏览添加 / 移除 / 全部移除” | 批处理并整合写出到同一结果文件 | …/spectral_indices_base_20200816.npz |
| 已选纹理指标 | 列表(多选) | 是 | 将要计算的纹理指标集合;顺序不影响结果 | 先选中条目,再用“移除 » / 全部移除 »” | 决定 .npz 中写入的纹理字段 |
entropy, contrast, homogeneity, correlation, glcm_var, glrlm_sre, glrlm_lre, glrlm_gln, glrlm_rln |
| 纹理指标候选(下拉) | 下拉框 | 否 | 从候选库选单个指标 | **“« 添加 / « 全部添加”**加入到左侧列表 | — | 见下一行 |
| 候选全集(供选择) | — | — | GLCM:entropy, contrast, dissimilarity, homogeneity, ASM, energy, correlation, glcm_mean, glcm_var, glcm_std;GLRLM:glrlm_sre, glrlm_lre, glrlm_gln, glrlm_rln, glrlm_rp;LBP:lbp_mean, lbp_std, lbp_entropy, lbp_uniform_ratio |
— | — | — |
| 纹理指标说明 | 文本(只读) | 否 | 展示 L8/9 波段映射、各指标含义与常见用途;仅说明,不在此处改参数 | 面板中滚动查看 | — | — |
| 保存到 | 路径 | 是 | 输出 .npz 文件名(单尺度写一个文件;多尺度会自动派生后缀) |
“选择保存路径” | 写出纹理结果与 transform/CRS |
…/glcm.npz |
| 窗口大小(逗号分隔) | 文本(整数列表) | 是 | 滑窗尺寸集合,奇数,如 3,5,7;多尺度将循环计算并分别写出 |
— | 多尺度时会生成如 …_w5.npz / …_w7.npz 或键名附 _w5/_w7 |
5,7 |
| 灰度等级 Levels | 整数 | 否 | 灰度量化级数(GLCM/GLRLM 用),常用 16 或 32 |
— | 级数越高越细致但更敏感 | 16 |
| 按角度分别输出(per_angle) | 复选 | 否 | 勾选后每个方向分别输出:键名追加 _a0/_a45/_a90/_a135;不勾选则对角度取均值 |
— | 文件体量↑;可保留方向性 | 关闭 |
| 启用 GLRLM 指标 | 复选 | 否 | 同时计算 GLRLM 的五项指标 | — | 结果键名前缀为 glrlm_ |
关闭 |
| 启用 LBP 指标 | 复选 | 否 | 同时计算 LBP 统计量 | — | 结果键名前缀为 lbp_ |
关闭 |
| LBP 参数 | 参数组 | 否 | P(邻域点数)、R(半径)、method(uniform/ror…) |
下拉选择 method |
影响所有 lbp_* 的结果 |
P=8, R=1, method=uniform |
| 开始计算(GLCM/GLRLM/LBP) | 按钮 | 是 | 触发本面板计算;过程内显示进度并写日志 | — | 生成/更新上面的“保存到”目标 .npz |
— |
补充说明
- 内部默认 distances = [1]、angles = 0°/45°/90°/135°;若勾选“按角度分别输出”,会分别写出四个方向的结果;否则按方向取均值,键名不带角度后缀。
- 输出键名规则示例:
ndvi_entropy、ndvi_entropy_a90(按角度)、ndvi_entropy_w5(多尺度);GLRLM/LBP 类似,如mndwi_glrlm_sre、ndbi_lbp_entropy。 - 如果一次选择了多个输入 .npz,且包含相同指数名,默认以先添加的文件为准(避免重复字段冲突)。
进阶参数(在实现中固定或按默认即可):
distances(默认[1])、angles(默认0°/45°/90°/135°)、quantile_clip=(2,98)(量化前分位剪裁)、block_size=256(分块计算提升稳定性与内存友好)。
公式与解释
下面把④ 计算 GLCM/GLRLM/LBP 纹理指标里的“公式与解释”部分做成一份尽量全面、可直接用于论文/技术报告的说明;不丢失已有解释,并进一步补充其在 Landsat 分割解译中的作用与注意事项。
公式与解释(全面版)
0. 前置定义(统一记号)
- 工作在一幅指数图(如 NDVI)上,取以中心像元为原点的窗口 $\mathcal N$(边长 $w$,奇数),将窗口内灰度/指数值线性量化到 $L$ 个等级:$g\in{0,\dots,L-1}$。
- GLCM 使用距离 $d$ 与方向 $\theta\in{0^\circ,45^\circ,90^\circ,135^\circ}$ 构造灰度共生矩阵
$$ P(i,j;d,\theta)=\frac{1}{Z}\left|{(x,y)\in\mathcal N\mid G(x,y)=i,\ G(x+\Delta x,y+\Delta y)=j}\right| $$
其中 $(\Delta x,\Delta y)$ 由 $d,\theta$ 决定,$Z$ 为归一化常数使 $\sum_{i,j}P(i,j)=1$。若“按角度分别输出”未启用,则对 $\theta$ 取均值后再计算属性。
- GLRLM 沿方向 $\theta$ 统计同灰度的连续长度(游程)得到矩阵 $R(g,r;\theta)$,其中 $r\ge1$。
- LBP 以半径 $R$ 采样 $P$ 个邻点,中心像元灰度 $g_c$,邻点灰度 $g_p$。二值函数 $s(x)=\mathbb{I}[x\ge0]$。
A. GLCM 经典属性与扩展统计
下式默认 $P(i,j)$ 为对称($P(i,j)=P(j,i)$)且归一化的共生矩阵(对四个方向求均值,或按角度分别计算后分别输出)。
- Contrast(对比度)
$$ \mathrm{contrast}=\sum_{i=0}^{L-1}\sum_{j=0}^{L-1}(i-j)^2,P(i,j) $$
解释:度量局部灰度差的强弱;边缘密集、纹理粗糙区域取值高(城建区、烧痕斑块);平滑区(开阔水面、草地)较低。 范围/性质:$[0,\infty)$;对噪声敏感,$L$ 越大、窗口越小越“尖锐”。
- Dissimilarity(不相似度)
$$ \mathrm{dissimilarity}=\sum_{i,j}|i-j|,P(i,j) $$
解释:与 contrast 类似,但惩罚随差值线性增长;对细小对比变化更稳。 建议:分辨低对比细纹理 vs 高对比边界时可与 contrast 互补。
- Homogeneity(同质度/逆差矩 IDM)
$$ \mathrm{homogeneity}=\sum_{i,j}\frac{P(i,j)}{1+(i-j)^2} $$
解释:灰度相近(邻近对角线)时取值高;平滑、水面、均匀农田区域高,城市边缘/林缘低。 范围:$(0,1]$,矩阵全在主对角线时趋近 1。
- ASM / Energy(角二阶矩与能量)
$$ \mathrm{ASM}=\sum_{i,j}P(i,j)^2,\qquad \mathrm{energy}=\sqrt{\mathrm{ASM}} $$
解释:纹理越单一、越规则(如大片均一水体或整齐作物)值越高;复杂/混合区低。 性质:$\mathrm{ASM}\in(0,1]$;能量是其平方根,数值更接近直觉“强度”。
- Entropy(熵)
$$ \mathrm{entropy}=-\sum_{i,j}P(i,j)\log P(i,j) $$
解释:纹理无序度;城市、烧毁杂乱区高,均匀区低。 注意:需对 $P(i,j)=0$ 采用 $0\log0=0$ 约定;与能量/ASM呈负相关。
- Correlation(相关性)
$$ \mathrm{correlation}= \frac{\sum_{i,j}(i-\mu_i)(j-\mu_j)P(i,j)}{\sigma_i\sigma_j},\quad \mu_i=\sum_i i,p_i,\ \ p_i=\sum_jP(i,j) $$
解释:灰度的线性依赖;条带状或方向性强的纹理(道路、垄向)相关性高。 注意:当 $\sigma_i$ 或 $\sigma_j$ 很小(近常数)时数值不稳定,应屏蔽或置 NaN。
- glcm_mean / glcm_var / glcm_std(扩展统计) 令 $g=\frac{i+j}{2}$,有
$$ \mu=\sum_{i,j}g,P(i,j),\quad \mathrm{var}=\sum_{i,j}(g-\mu)^2P(i,j),\quad \mathrm{std}=\sqrt{\max(\mathrm{var},0)}. $$
解释:把共生对看作“局部平均灰度”的分布,$\mu$ 描述明暗偏移,$\mathrm{var}/\mathrm{std}$ 描述灰度离散度;对区分亮裸地/暗水体/阴影等有辅助价值。
GLCM 使用要点
- $L$(量化级):16 稳健、32 更细致;量化前做 2%–98% 分位剪裁可抑制异常。
- 窗口 $w$:越大越平滑、强调低频构造;越小越敏锐、易噪声。
- per-angle:均值≈旋转不变,分角度保留各向异性(道路/河流/坡向)。
B. GLRLM 指标(基于游程矩阵 $R(g,r)$)
令 $p_r=\sum_g R(g,r)$(长度为 $r$ 的总游程数), $p_g=\sum_r R(g,r)$(灰度为 $g$ 的总游程数), $N_r=\sum_{g,r}R(g,r)$(窗口内游程总数), $N_p$ 为窗口有效像元数。
- SRE(Short-Run Emphasis,短游程强调)
$$ \mathrm{SRE}=\frac{\sum_{r}\frac{p_r}{r^2}}{N_r} $$
解释:短游程多(纹理细碎、斑驳)时增大;城镇屋面、碎斑耕地常高。
- LRE(Long-Run Emphasis,长游程强调)
$$ \mathrm{LRE}=\frac{\sum_{r}p_r,r^2}{N_r} $$
解释:长条或大片连续区(如水面、大片林地、整齐垄向)取值高;与 SRE互补。
- GLN(Gray-Level Non-uniformity,灰度不均匀性)
$$ \mathrm{GLN}=\frac{\sum_{g}p_g^2}{N_r} $$
解释:灰度分布越集中越大;可识别单色背景或强分区结构。
- RLN(Run-Length Non-uniformity,长度不均匀性)
$$ \mathrm{RLN}=\frac{\sum_{r}p_r^2}{N_r} $$
解释:游程长度越集中(多为相似的块长/条长)越大;整齐作物、规则建筑区高。
- RP(Run Percentage,游程比例)
$$ \mathrm{RP}=\frac{N_r}{N_p} $$
解释:每像元平均可形成的游程数;可粗描纹理密度与边界数量。
GLRLM 使用要点
- 与 GLCM 的“差异/均匀”互补:SRE/LRE 直接反映结构尺度;GLN/RLN 反映灰度/长度的集中度。
- 对道路/河流/条带的方向性更敏感;与“分角度输出”一起使用时效果更好。
C. LBP 统计(基于局部二值模式直方图)
- LBP 基码(以“uniform”方法为例)
$$ \mathrm{LBP}{P,R}= \sum{p=0}^{P-1} s(g_p-g_c),2^p,\qquad s(x)= \begin{cases} 1, & x\ge 0 \ 0, & x< 0 \end{cases} $$
对得到的 $\mathrm{LBP}$ 码做*旋转等价与“均匀模式”*合并(模式中 0→1 或 1→0 的跳变次数 $\le 2$ 记为均匀),其余归为一类。统计直方图 $H(k)$,归一化 $p_k=H(k)/\sum H$。
- lbp_mean / lbp_std
$$ \mathrm{mean}=\sum_k k,p_k,\qquad \mathrm{std}=\sqrt{\sum_k (k-\mathrm{mean})^2p_k} $$
解释:度量模式分布的中心与离散;对细颗粒表面(裸地)、粗颗粒屋面等有区分。
- lbp_entropy
$$ \mathrm{entropy}=-\sum_k p_k\log p_k $$
解释:LBP 模式的无序度;微结构越复杂越高(城市复合区 > 均匀草地/水面)。
- lbp_uniform_ratio
$$ \mathrm{uniform_ratio}=\frac{\sum_{k\in\mathcal U}H(k)}{\sum_k H(k)} $$
其中 $\mathcal U$ 为“均匀模式”集合。 解释:反映区域纹理的“有序/规则”程度;整齐垄向、规则屋顶更高;碎斑林地、灌丛更低。
LBP 使用要点
- 推荐参数:$P=8$、$R=1$、
method='uniform';对更大结构可取 $R=2$ 或 3。 - 与 GLCM 的 contrast/entropy 搭配可同时刻画强边界与微结构。
分割解译中的综合建议(从公式到应用)
- 水体/均一地表:homogeneity↑、energy/ASM↑、entropy↓、contrast/dissimilarity↓、LRE↑、SRE↓。
- 城市/建成区:contrast↑、entropy↑、SRE↑、GLN/RLN 依屋顶/街区规则性而变;LBP-entropy↑。
- 林地/灌丛:entropy 中等偏高,contrast 中等;若针阔混交、扰动强则 entropy/SRE 同升。
- 农田(有垄向):correlation(分角度)↑、LRE↑、lbp_uniform_ratio↑;若多作物交错,GLN↑。
- 裸地/沙砾:LBP-std/entropy 区分粗颗粒 vs 细颗粒;GLCM-var 对“亮度起伏”较敏感。
为了稳健:量化级 $L=16$ 起步、窗口 $w=5/7$;若要方向性,启用“按角度分别输出”;多尺度(3/5/7)+ 对同一指数的 GLCM 与 LBP/GLRLM 组合,通常能显著提升 Landsat 分割的边界稳定性与类别可分性。
使用建议
-
指标选择
- GLCM:
contrast + entropy区分强纹理;homogeneity/energy识别平滑区。 - GLRLM:
sre/lre区分细碎 vs 大块;gln/rln看均匀性;rp看结构密度。 - LBP:
entropy / uniform_ratio识别局部微结构与有序纹理(道路网格、作物垄向)。
- GLCM:
-
窗口大小:常用
3/5/7;地物尺度大可用9/11(更平滑更慢)。多尺度一起算再做差分/统计,往往显著提升区分度。 -
levels(量化级):
16更稳健、抗噪;32可保留更多细节,前提是做了分位剪裁与掩膜。 -
per_angle:广域分类建议角度均值(稳);若要刻画各向异性(道路、河流、垄向、山脊谷地),开启按角度输出。
-
与光谱的组合:参照“光谱指数 × 纹理特征配对矩阵”,如 NDVI × GLCM 熵/对比度、NBR × LRE、城市类可叠加 LBP。
日志与排错
-
常见日志 “▶️ 计算纹理:{index} … / 💾 保存至:… / ✅ 已保存” 等进度与完成提示。多尺度会逐尺度打印。
-
结果全 NaN 多因输入指数全是空值或常数、或窗口中被掩膜;检查
.npz字段是否存在且非常数,确认分母非 0(指数计算阶段)。 -
维度/对齐报错 多来源
.npz合并时启用了首个优先策略;如形状不一致会跳过并记录来源与形状,检查数据是否同一网格与裁切范围。 -
速度/内存 纹理计算按块处理(
block_size=256)并逐窗口循环,已尽量内存友好;指标越多、窗口越大、per_angle 打开→耗时越高。可先小区域试跑或减少角度/等级。
与 Landsat 分割解译的结合
一、总则
-
每个核心光谱指数,最多配 2–3 个纹理(避免维度爆炸)
- 规则:“差异→contrast/entropy,均匀→homogeneity/energy,尺度→SRE/LRE,细粒→LBP”。
-
窗口取 5 与 7 两档;城市/细碎区再加 3;平原/大水面可加 9。
-
GLCM levels=16(稳健),追求精细边界可设 32(需做 2%–98% 分位剪裁)。
-
方向性需求(河流、道路、垄向、沙丘):开启
per_angle并保留a0/a45/a90/a135;否则对角度取均值更稳。 -
命名/管理:同一指数只保留 2–3 个最有效的纹理,再叠加空间统计(如
mean/std_w3,w5,w7),效果显著。 -
优先级层级:先做“核心组合”,再按场景追加“定制组合”,最后再考虑“锦上添花”的特征。
二、核心组合(任何场景都适用)
| 光谱指数 | 推荐纹理(w=5,levels=16;可再算 w=7) | 原理与解译(为什么) | 优先级 |
|---|---|---|---|
| NDVI | ndvi_entropy, ndvi_contrast |
NDVI 高低交错(林缘、混合地物)→ 熵/对比度上升,纯草地/林分内部 → 熵/对比度下降;帮助“植被 vs 非植被”边界稳定 | ★★★★ |
| MNDWI | mndwi_homogeneity, mndwi_energy |
开阔水体纹理单一、平滑 → 同质度/能量高;可抑制“暗屋面/阴影”假水体 | ★★★★ |
| NDBI | ndbi_entropy, ndbi_glcm_var |
建成区材质/几何复杂、亮度起伏大 → 熵/方差高;与 MNDWI/NDVI 联合可减少混淆 | ★★★★ |
| NDMI | ndmi_homogeneity |
湿地/蒸腾旺盛区通常更“均匀”,同质度较高;干旱/扰动则下降 | ★★★ |
| NBR | nbr_contrast, nbr_entropy |
烧毁/扰动区呈高对比、高无序;与 NDMI 同看可区分季节落叶 | ★★★ |
只用上表 +
mean/std_w5,w7(对上述指数本体做 3×3/5×5/7×7 均值和标准差)就能跑出一版稳健的结果。
三、场景化“定制组合”
1) 开阔/城市场景的水体与阴影
-
选光谱:
MNDWI, AWEI_NSH, AWEI_SH(视阴影而定),辅以NDBI抑制城建。 -
配纹理:
mndwi_homogeneity_w5,w7+mndwi_energy_w5(开阔水面平滑)awei_nsh_homogeneity_w5(阴影区抑错)- 长条河流再加:
mndwi_glrlm_lre_w7或mndwi_correlation_a{0/90}(方向性)
-
解译:水体在可见–SWIR 组合下反射率低,空间上低频且规则;阴影虽暗,但在 MNDWI/AWEI 下表现不一致,且纹理更杂乱(熵更高)。
-
优选输出:
mndwi_homogeneity_w5,mndwi_energy_w5,mndwi_glrlm_lre_w7(河网) +awei_nsh_homogeneity_w5(城市)
2) 城市/建成区与裸地
-
选光谱:
NDBI, IBI, UI, BSI;抑水用MNDWI。 -
配纹理:
ndbi_entropy_w5,ndbi_glcm_var_w5(材质混合、边界密集)ndbi_lbp_entropy_w5或ndbi_lbp_std_w5(屋顶、路网的细颗粒/棱边)- 有“街区网格/条带”时:
ndbi_correlation_a{0/90}_w7或glrlm_rln_w7(长度集中性)
-
解译:建成区呈高对比+高无序;LBP 捕捉屋面细结构;相关性/GLRLM 则反映街区方向与块度。
-
优选输出:
ndbi_entropy_w5,ndbi_glcm_var_w5,ndbi_lbp_entropy_w5(必要时加ndbi_correlation_a0_w7)
3) 农田(垄向、种植结构)
-
选光谱:
NDVI, EVI, GNDVI, NDMI。 -
配纹理:
ndvi_correlation_a{0/45/90/135}_w7(行向一致 → 相关性高)ndvi_glrlm_lre_a{方向}_w7(长游程强调,成片垄向/田埂)ndvi_lbp_uniform_ratio_w5(有序纹理比例高)
-
解译:规则耕作 → 方向性强 + 长条纹理;不同作物季节替换,相关性/长游程随之变化。
-
优选输出:
ndvi_correlation_a主方向_w7,ndvi_glrlm_lre_a主方向_w7,ndvi_lbp_uniform_ratio_w5
4) 林地/灌丛与边缘扰动
-
选光谱:
NDVI, EVI, NDMI, NBR。 -
配纹理:
- 林分内部:
ndvi_homogeneity_w5、ndmi_homogeneity_w5(冠层连续) - 林缘/破碎:
nbr_contrast_w5,ndvi_entropy_w5(边界/缺口增多) - 采伐/火烧:
nbr_entropy_w5,w7(斑驳无序)
- 林分内部:
-
优选输出:
ndvi_homogeneity_w5,ndvi_entropy_w5,nbr_contrast_w5(必要时加ndmi_homogeneity_w5)
5) 干旱/裸土/沙地
-
选光谱:
BSI, DBSI, MSAVI2(稀疏植被), NDMI(含水)。 -
配纹理:
- 细颗粒砂砾:
bsi_lbp_std_w5,bsi_sre_w5(短游程多) - 沙丘/风成条带:
bsi_correlation_a主方向_w7,bsi_glrlm_lre_a主方向_w7(长条/方向性)
- 细颗粒砂砾:
-
解译:裸地亮度起伏受粒径和微地形控制 → LBP/GLRLM 最敏感;MSAVI2 区分“稀疏绿斑”。
-
优选输出:
bsi_lbp_std_w5,bsi_sre_w5(有条带再加bsi_lre_a主方向_w7)
6) 雪/冰与高反照地物
- 选光谱:
NDSI。 - 配纹理:
ndsi_energy_w5,ndsi_homogeneity_w5(雪原规则);若有风蚀纹(sastrugi):ndsi_correlation_a{方向}_w7。 - 优选输出:
ndsi_energy_w5,ndsi_homogeneity_w5(需要方向性再加ndsi_correlation_a主方向_w7)
四、优先级与选型清单(给模型/规则各一份)
A) 随机森林/深度模型(每类 8–14 个特征足够)
Tier-1(强烈推荐,先选)
ndvi_entropy_w5,ndvi_contrast_w5mndwi_homogeneity_w5,mndwi_energy_w5ndbi_entropy_w5,ndbi_glcm_var_w5nbr_contrast_w5或nbr_entropy_w5
Tier-2(按场景加)
ndmi_homogeneity_w5(湿地/林地)mndwi_glrlm_lre_w7(河网/水系)ndbi_lbp_entropy_w5(城市细结构)ndvi_correlation_a主方向_w7(农田垄向)bsi_lbp_std_w5(沙砾)
Tier-3(锦上添花)
glcm_mean/var/std(对亮暗偏移/起伏敏感)glrlm_gln/rln(均匀性描述,和上面互补)lbp_uniform_ratio_w5(有序度)
多尺度时,优先保留 w=5 的一套;若显著提升再加 w=7 的同名指标,不建议三档都保留。
B) 规则/阈值法(示范)
- 水体:
(mndwi_homogeneity_w5 > 0.5 AND mndwi > 0)ORawei_nsh_homogeneity_w5 > 0.5;且ndbi < 0。 - 建成区:
(ndbi > 0 AND ndbi_entropy_w5 > 0.3)AND(mndwi < 0.1)。 - 植被:
(ndvi > 0.5) AND (ndvi_entropy_w5 < 2.0);湿地再加ndmi_homogeneity_w5 > 0.4。 - 扰动/烧毁:
(nbr < 0.1 OR dNBR < 阈值) AND nbr_entropy_w5 > 2.5。 - 裸地/沙砾:
(bsi > 0.2) AND (lbp_std_w5 高 OR sre_w5 高)。
阈值需用少量样本标定;纹理阈值可用分位数法(如按类别样本的 70–80 分位选择)。
五、常见混淆的“组合化解”
- 暗屋面/阴影 ↔ 水体:
mndwi_homogeneity(高) +ndbi(低) +awei_nsh(高)三联;阴影区域的entropy往往高于水面。 - 亮裸地 ↔ 建成区:
bsi(高)但ndbi可能中性;用ndbi_entropy与lbp_std判断材质复杂性(城市↑,裸地↓或模式不同)。 - 稀疏植被 ↔ 裸地:
msavi2(高) +lbp_std(低)倾向稀疏植被;纯裸地常lbp_std高、sre高。 - 农田 ↔ 草地:
ndvi_correlation_a主方向、glrlm_lre_a主方向在农田显著更高;草地方向性弱。
六、打包输出建议(便于项目复用)
- 统一前缀:按指数分组导出,如
ndvi_*、mndwi_*、ndbi_*。 - 每组保留 2–3 个纹理(核心 + 场景化 1 个),并在
w5、必要时w7。 - 配一套空间统计(
mean/std_w3,w5,w7)结合 NDVI/MNDWI/NDBI/NBR 四大核心指数。 - 特征总数控制在 20–40 之间(含光谱/地形/纹理/空间统计),对随机森林尤为友好。
用这套组合与优先级,基本可以覆盖 Landsat 的主流地物(植被、水体、城建/裸地、扰动、雪冰)和复杂场景(城市阴影、条带河网、垄向农田、沙丘条纹),既保证解释性,也兼顾模型表现与工程效率。
⑤ 两两差分计算(Pairwise Differences)
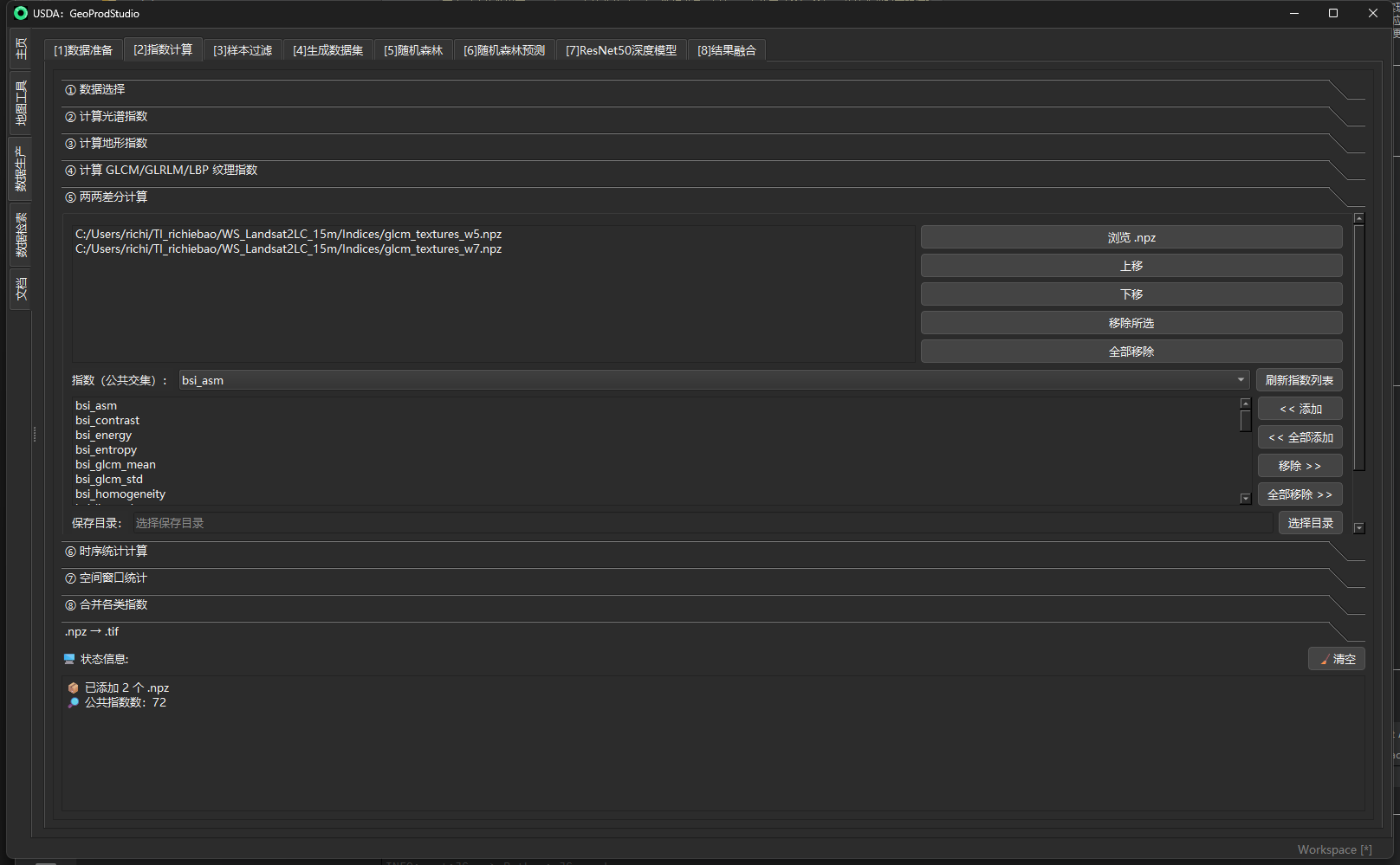
目的
对两期(及以上)已计算好的指标/特征(光谱指数、纹理、地形等都可以,只要在 .npz 里以数组字段存在),按两两组合计算“后时相 − 前时相”的差分图,输出为新的 .npz。本步骤用于变化检测、事件监测与时序差异特征工程(如复绿/退化、涨落水、城市扩张、火烧等级等)。
机制 / 实现
-
函数:
compute_pairwise_differences(npz_paths, selected_indices, out_dir, prefix="DIFF") -
输入:≥2 个
.npz文件路径;UI 提供“公共交集”按钮自动列出这些.npz共同拥有的键(字段名),供你勾选。 -
运算:对每一对文件 $(i,j)$ 计算
out[k+"_diff"] = d2[k] - d1[k](浮点型float32),即后时相减前时相;NaN/掩膜会按 numpy 规则传播。 -
配准:优先把第一个文件内保存的
transform(若存在)附到输出(否则尝试用第二个)以保持空间参考一致。 -
命名:每个组合单独写一个
.npz,文件名"<prefix>__<id2>-minus-<id1>.npz",其中<id*>由原文件名清洗得到(仅保留 A–Z、a–z、0–9、_、-)。例如:DIFF__LC08_20201002_minus_LC08_20200816.npz。 -
对数目:对传入的 $N$ 个
.npz,会生成 $\binom{N}{2}$ 份差分结果(所有两两组合)。 -
日志:
- “▶️ 两两差分:{n} 个文件,前缀={prefix}”
- “▶️ 计算差分:{id2} − {id1}”
- “✅ 已保存:{path} / 🎉 两两差分全部完成。”;缺字段会打印“• 缺少指数:…(已跳过)”。
小提示:UI 上“上移/下移”用于整理列表便于阅读;组合计算与顺序无关(都会算),但解译时请把 id1 视作“前期”,id2 视作“后期”,便于直观理解“谁减谁”。
输入 / 输出与参数(面板字段一览)
| 字段 / 控件 | 类型 | 必选 | 说明 / 取值规则 | 操作要点 / 按钮 | 输出 / 副作用 | 默认/示例 |
|---|---|---|---|---|---|---|
| .npz 列表 | 列表 | 是 | 选择参与差分的 .npz(≥2);可混合光谱、纹理、地形结果,只要键名一致即可 |
右侧“浏览 .npz / 上移 / 下移 / 移除所选 / 全部移除” | 决定参与两两组合的文件集 | …/spectral_base.npz, …/spectral_20200920.npz |
| 指数(公共交集) | 下拉 + 列表 | 是 | 仅可选择所有 .npz 都具有的字段(键名不区分大小写) | “刷新指数列表”拉取交集;“« 添加 / « 全部添加 / 移除 » / 全部移除 »”维护 | 这些键将分别计算差分并以 key_diff 写出 |
ndvi, mndwi, ndbi, ndmi, nbr … |
| 保存目录 | 目录 | 是 | 两两差分结果的输出文件夹 | “选择目录” | 每个组合生成一个 .npz |
…/diffs/ |
| 文件名前缀(Prefix) | 文本 | 否 | 输出文件名前缀 | 直接编辑 | 影响输出文件名,不影响字段名 | DIFF |
| 开始两两差分计算 | 按钮 | 是 | 触发批处理 | — | 写出若干 *.npz;每个包含若干 *_diff 数组与 transform |
— |
输出内容
- 每个输出
.npz内:对所选键 $k$ 写k_diff(数组尺寸与输入一致,float32),并尽量带上transform供后续npz→tif。
公式与解释
通用差分定义
对任意指标(或特征)$I$ 的两期影像 $t_1$(前)与 $t_2$(后),本模块定义:
$$ \Delta I \equiv I_{t_2}-I_{t_1}. $$
- $\Delta I>0$:后期相对前期增强;$\Delta I<0$:后期相对前期减弱。
- 由于大多数比值类指数 $I\in[-1,1]$,理论 $\Delta I\in[-2,2]$(实际多在 $[-1,1]$ 内)。
- NaN(例如云/雪/阴影掩膜造成)会自然传播;建议在指数计算阶段已做遮罩。
下面按指数族给出“差分含义与解译要点”。(所有名称均指两期同名键的差分)
A. 植被相关(如 dNDVI, dEVI, dSAVI/OSAVI, dMSAVI2, dGNDVI, dNDMI)
- dNDVI / dEVI / dGNDVI $\Delta>0$:增绿/复绿(长势变好、播种出苗、雨后返青); $\Delta<0$:褪绿/去植被(采伐、收割、枯黄、建设占地、火烧)。 EVI 在高盖度区更不饱和,dEVI 对林地层次变化更灵敏;GNDVI 对作物氮素/叶绿素变化敏感。
- dSAVI/OSAVI / dMSAVI2 在稀疏植被与裸地干扰强的环境更稳健;$\Delta>0$ 表示稀疏绿斑增强(沙地固沙、绿化);$\Delta<0$ 表示稀疏植被退化。
- dNDMI(植被含水) $\Delta>0$:含水/湿度上升(灌溉、降雨、洪泛湿地扩展); $\Delta<0$:干化(干旱、火前—火后、落叶期)。
B. 水体/阴影相关(如 dNDWI, dMNDWI, dAWEI_SH/NSH, dWRI, dNDPI)
- dMNDWI / dNDWI $\Delta>0$:水体扩张/水位上升(汛期、洪泛、滩涂回水); $\Delta<0$:水退/水面收缩。MNDWI 在城市/裸地背景下更稳健。
- dAWEI_SH / dAWEI_NSH 用于阴影复杂区;$\Delta>0$ 仍指“更像水体”,有助于剔除建筑阴影的假水变化。
- dWRI / dNDPI 作为边缘/浑水辅助:dWRI>0 常伴随浅滩/泥滩暴露;dNDPI 与建成区/阴影分离变化配合使用更稳。
C. 建成区/裸地相关(如 dNDBI, dUI, dIBI, dBSI, dDBSI)
- dNDBI / dUI(= NDBI − NDVI) $\Delta>0$:不透水面增强、城市扩张/加密;$\Delta<0$ 多对应绿化/拆除/还土。UI 同时考虑植被抑制,过渡带判别更稳。
- dIBI 综合水/植被/城市三方信息;$\Delta>0$ 亦偏向城市化增强。
- dBSI / dDBSI $\Delta>0$:更干燥/更裸露(耕翻、风蚀、采挖);$\Delta<0$:表层覆盖或水分增多(覆膜/草被/降雨后)。
D. 扰动/干旱/火烧(dNBR, dNBR2 等)
-
dNBR(本模块约定为 $NBR_{后}-NBR_{前}$) 经典文献多用 $NBR_{前}-NBR_{后}$(烧毁区“正大值”)。而本模块输出是相反号:
$$ \mathrm{dNBR} = NBR_{post}-NBR_{pre}\ \Rightarrow\ \text{火烧/强扰动} \Rightarrow \mathrm{dNBR}\ll 0. $$
解译建议:
- 若习惯“正值代表更严重烧毁”,可在制图时取 $-\mathrm{dNBR}$ 或调整色标;
- 或把“前(pre)”影像放在列表前面、“后(post)”放后面,记住结果为 后−前 即可。 dNBR 数值越负,通常扰动越强;与 dNDMI(负向干化)同看可区分季节性落叶 vs 真扰动。
-
dNBR2 对极端干旱/高温背景更敏感,解释与 dNBR 类似(同样注意符号约定)。
E. 雪/冰(dNDSI)
- dNDSI $\Delta>0$:雪/冰范围扩大;$\Delta<0$:融雪/消退。在高反照裸地(盐碱地、白沙)需与 dMNDWI 或 dBSI 交叉验证。
F. 纹理/地形差分(如 dEntropy、dContrast、dLRE、dSlope…)
-
纹理(GLCM/GLRLM/LBP):
dentropy>0:更无序/更碎斑;dcontrast>0:局部对比增强(新增边界/材质变化);dlre>0:更成片/更长条;dsre>0:更细碎;dcorrelation_aθ>0:方向一致性增强(新增垄向/路网)。 前提:两期必须来自相同窗口/量化参数的纹理计算。
-
地形:通常为静态,不建议做差分;若是不同源 DEM,差分多反映数据误差,而非真实变化。
使用建议(落地到项目)
-
列表按时间升序(前→后)整理,便于快速对应“谁减谁”。
-
只选关键少量指标做差分:推荐 dNDVI、dMNDWI、dNDBI、dNDMI、dNBR(±号见上),必要时再加 1–2 个纹理差分(如
ndbi_entropy_diff)。 -
事件检测模板
- 洪水/水文:
dMNDWI>0(涨水),dNDVI<0(植被淹没/损伤)配合使用。 - 城市扩张:
dNDBI>0或dUI>0;同时dNDVI≤0可作为交叉验证。 - 复绿/造林:
dNDVI>0与dNDMI≥0。 - 耕作/收割:作物季节更替常表现为
dNDVI的显著正/负跳变。 - 火烧/采伐扰动:
dNBR<<0(按本模块约定),dNDMI<0同步干化。
- 洪水/水文:
-
颜色与阈值:先做分位数拉伸(如 2%–98%),再按经验/样本标定阈值;火烧可直接对 $-\mathrm{dNBR}$ 套用常见分级。
-
掩膜:建议在指数阶段就应用云/阴影/雪掩膜(
QA_PIXEL或自建掩膜),避免差分被无效像元污染。 -
导出:差分结果为
.npz,需在 “NPZ→TIF” 面板统一投影与写出栅格便于制图/入库。
日志与排错
- 至少 2 个文件:若报错“至少选择两个 .npz 文件执行两两差分”,请补充或检查文件路径。
- 公共交集为空:说明这些
.npz的键名没有完全一致者;请回到前序步骤统一勾选的指数/纹理或用“刷新指数列表”重取交集。 - 缺少指数:…(已跳过):个别文件缺该字段;不会中断,但该键不会写入当前组合结果。
- transform 读取失败(忽略):个别
.npz未存 transform,不影响数值;建议在前序计算时保留,以便后续栅格化。 - 文件名过长/含特殊符:输出会自动清洗 id 并压缩分隔符(
_),仍建议保持简洁命名。
小结:⑤ 两两差分是把“变化”显式化为特征的关键一步。牢牢记住本模块的方向是“后 − 前”,并在解译时针对不同指数理解“正/负”的物理意义,就能把 NDVI/MNDWI/NDBI/NBR/NDMI 等变化线索稳稳地落到分类或制图上。
⑥ 时序统计计算(TSA)
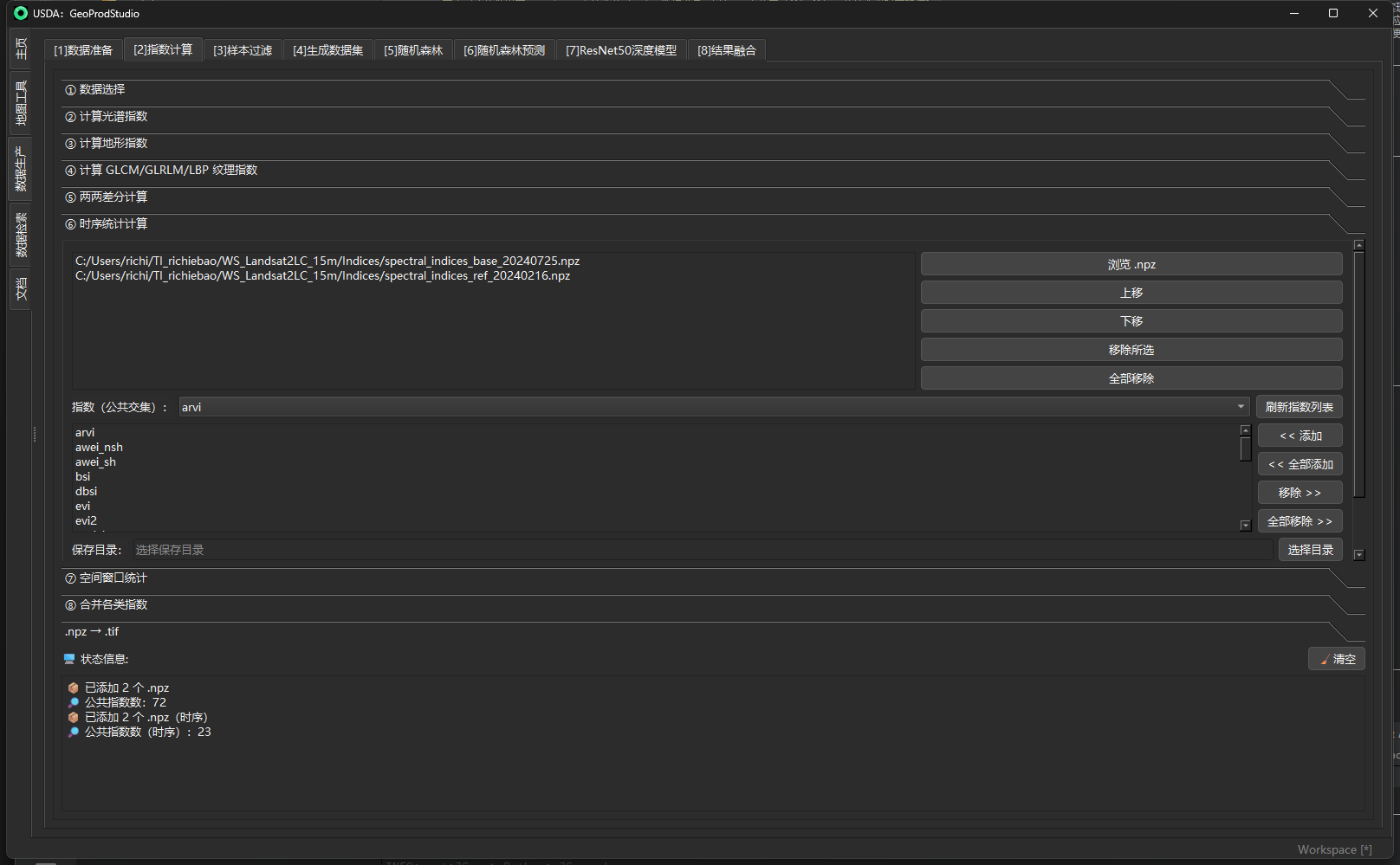
面板位置:索引计算 → “⑥ 时序统计计算”。 作用:在多期
.npz指数文件上,按像元统计时间维度特征,用于分割/解译中的“季节性/年际变化”识别(如耕地与常绿林、季节水体与永久水体、扰动前后差异等)。
目的
- 从多期 Landsat 指数序列中提取稳定且对噪声鲁棒的时间特征:方差(var)、极差(range)与最大值出现时间索引(max_t)。这些特征能把“季节性强/变化大”的地物(耕地、季节水体、烧毁区)与“稳定/变化小”的地物(城区、裸地、常绿林)区分开来。实现既支持通用任意指数,也内置季节 NDVI 专项(ndvi_var/ndvi_range/ndvi_max_t)。
机制 / 实现
-
通用计算器:
compute_time_series_stats(npz_paths, selected_indices, out_dir, ...)从多期.npz里抽取所选指数,按相同像元堆叠为 (T,H,W);随后对每个像元计算:- 方差 var:使用无告警、忽略 NaN 的手工公式
E[x^2] − (E[x])^2(仅当该像元有效样本数 n≥2); - 极差 range:
max − min,遇到全无效像元输出 NaN; - 最大值时间索引 max_t:把 NaN 当作 −∞ 求
argmax,再用有效掩膜恢复无效像元为 NaN。 结果保存为{idx}_var / {idx}_range / {idx}_max_t,并尽量沿用首个文件的transform元数据。
- 方差 var:使用无告警、忽略 NaN 的手工公式
-
季节 NDVI 专项:
compute_ndvi_seasonal_stats(ndvi_npz_paths, ...)从若干 NDVI.npz中构建时间栈,计算ndvi_var(实际为 std 的实现)、ndvi_range与ndvi_max_t,并写回transform。 -
UI 与后台执行 面板支持多选/排序
.npz、从“公共交集”下拉中挑选指数,统一前缀命名并在后台线程执行,过程中节流打印进度,避免卡顿:输出文件名形如TSA__id1-to-idN.npz。
输入 / 输出与参数
| 字段 | 类型/控件 | 必填 | 说明与默认 | 取值与注意 |
|---|---|---|---|---|
| 浏览 .npz / 上移 / 下移 / 移除所选 / 全部移除 | 列表 + 工具按钮 | 是 | 维护按时间顺序的 .npz 列表;支持拖拽排序 |
至少选择 2 个文件,否则拒绝启动。 |
| 指数(公共交集) | 下拉框 | 否 | 自动扫描所有 .npz 的共同键名并按字母序列出 |
点“刷新指数列表”重新扫描;若无公共键,将提示检查输入。 |
| 已选指数列表 / « 添加 / « 全部添加 / 移除 » | 列表 + 按钮 | 否 | 把公共交集中的指数加入待统计集合 | 不选择指数将直接返回,不计算。 |
| 保存目录 | 目录选择 | 是 | 输出目录 | 若为空使用工作空间路径。 |
| 文件名前缀(Prefix) | 文本 | 否 | 默认 TSA,输出名为 TSA__id1-to-idN.npz;失败回退为 tsa |
id 由输入文件名规范化而成,便于溯源。 |
| 开始时序统计计算 | 按钮 | 是 | 触发后台线程执行 | 进度采用节流日志输出;完成或异常均会提示。 |
| 严格形状(strict_shape) | 代码参数 | 否 | 默认 False:若形状不一致则跳过并写日志;必要时可改 True 强制一致 |
读取阶段支持 mmap,更省内存。 |
| 输出内容 | .npz |
— | {idx}_var / {idx}_range / {idx}_max_t;可能携带 transform |
上述键名按所选指数逐一生成。 |
公式与解释(通用指数)
令同一像元在第 $t$ 期的指数为 $X_t$,有效观测数为 $n$(剔除 NaN/无效值),$t=1,\dots,n$。
- 方差(var) – 反映时间变化强度
$$ \mathrm{Var}(X) ;=; \mathbb{E}!\left[X^2\right] - \left(\mathbb{E}[X]\right)^2 ;=; \frac{1}{n}\sum_{t=1}^{n} X_t^2 ;-; \left(\frac{1}{n}\sum_{t=1}^{n} X_t\right)^2, \quad n\ge 2. $$
实现时忽略 NaN;当 $n<2$ 输出 NaN。
- 极差(range) – 反映时间包络宽度
$$ \mathrm{Range}(X) ;=; \max_{t} X_t ;-; \min_{t} X_t, $$
若像元全无效则输出 NaN。实现通过把无效值替换为 $-\infty/+ \infty$ 再求极值,避免 All-NaN 告警。
- 最大值出现时间(max_t) – 反映峰值时相
$$ t^{\ast} = \operatorname*{arg,max}_{t} X_t $$
输出为时间索引(0~T−1,对应输入列表顺序);若像元全无效则 NaN。实现把 NaN 视为 $-\infty$ 求 argmax,随后仅在有有效样本处写回索引。
使用建议
1) 选择哪些指数做 TSA?
- 植被季节性:
NDVI, EVI, MSAVI2, NDMI的 var/range 区分季节耕地(大)与常绿林/灌丛(小);ndvi_max_t指示峰值生长时相,利于作物类型区分。 - 水体季节性:
MNDWI, AWEI_SH, AWEI_NSH的 range 能识别丰枯期水域/滩涂与常年水体。 - 城建/裸地:
NDBI, IBI, BSI, UI, DBSI通常 var 小、range 小,可与耕地/水体形成互补; - 扰动:
NBR(及 NDMI)的 var/range 对火烧、采伐、建设扰动敏感。 这些指数优先级与软件整体推荐保持一致,可与纹理/空间统计组合使用。
2) 与光谱/纹理/空间统计的组合
- 基础通用:
{NDVI,EVI,MSAVI2,NDMI, MNDWI, NDBI, NBR} + 纹理 contrast/entropy(win=5, levels=16) + 空间统计 mean/std/iqr/p90(w=3/5/7) + TSA 的 var/range。这样的多模态组合可同时表达“谱状差异 + 纹理结构 + 时间变化”。 - 耕地识别:
NDVI_var + NDVI_range + NDVI_max_t(季节相位)与EVI_var组合,明显高于城镇/常绿林;再叠加 GLCM 对比度提升田块纹理分割。 - 季节水体识别:
MNDWI_range与AWEI_*_range;叠加空间 p90/iqr 抗噪;与地形的 TWI/HAND(若已计算)一起有助于低洼漫滩区分。 - 扰动监测:
NBR_range + NDMI_range拿到扰动强度,必要时与“⑤ 两两差分”里的NBR_diff合用,定位发生期。
3) 数据与顺序
- 建议覆盖至少 4 个时相(最好跨季节),并在 UI 中按时间排序。若样本不足,方差与极差会偏向噪声。
- 时序统计对无效像元自动忽略;但若同一像元有效样本 < 2,输出将是 NaN(可在后续分类中当作掩膜)。
日志与排错
-
常见提示
- “请先添加至少 2 个 .npz 文件 / 时序统计至少需要 2 个 .npz 文件 / 未选择任何指数”:输入不完整时的前置校验。
- “未找到公共指数键”:所选
.npz字段不一致;检查前序步骤或先执行“⑧ 合并索引”。 - 运行中会显示节流的进度信息与完成/失败提示。
-
代码层保护
- 至少两期、每个所选指数都要出现≥2次,否则直接报错。
- 形状不一致:默认
strict_shape=False跳过异常时空块并写日志;可改为True强制一致。 - 保存时使用文件锁和安全压缩,避免并发写导致损坏。
-
性能建议
- 读取采用
mmap,逐指数栈计算并主动回收内存,降低 UI 卡顿。
- 读取采用
输出检查与命名
- 结果文件:
<prefix>__<首id>-to-<末id>.npz(默认前缀TSA)。文件内含{idx}_var / {idx}_range / {idx}_max_t与可选transform。
⑦ 空间窗口统计(Spatial Window Statistics)
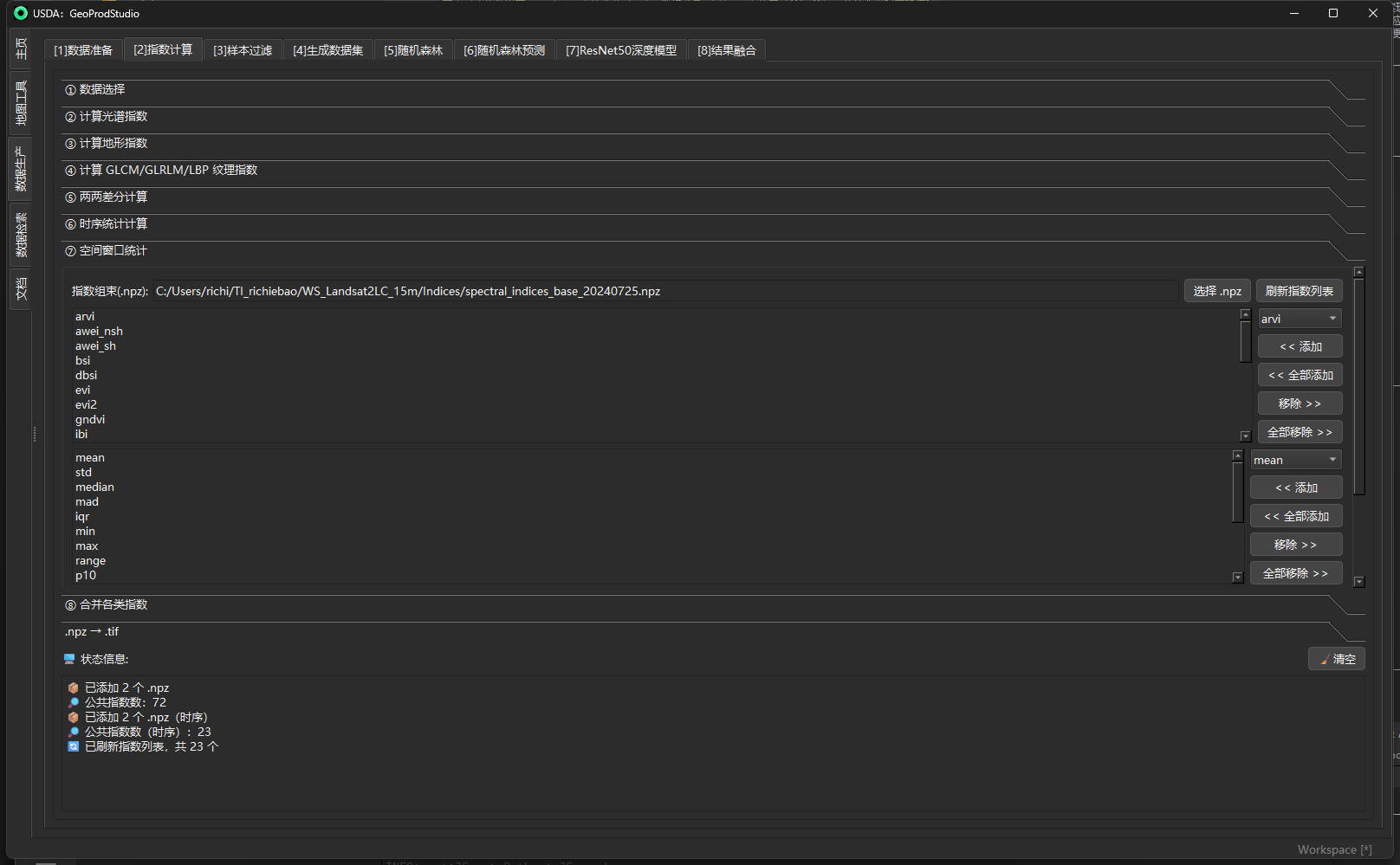
面板位置:指数计算 → ⑦ 空间窗口统计 作用:在单期指数图(来自前面步骤生成的
.npz)上,以滑动窗口提取局部统计量(均值/方差/分位数/直方图熵/梯度统计等),为分类模型提供“谱值+局部上下文”的稳健特征。实现采用 NaN-安全、分块计算、统一增量写入等工程策略。
目的
- 增强可分性:把像元值与其邻域的统计关系编码出来,稳定边界、抑制噪声;对城建细碎区、河网、田块等尤为有效。
- 抗云/噪声:统计量按窗口聚合并对 NaN 友好,可在掩膜不完美时保持稳健。
- 统一输出:支持将多指数×多窗口×多指标的结果增量写入同一个
.npz,便于管理与后续训练/制图。
机制 / 实现(关键点)
-
滑窗统计(NaN-安全) 每个指标在窗口内通过
scipy.ndimage.generic_filter计算;所有统计函数都先剔除 NaN 再聚合,边界用cval=np.nan填充。支持3/5/7/…等奇数窗。 -
指标全集 默认提供 16+ 项:
mean, std, median, mad, iqr, min, max, range, p10, p90, coefvar, skew, kurt, hist_entropy, grad_median, grad_iqr。其中hist_entropy的bins可调,grad_*基于 Sobel 梯度幅值。 -
统一增量写入 通过文件锁 + 追加写入把多个结果键(
{index}_{metric}_w{win})分批附加到单个.npz,首写时附带transform以保留栅格参考。避免一次性占用大内存。 -
小写键名与对齐 读取
.npz时对键名大小写鲁棒匹配,输出沿用首个输入的transform(若存在),保证后续npz→tif时像元对齐。
输入 / 输出与参数(面板字段一览)
| 区域/控件 | 类型 | 必填 | 说明 / 取值规则 | 操作要点 | 输出/副作用 |
|---|---|---|---|---|---|
| 指数组栈(.npz) | 文件 | 是 | 选择一个来自“② 计算光谱指数/④ 纹理/③ 地形”等步骤的 .npz |
选择 .npz |
作为本次统计的输入容器 |
| 可选指数列表 | 列表 | 是 | 从该 .npz 的字段中挑选要做统计的指数(如 ndvi, mndwi, ndbi…) |
右侧 << 添加 / << 全部添加 / 移除 >> / 全部移除 >> |
决定输出键此前缀 |
| 统计指标列表 | 列表 | 否 | 选择要计算的统计量(默认即上述 16+ 项;支持多选) | 右侧与上同 | 形成 {index}_{metric}_w{win} |
| 窗口大小 | 文本 | 是 | 逗号分隔的奇数:如 3,5,7;内部自动把偶数纠正为奇数 |
— | 多尺度会循环计算 |
| 保存目录 | 目录 | 是 | 统一输出目录 | 选择目录 |
在目录下生成一个统一 .npz |
| 文件名前缀(Prefix) | 文本 | 否 | 统一文件名的前缀(可空) | 直接输入 | 例如 winstats_spatial_stats_w5-7.npz |
| 开始计算空间窗口统计 | 按钮 | 是 | 触发后台计算并打印进度 | — | 逐项增量写入;首写附 transform |
输出命名:
{index}_{metric}_w{win}。例如:ndvi_mean_w5、mndwi_hist_entropy_w7、ndbi_grad_iqr_w5。
公式与解释
记输入指数图为二维数组 $X$,窗口为以中心像元为原点的 $w\times w$ 邻域 $\mathcal{N}$(去 NaN 后参与统计)。
1) 位置与离散度类
-
均值
$$ \mathrm{mean}(X)=\frac{1}{|\mathcal N|}\sum_{x\in\mathcal N}x $$
解释:局部平均水平;在河道、水面等低频平滑区域更稳定,可抑噪平滑边界。
-
标准差
$$ \mathrm{std}(X)=\sqrt{\frac{1}{|\mathcal N|}\sum_{x}(x-\bar x)^2} $$
解释:局部起伏/纹理强度;城建/破碎林缘高,开阔水体/均匀农田低。
-
中位数
$$ \mathrm{median}=\operatorname{Quantile}_{0.5}(X) $$
解释:对异常值更稳的“均值”;阴影/薄云残留时仍可靠。
-
MAD(中位数绝对偏差)
$$ \mathrm{mad}=\operatorname{median}(|x-\operatorname{median}(X)|) $$
解释:稳健离散度;抗异常点强,适合城郊混合区。
-
IQR(四分位距)
$$ \mathrm{iqr}=\operatorname{Q}{0.75}(X)-\operatorname{Q}{0.25}(X) $$
解释:离群不敏感的波动幅度;与 std 互补。
-
最小/最大/极差
$$ \min(X),\ \max(X),\ \mathrm{range}=\max-\min $$
解释:捕捉邻域包络,高反差边界/碎斑处极差更大。
-
分位数(p10/p90)
$$ \operatorname{Q}{0.10}(X),\ \operatorname{Q}{0.90}(X) $$
解释:描述亮/暗侧边缘,常用于阈值化或对比度特征。
-
变异系数
$$ \mathrm{coefvar}=\frac{\mathrm{std}}{\mathrm{mean}} $$
解释:归一化波动强度;高反差且均值较低时上升(如暗背景上的亮目标)。
2) 形态分布类
-
偏度(skew)
$$ \mathrm{skew}=\mathbb E!\left[\left(\frac{x-\mu}{\sigma}\right)^3\right] $$
解释:分布尾部方向;可区分“亮尖峰”(裸地亮斑)vs “暗尖峰”(水体/阴影)。
-
峰度(kurt)
$$ \mathrm{kurt}=\mathbb E!\left[\left(\frac{x-\mu}{\sigma}\right)^4\right]-3 $$
解释:尖峭/厚尾程度;规则图案(屋顶瓦片)常更“尖”。
-
直方图熵(hist_entropy, bins = B)
$$ \mathrm{hist_entropy}=-\sum_{b=1}^{B}p_b\log p_b $$
其中 $p_b$ 为窗口内落在第 $b$ 个直方图箱的概率。 解释:无序度;城建/烧毁区↑,均匀水面/整齐农田↓。
bins越大越敏感。
3) 梯度结构类(Sobel 幅值)
-
梯度定义
$$ G=\sqrt{(\mathrm{Sobel}_x X)^2+(\mathrm{Sobel}_y X)^2} $$
解释:边缘强度/纹理方向的总量。
-
grad_median / grad_iqr
$$ \mathrm{grad_median}=\operatorname{median}(G),\quad \mathrm{grad_iqr}=\operatorname{Q}{0.75}(G)-\operatorname{Q}{0.25}(G) $$
解释:边界密度与强度的稳健刻画;城镇路网/林缘密集区↑,水体/草地↓。
与纹理(④)互补:空间统计更偏“量纲与分布”,GLCM/GLRLM/LBP 偏“相对关系与结构”。二者叠加往往显著提升可分性。
使用建议
1) 选哪些指数做空间统计?
优先在四大核心指数上做:NDVI, MNDWI, NDBI, NBR;必要时补 NDMI、BSI。这些指数已在[2]章节反复验证对 LC 分割的主导作用。
2) 推荐指标组合(每个指数 3–6 个足够)
- 通用稳健:
mean, std, iqr, hist_entropy, grad_median(w=5,再选 w=7)。 - 城市/建成区:
std, hist_entropy, grad_iqr, coefvar(NDBI 上尤其有效)。 - 水体/湿地:
mean/p10(MNDWI) + std/iqr 低 + hist_entropy 低;长河道可加grad_median_w7。 - 农田/垄向:
std(NDVI)中等,grad_*适度;与纹理中的 correlation/LRE 联合刻画方向性。 - 扰动/烧毁:在
NBR上std / hist_entropy / grad_iqr常显著上升。
3) 窗口与参数
- 窗口:优先
w=5,视地物尺度再加w=7;城市极细碎可再加w=3。 - bins(熵):16 起步;纹理复杂区可用 32,但注意噪声敏感。
- 统一输出:勾选多指数+多指标时建议统一写一个
.npz(默认行为),便于任务管理与下游训练。
4) 与光谱/纹理/时序的组合
-
基本包:
{NDVI,MNDWI,NDBI,NBR} × (mean,std,iqr,hist_entropy,grad_median)- 纹理:NDVI×
entropy/contrast、MNDWI×homogeneity,NDBI×glcm_var。 - 时序(⑥):把
var/range与本步std/iqr叠加,兼顾“时间波动 + 空间起伏”。
- 纹理:NDVI×
日志与排错
- 进度:会打印“载入 .npz… / 处理 {index}(m×n 组合)/ • {index} | w={w} | {metric} 完成 / 💾 已追加写入到:… / 🎉 已全部完成”。
- 字段找不到:列表中键名与
.npz不一致将提示“跳过:未找到字段 …”;检查②/④/③步骤的输出键名。 - 全 NaN / 常数:若输入指数在掩膜下为全 NaN 或常数,统计结果将为 NaN;需回溯指数计算与掩膜。
- 边界效应:窗口超出影像边界处用 NaN 填充,聚合后自然减弱;必要时用更大窗口平滑。
- 性能:指数×窗口×指标的组合会线性增时;统一
.npz的增量写入能显著降低内存峰值。
小结(可直接复用的“最小方案”)
- 选 NDVI / MNDWI / NDBI / NBR 四个指数;
- 窗口 w=5(+7);
- 指标 mean, std, iqr, hist_entropy, grad_median;
- 统一输出到
winstats_spatial_stats_w5-7.npz。
该组合与前述光谱/纹理/时序特征拼装后,通常能在 Landsat-8/9 的水体—建成—植被—扰动主类分割中获得稳定收益,并保持良好解释性与工程可控性。
⑧ 合并索引 (Merge Indices)
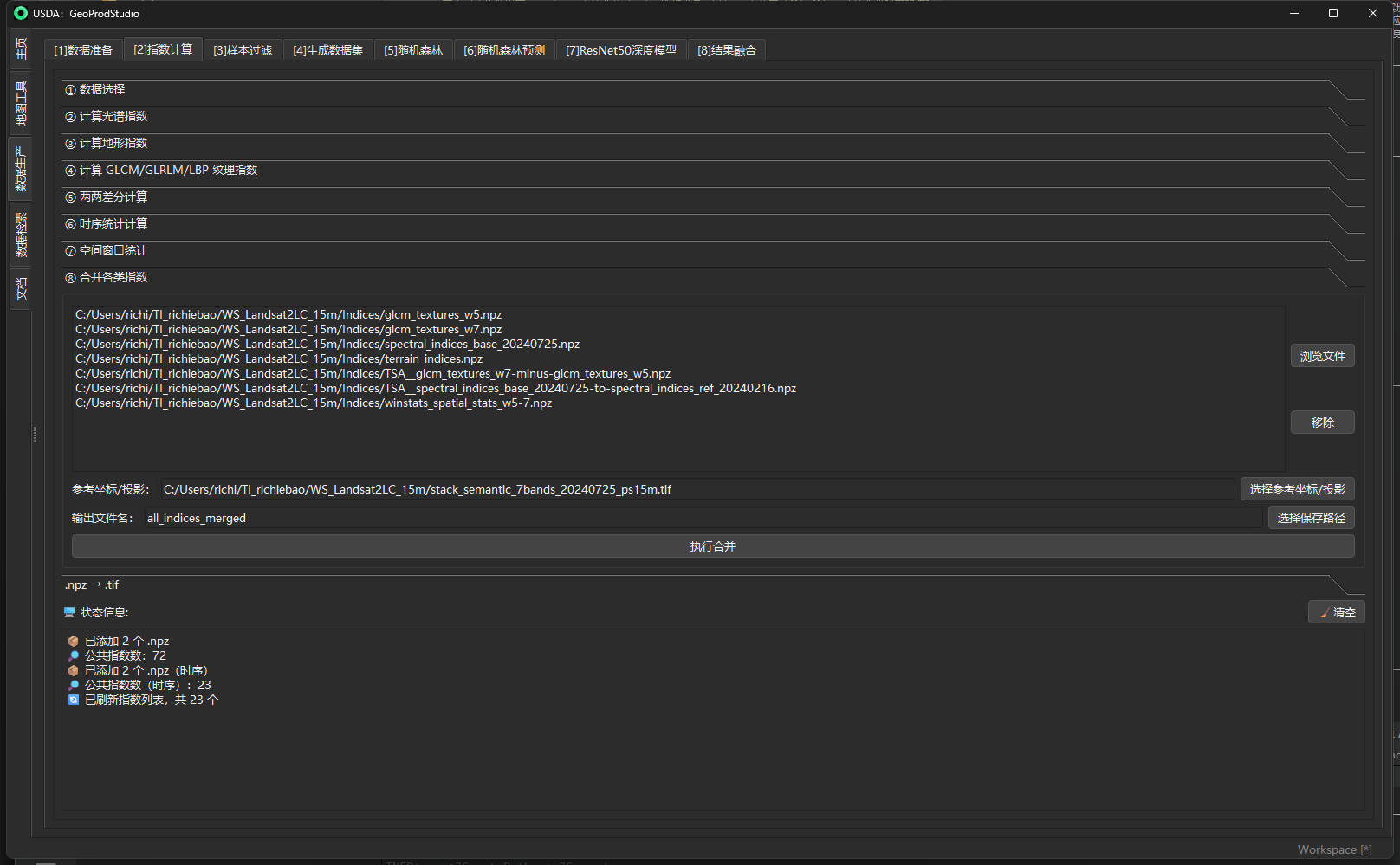
面板位置:指数计算 → ⑧ 合并索引 作用:把前面步骤(②–⑦)产出的多个
.npz特征包,在统一参考网格/坐标系下对齐并合并为一个.npz,方便后续“生成数据集 / 随机森林 / 深度学习 / 结果融合”等一次性读取与管理。
目的
- “一处管理,统一对齐”:把光谱指数、地形指数、纹理、两两差分、时序统计、空间窗口统计等全部整合到一个文件中,键名唯一、不互相覆盖。
- 空间一致:对形状/分辨率不一致的索引,按参考栅格(或参考矢量的 CRS + 基准栅格网格)重采样对齐,保证像元逐一对应。
- 保留空间参考:在输出中保存
transform / CRS(EPSG+WKT),便于后续.npz → .tif或作为训练输入直接使用。
机制 / 实现(工程要点)
-
参考网格加载 支持以栅格(
.tif/.tiff)直接取 shape/transform/CRS;或以矢量(.shp/.geojson)只取 CRS,同时必须提供一个基准栅格用于确定网格。若两者都未提供,则退回使用“基准栅格”。 -
重采样对齐 对每个输入数组(仅二维)做形状检查;不一致则按参考网格用
rasterio.reproject双线性重采样到目标形状;形状本就一致则直接复用。非二维数组跳过(例如历史元信息)。 -
原子写入与并发安全 输出
.npz采用文件锁 + 追加写策略:先写入一次性的transform / crs_epsg / crs_wkt,随后逐键增量附加,避免大内存峰值与并发冲突。 -
键名去重规则 为避免不同文件中同名键互相覆盖,合并时会把来源文件名追加到键名后缀:
out_key = "<key>:::<basename>"。例如:ndvi:::spectral_indices_20200816。 -
默认参数 重采样方法 = bilinear;角度/窗口等细则由各上游步骤在写入其
.npz时已经固化为键名后缀(如_a90、_w5等),合并只做对齐 + 汇总。
以上机制对应实现中的:参考网格解析、原子追加写、重采样对齐、键名后缀化与 CRS/EPSG/WKT 的写入;运行日志会实时打印“参考网格 / 对齐 / 写入 / 完成”等关键信息。
输入 / 输出与参数(面板字段一览)
| 区域/控件 | 类型 | 必填 | 说明 / 取值规则 | 操作要点 | 输出 / 副作用 |
|---|---|---|---|---|---|
| 待合并文件列表 | 列表(.npz) | 是 | 选择来自步骤②–⑦的 1–N 个 .npz(如:spectral_indices.npz、glcm.npz、terrain_indices.npz、diff__*.npz、tsa__*.npz、winstats__*.npz 等) |
右侧**“浏览文件 / 移除 / 全部移除”**维护 | 决定被合并的键集合 |
| 参考坐标/投影 | 路径 | 否 | 推荐选择基准 7 波段栅格(与训练/预测用的主影像一致);也可选 .shp/.geojson(仅取 CRS,此时需另有基准栅格以确定网格) |
**“选择参考坐标/投影”**按钮,或留空(则采用基准栅格) | 影响重采样对齐与输出的 transform/CRS |
| 输出文件名 | 文本(文件名) | 是 | 合并后的 .npz 名称(无需扩展名) |
与**“选择保存路径”**联用 | 在选定目录写出 all_indices_merged.npz 等 |
| 执行合并 | 按钮 | 是 | 触发后台线程执行:读取→对齐→追加写 | 过程内会显示进度日志,完成后恢复 | 产出 1 个大一统 .npz(含 transform/CRS) |
输出键名风格:继承上游命名 + 来源后缀,例如:
ndvi_mean_w5:::winstats_spatial_stats、mndwi_homogeneity:::glcm_w5、slope:::terrain_indices、ndvi_range:::tsa_2020、ndbi_entropy_diff:::diff_20200816_20201002等。 空间参考:输出会包含transform / crs_epsg / crs_wkt三项元数据,便于后续.npz → .tif。
公式与解释(索引家族回顾)
本步骤不新增公式,而是把以下家族的索引按像元对齐后合并。这里精要回顾,用于在合并时核对选择是否完整、互补。
-
光谱指数(②) 植被:NDVI/EVI/EVI2/SAVI/OSAVI/MSAVI2/ARVI/GNDVI/NDMI; 水体:NDWI/MNDWI/AWEI_SH/AWEI_NSH/WRI/NDPI; 城建裸地:NDBI/UI/IBI/DBSI/BSI; 扰动火烧:NBR/NBR2; 雪冰:NDSI。 → 识别地表物质/含水/生物量与城市化/扰动的主力特征。
-
地形指数(③) Slope/Aspect/TPI/TRI/Curvature/Roughness/VRM/TWI/HAND。 → 约束地貌—水文格局(坡度坡向/山脊沟谷/湿度与相对高程)。
-
纹理(④) GLCM:contrast/dissimilarity/homogeneity/ASM/energy/entropy/correlation/glcm_mean/var/std; GLRLM:sre/lre/gln/rln/rp; LBP:mean/std/entropy/uniform_ratio。 → 刻画结构尺度、方向性、无序度与细颗粒特征(城市/河网/垄向/烧毁)。
-
两两差分(⑤)
*_diff(后 − 前):dNDVI/dMNDWI/dNDBI/dNDMI/dNBR … → 把时相变化显式化(涨落水、扩张、复绿/干化、火烧等)。 -
时序统计(⑥)
{idx}_var / {idx}_range / {idx}_max_t。 → 度量时间波动强度、包络宽度与峰值时相(耕地/季节水体/常绿林)。 -
空间窗口统计(⑦)
mean/std/median/mad/iqr/min/max/range/p10/p90/coefvar/skew/kurt/hist_entropy/grad_*_wX。 → 把局部上下文编码入特征,稳边降噪(城建/河网/田块显著受益)。
合并时建议按以上 6 类检查是否覆盖:至少要有四大光谱主干(NDVI/MNDWI/NDBI/NBR),再按场景补必要的地形/纹理/时序/空间统计,使信息既互补又不过载。
使用建议
-
参考选择 统一使用训练/预测主影像对应的 7 波段栅格作为参考(分辨率/投影/裁切一致),避免后续模型训练和制图出现像元偏移。
-
特征“瘦身” 合并只是“汇总”,不等于全选。建议在合并前就做一次特征挑选:
- 光谱:
NDVI, MNDWI, NDBI, NBR (+ NDMI/BSI/IBI) - 纹理:每个核心指数挑 2–3 个(如 NDVI 的
entropy/contrast,MNDWI 的homogeneity,NDBI 的entropy/var) - 时序/空间统计:每类 2–4 个高价值条目(如
var/range、mean/std/iqr/hist_entropy)。 总特征量控制在 20–40 更利于训练与解释。
- 光谱:
-
命名与可复现 输出名建议如
all_indices_merged.npz;合并前给各.npz起清晰的来源名(如spectral_20200816.npz、glcm_w5.npz),便于通过键名后缀追踪来源。 -
下游衔接 合并后此
.npz就是唯一输入:- ④ 生成数据集:直接从合并
.npz里按键读取特征; - ⑤/⑥ 模型训练/预测:同样只读这一个文件;
- 需要制图:用“NPZ→TIF”工具把关心的键批量转为 GeoTIFF。
- ④ 生成数据集:直接从合并
日志与排错
-
常见日志
📐 参考栅格:.../📐 使用基准栅格作为参考:...📄 Processing file i of N (...path...)🔄 重采样对齐 <key>:::<base> (h×w -> H×W)➕ 写入 <key>✅ 合并完成:X 个指数已写入;输出文件:...
-
报错与处理
- “至少选择 1 个 .npz”:未添加输入。
- 参考为矢量但未给网格:须同时提供一个基准栅格确定网格。
- 形状不一致:会自动重采样对齐;若发现全 NaN,多半是输入与参考投影/范围不匹配,请复核参考影像。
- “跳过非二维数组”:输入里有非 2D 的对象(如字符串元数据);忽略即可。
- 键名冲突:已用
:::后缀区分来源;如仍担心冗余,请在合并前整理各.npz的字段集合。 - 内存/速度:大量大数组时建议分批合并(先合并同类,再二次合并),或在 SSD 上运行以降低 IO 瓶颈。
示例(推荐工作流)
- 选入:
spectral_indices.npz(②)、terrain_indices.npz(③)、glcm_w5.npz(④)、diff__*.npz(⑤)、tsa__*.npz(⑥)、winstats__*.npz(⑦)。 - 参考坐标/投影:选择基准 7 波段栅格(
*_7bands_clipped.tif)。 - 输出文件名:
all_indices_merged。 - 点击执行合并 → 得到
all_indices_merged.npz(含 transform/EPSG/WKT)。 - 在“生成数据集/训练/预测”只读取这一份;制图时按需
.npz → .tif。
小结:⑧ 合并索引把“多源多尺度多时相”的特征统一到同一网格与同一容器,是从“特征工程”走向“可训练/可制图”的最后一步。做好参考选择、精挑特征、保留空间参考,你就能在后续环节一键复用、稳定落地。
& NPZ→TIF(把 .npz 指数栈高效导出为多波段 GeoTIFF)
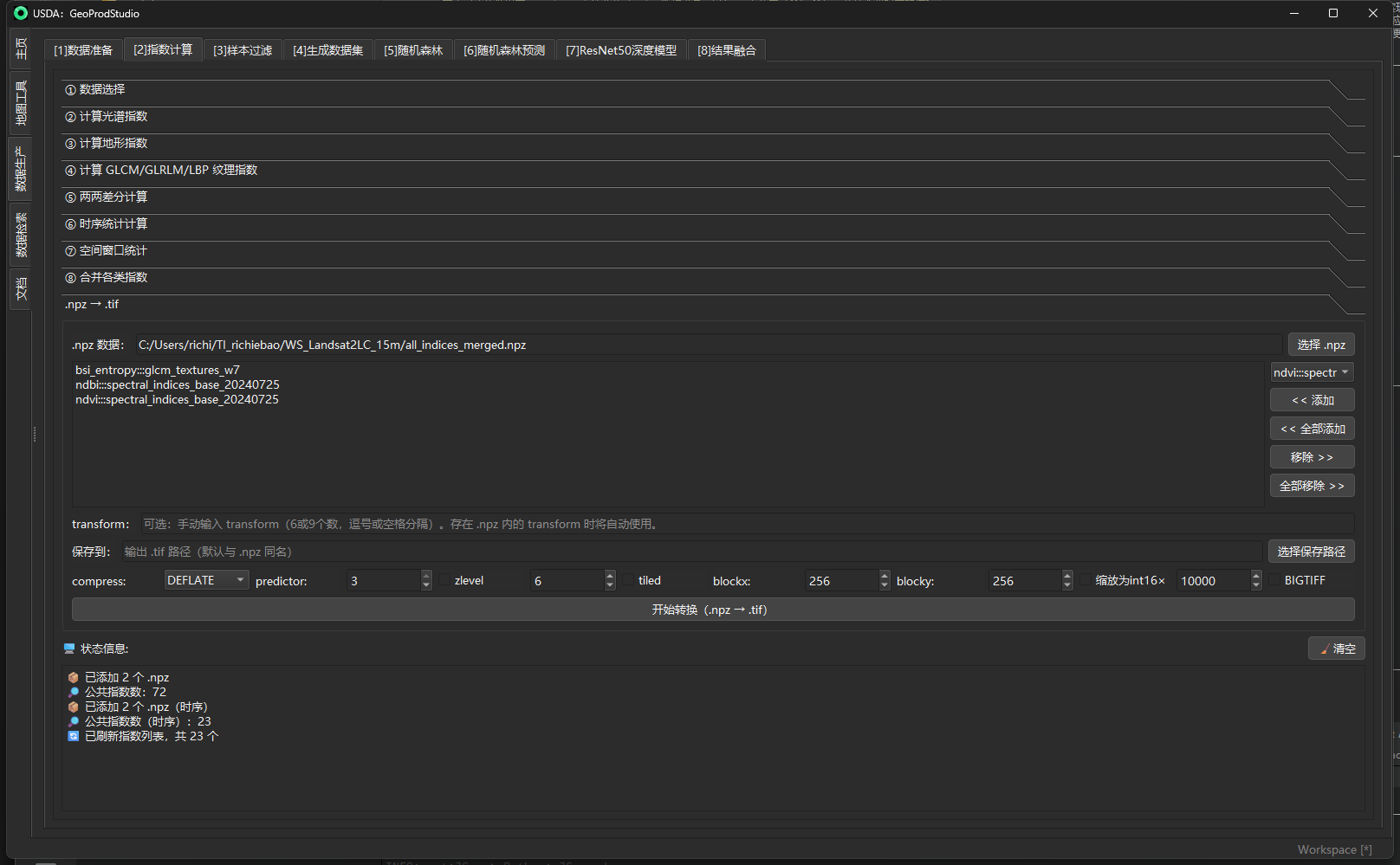
本节仅格式转换,不重新计算指数。导出的每个波段仍然是你在步骤②–⑦产出的指数(或其派生统计/纹理)。
目的
- 将一个或多个指数键(NDVI、MNDWI、NBR、GLCM 统计等)从
.npz容器直接写出为多波段 GeoTIFF,以便在 GIS/影像软件制图、叠加、切片或下游系统(如地物分类、地图服务)中使用。 - 可选择压缩、瓦片分块、整型缩放,并尽可能保留空间参考(仿射变换、CRS)。实现过程中优先使用
.npz内的transform,并可由基准栅格补齐 CRS 信息。
机制 / 实现(工程要点)
-
空间参考解析
- 若
.npz内含transform(保存时通常为 9 个数的 3×3 线性化矩阵),优先取用;若 UI 手动输入了transform,按 6/9 个数字解析;否则无 transform。 - CRS 优先取自“基准栅格”(可选)。
- 若
-
输出档案结构 逐波段流式写入,
count=所选指数数,nodata与dtype随“是否整型缩放”自动设置;interleave="band";可选压缩、瓦片和 BigTIFF。 -
编码与性能优化 支持
compress=NONE/DEFLATE/LZW/ZSTD;predictor(1/2/3);可选zlevel;tiled + blockxsize/blockysize;GDAL 多线程写盘;按需写 band 名称。 -
整型缩放(可选) 若启用“缩放为 int16×K”,以原位乘以
K、四舍五入、裁剪到[-32768,32767]后写出,nodata=-32768;并在 TIF TAG 里记下SCALE=1/K。 -
一致性检查与报错 仅写二维数组;所有指数必须同尺寸;键必须存在。
输入 / 输出与参数(面板字段一览)
| 区域/控件 | 类型 | 必填 | 说明 / 取值规则 | 输出 / 副作用 |
|---|---|---|---|---|
.npz 数据 |
列表 | 是 | 从下拉中选择并“添加/全部添加”需要导出的指数键(会自动排除 transform)。若未选键会提示。 |
将列表顺序对应到 TIF 的波段顺序。 |
| transform(可选) | 文本 | 否 | 6 或 9 个数,逗号/空格分隔:[a b c d e f] 或 3×3 线性化的前 6 个。若 .npz 自带 transform 则优先用其。 |
设置 GeoTransform(若留空且 .npz 也无,则输出无地理坐标)。 |
| 保存到 | 路径 | 是 | 输出 TIF 完整路径;为空时默认与 .npz 同名 .tif。 |
生成 GeoTIFF;必要时启用 BigTIFF。 |
| compress | 选项 | 否 | NONE / DEFLATE / LZW / ZSTD(默认 DEFLATE)。 |
控制压缩算法。 |
| predictor | 数值(1–3) | 否 | 预测编码器(浮点常用 3,整型常用 2;默认自动随 dtype)。 | 降低压缩熵,提升压缩率。 |
| zlevel | 开关+数值 | 否 | 对 DEFLATE/ZSTD 生效;1–9(DEFLATE),1–22(ZSTD)。 | 提高压缩比但略降速度。 |
| tiled / blockx / blocky | 选项+数值 | 否 | 开瓦片写入与瓦片大小(典型 256–512)。 | 更利于随机访问与金字塔构建。 |
| 缩放为 int16×K | 开关+数值 | 否 | 将浮点指数按 K 缩放写成 int16(默认 K=10000),并设置 nodata=-32768。 |
显著减小体积与 IO;TIF 写入 SCALE=1/K 便于后续反解。 |
| BIGTIFF | 复选 | 否 | 大于 4GB 时建议开启。 | 避免 4GB 限制。 |
| 开始转换(按钮) | 按钮 | 是 | 执行写盘;进度日志会显示“写入进度 i/N / 完成”。 | 生成目标 GeoTIFF;每个波段写入索引名作为 band 描述。 |
公式与解释
1) 仿射变换(GeoTransform)
UI 接受 6 参或 9 参(取前 6 个)形式的仿射矩阵:
$$ \begin{aligned} x_\text{geo} &= a\cdot \text{col} + b\cdot \text{row} + c,\ y_\text{geo} &= d\cdot \text{col} + e\cdot \text{row} + f. \end{aligned} $$
当提供 3×3 线性化矩阵时,仅取 $(a,b,c,d,e,f)$ 六项作为 GDAL 仿射。实现上对 6/9 个浮点数分别解析并构造 Affine(a,b,c,d,e,f)。
2) 整型缩放(float32 → int16)
对每个像元的浮点指数 $x$,若启用“缩放为 int16×K”,执行:
$$ y = \operatorname{clip}!\Big(\operatorname{round}(K,x),\ -32768,\ 32767\Big),\quad \text{dtype}(y)=\text{int16}. $$
若输入为 NaN,则输出为 -32768(nodata),并在 TIF TAG 写入 \text{SCALE}=1/K。
典型地,Landsat 光谱/指数范围约 $[-1,1]$,取 K=10000 后几乎完整覆盖,便于在多数 GIS / 服务器中高效存取。
3) 波段与键映射
输出第 $i$ 个波段即为所选列表中第 $i$ 个键;同时把键名写入 band description。
日志与排错
常见日志
- “🚀 开始转换:… → …” / “💾 写入进度:i/N(最近写入:key)” / “✅ 转换完成:…”。
典型报错与处理
- “未选择任何指数”:未在列表中添加键。
- “选定的指数在 .npz 中不存在”:键名拼写或上游产出不一致。
- “指数 XXX 不是二维数组”:输入对象不是 2D 数组。
- “所有指数必须尺寸一致:XXX 的 shape=… 与首层不同”:上游步骤生成的数组大小不一致,应回到合并/重采样环节排查。
使用建议
- 什么时候缩放为 int16:要上图、切片、长距离传输时建议开启,K 取 10000;做精细数值分析(回归、指数叠加)时保留 float32。
- 压缩与 predictor:默认
DEFLATE已足够通用;整型+2、浮点+3 的 predictor 自动选择即可(也可手设 1–3)。 - 瓦片与块大小:若用于金字塔/网络服务,勾选
tiled并用blockx=blocky=256~512。 - 大文件:预估 >4GB 或未来要追加波段时,开启
BIGTIFF。 - 空间参考:若导出的 TIF 在 GIS 中无定位,多半是缺
transform或 CRS。优先在上游(⑧ 合并索引)把transform/CRS写入.npz,或在此步提供手动transform与基准栅格。
最小示例(建议操作顺序)
- 选择
.npz并在下拉里全部添加所需键;2) 勾选tiled,block=256;3) 需要制图则勾选“缩放为 int16×10000”;4) 选好输出路径并开始转换。完成后得到带空间参考、可直接用于制图/叠加的多波段 GeoTIFF。
[3] 样本过滤(Sample Filtering)
面板位置:[3] 样本过滤。 目标:在训练前,对矢量样本(GeoJSON 面要素)进行几何形态、光谱一致性、时空稳定性与类别数的联合过滤,剔除“形状畸形、内部混合、变化剧烈或数量过少”的样本,生成更“纯净、均衡、可复现”的训练集。
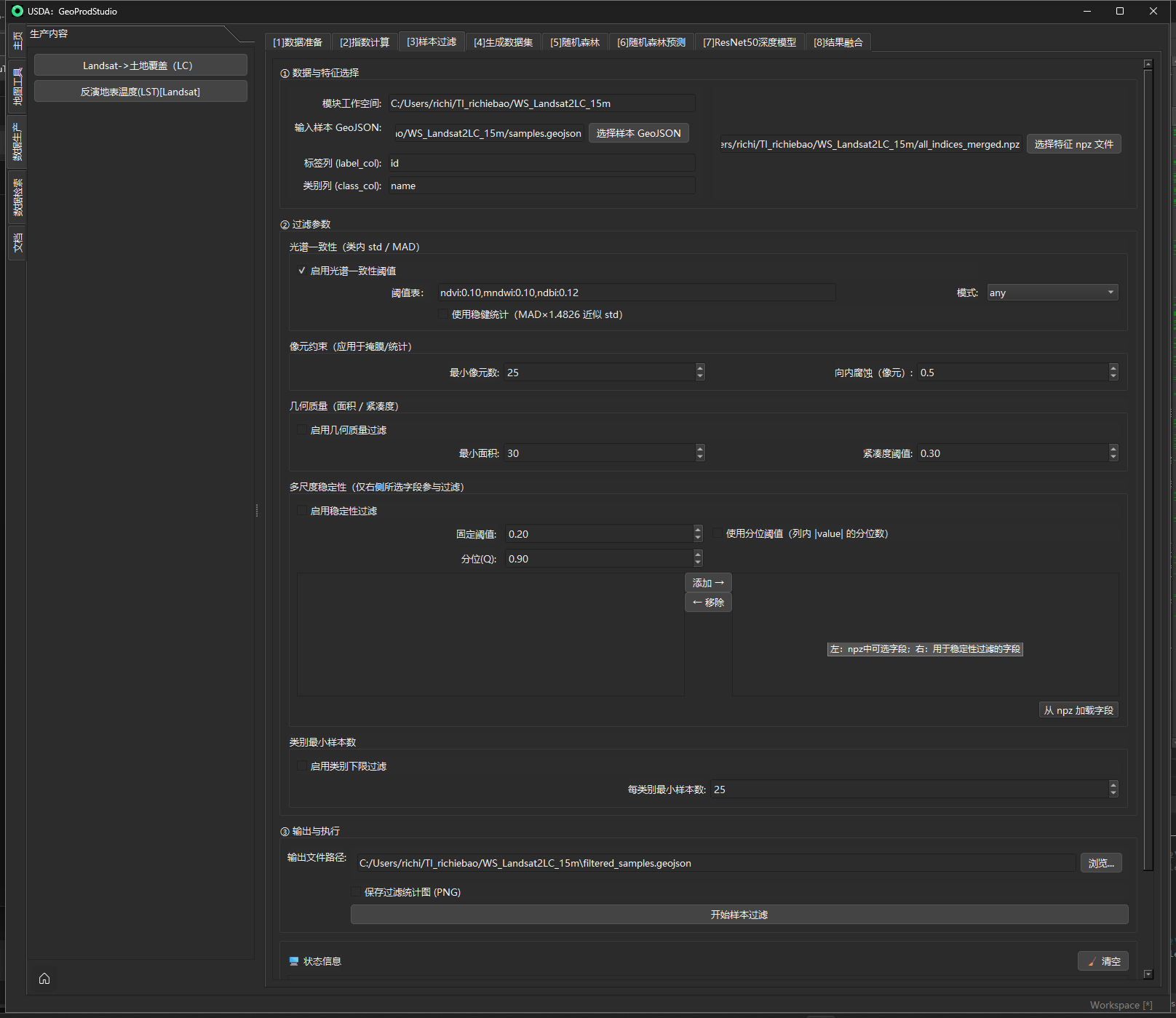
① 数据与特征选择
目的
- 选择样本 GeoJSON与特征 npz(来自“[2] 指数计算”等的输出),并(可选)指定要用于稳定性检验的字段列表。
机制 / 实现(后台要点)
- 读取 GeoJSON 与 npz;若 npz 内含
crs_epsg,先将样本重投影到该坐标系,以保证“多边形掩膜与栅格”同源。 - “从 npz 加载字段”会把 npz 里除
transform/crs_epsg外的二维数组键名加载到左侧列表,供选择为稳定性字段(在 ② 中启用后生效)。
输入 / 输出与参数(面板字段一览)
| 分组 | 字段 | 类型 / 取值 | 说明 |
|---|---|---|---|
| ① 数据与特征选择 | 模块工作空间 | 只读 | 当前模块的工作目录(用于默认保存路径)。 |
| 输入样本 GeoJSON | 路径 | 训练样本面要素文件(含标签列、类别列)。 | |
标签列 label_col |
文本 | 记录样本唯一标识,默认 id。 |
|
类别列 class_col |
文本 | 记录地类标签,默认 name。 |
|
| 选择特征 npz | 路径 | 含指数/纹理/统计等二维数组 + transform(必须)与 crs_epsg(可选)。 |
|
| 可选字段 ↔ 已选字段 | 列表 | 若在②启用“稳定性过滤”,这里右侧列表即为 stability_cols。 |
② 过滤参数
目的
- 按几何形态、光谱一致性、时空稳定性与类别数等条件“硬性”剔除不合格样本。
机制 / 实现(算法细节)
②.a 几何过滤(最小面积 + 紧凑度)
-
面积阈值
$$ A(\mathcal P);\ge;A_{\min}, $$
其中 $A(\mathcal P)$ 为样本多边形在等积/UTM投影下的面积;代码会自动推断 UTM,兜底为等积 EPSG:6933,以获得稳定量测。
-
紧凑度(Polsby–Popper)
$$ \mathrm{Comp}(\mathcal P);=;\frac{4\pi,A(\mathcal P)}{\big[L(\mathcal P)\big]^2}, $$
$L(\mathcal P)$ 为周长;$\mathrm{Comp}\in(0,1]$,越接近 1 越规则。过滤判据:
$$ \mathrm{Comp}(\mathcal P);\ge;C_{\min}. $$
几何过滤作为前置步骤,能廉价地大量缩减后续工作量。
②.b 光谱一致性过滤(按“基名”与阈值、多字段模式)
-
设对某指数基名(如
ndvi)在样本掩膜内取像元集合 ${x_i}_{i=1}^n$。一致性用总体标准差(ddof=0)衡量:$$ \sigma;=;\sqrt{\frac{1}{n}\sum_{i=1}^{n}\left(x_i-\mu\right)^2},\qquad \mu=\frac{1}{n}\sum_{i=1}^n x_i . $$
-
npz 字段名按
:::左右拆分,仅用左侧“基名前缀”匹配阈值(不区分大小写),例如ndvi:::spectral_indices_base_20200816→ 基名ndvi。 -
同一基名可能匹配到多个真实字段(不同日期/来源),每个字段各算一个 $\sigma$,并根据模式判定是否保留:
all:所有匹配字段都满足 $\sigma\le\tau$;any:任意一个字段满足 $\sigma\le\tau$;mean:对所有有限 $\sigma$ 求均值 $\overline{\sigma}\le\tau$。 以上逻辑与 ddof=0 均与实现一致。
-
像元下限:若有效像元数 $n<n_{\min}$(“最小像元数”),则本字段视为无效,不参与
any/mean的通过判定;all模式会因此不通过(健壮实现)。
②.c 稳定性过滤(时序/差分/空间统计等)
-
可从 npz 选择若干字段作为
stability_cols。系统会先对这些字段在每个样本内做分区均值(同一掩膜复用、可向内腐蚀),再以阈值检测“是否稳定”。 -
过滤判据($\mathbf z$ 为这些均值的向量):
$$ \max_j\big|z_j\big| ;\le; \theta . $$
即“任何一个稳定性量化值超过阈值 $\theta$ 即剔除”。实现上以多列绝对值的行最大值进行判断。
提示:
stability_cols适合选择来自 ⑤ 两两差分、⑥ 时序统计、⑦ 空间窗口统计 的“变化量/离散度”型指标(如dNDVI_2020_2021、NBR_range、GLCM_contrast_std等)。
②.d 类别样本数过滤
- 若选择启用,将移除“样本数 < 设定下限”的类别,避免训练阶段的类不平衡。
②.e 掩膜与边界腐蚀(稳健性)
- 对每个样本,多边形在其局部外接窗口内生成掩膜并复用;可按像元尺度进行向内腐蚀 $e$ 个像元以弱化边界混合像元的干扰(河岸/林缘/阴影等),显著提升稳健性与速度(实现细节见
_window_mask_for_geom)。
输入 / 输出与参数(面板字段一览)
| 分组 | 字段 | 类型 / 取值 | 默认 | 说明 | ||
|---|---|---|---|---|---|---|
| ② 过滤参数 | 启用光谱一致性 | 勾选 | ✓ | 启用后解析右侧阈值串并生效。 | ||
| 光谱一致性阈值 | 文本 | ndvi:0.05,mndwi:0.05,ndbi:0.05 |
逗号分隔 base:τ,如 ndvi:0.06。键名与 npz 字段基名对齐。 |
|||
| 模式 | 下拉 | any |
all/any/mean 三种多字段归并策略。 |
|||
| 启用几何过滤 | 勾选 | 勾选后启用下两项。 | ||||
最小面积 A_min |
整数 | 30 | 以自动推断的 UTM/等积坐标计算。 | |||
紧凑度阈值 C_min |
浮点 | 0.30 | 使用 $\frac{4\pi A}{L^2}$ 指标。 | |||
最小像元数 n_min |
整数 | 1 | 光谱与稳定性统计时的最小有效像元数。 | |||
向内腐蚀 e(像元) |
浮点 | 0.0 | 可设 0–2,弱化边界混合像元影响。 | |||
| 启用稳定性过滤 | 勾选 | 启用后对 ① 右侧“已选字段”求分区均值并检验阈值。 | ||||
稳定性阈值 θ |
浮点 | 0.20 | (\max | z_j | \le \theta) 为通过条件。 | |
| 启用类别样本数 | 勾选 | 勾选后启用下项。 | ||||
| 每类别最小样本数 | 整数 | 25 | 小于阈值的类别整体移除。 |
③ 输出与执行
目的
- 指定输出路径与是否保存过滤统计图,执行整个过滤流水线。
机制 / 实现(执行顺序)
- 执行顺序固定为:几何 → 光谱 → 稳定性 → 类别。
- 过滤完成后,生成过滤评估报告(总数、保留率、各类样本数前后对照),可选保存 PNG 柱状图。
- 输出 GeoJSON 采用原子落盘 + 文件锁,避免并发写入与半写文件。
输入 / 输出与参数(面板字段一览)
| 分组 | 字段 | 类型 / 取值 | 说明 |
|---|---|---|---|
| ③ 输出与执行 | 输出文件路径 | 路径 | 过滤后的样本 GeoJSON。 |
| 保存过滤统计图(PNG) | 勾选 | 保存“前后类分布”对照图。 | |
| 开始样本过滤 | 按钮 | 触发执行;运行日志实时写入“④ 状态信息”。 |
④ 状态信息
- 显示线程安全的节流日志,包括:坐标系处理、字段缺失、各阶段过滤后的样本数量、类别前后对照等(便于排错)。
公式与解释
- 紧凑度(几何规则性)
$$ \mathrm{Comp}(\mathcal P)=\frac{4\pi A(\mathcal P)}{\left[L(\mathcal P)\right]^2},\quad \mathrm{Comp}\in(0,1]. $$
- $A(\mathcal P)$ 与 $L(\mathcal P)$ 分别在等积/UTM投影内测得;$\mathrm{Comp}\to1$ 表示形状更接近圆形或规则面(过滤掉过细长/锯齿样本)。
- 光谱一致性(总体标准差,ddof=0)
$$ \mu=\frac{1}{n}\sum_{i=1}^n x_i,\qquad \sigma=\sqrt{\frac{1}{n}\sum_{i=1}^n (x_i-\mu)^2 } . $$
- 以 $\sigma$ 衡量“多边形内部的同质性”,$\sigma$ 越小越适合作为训练样本。
- 当同一基名命中多字段(多时相/多来源)时,按
all/any/mean三策略与阈值 $\tau$ 判断是否保留。
- 稳定性(跨时空/尺度的一致性)
$$ \max_j |z_j|\le\theta, \quad z_j=\frac{1}{n_j}\sum_{i=1}^{n_j} y_{ij}, $$
其中 $y_{ij}$ 为样本内第 $j$ 个稳定性字段在像元 $i$ 的取值,$z_j$ 为该字段的分区均值(先做掩膜与像元下限检查)。
- 坐标一致性
- 若 npz 中含
crs_epsg,将样本 GeoJSON 重投影到该 EPSG,确保掩膜与指标统计在同一栅格坐标系中完成。
使用建议
阈值与策略建议
-
几何:
A_min建议 ≥ 20–50(像元^2),视分辨率与地物最小斑块而定;C_min建议 0.25–0.40,用于剔除狭长边界碎片或抽稀误差面。
-
光谱一致性(
any更宽松、all最严格,mean兼顾鲁棒性):- NDVI:$\tau \in [0.04,0.08]$(林地/草地可偏小;农田多时相样本可放宽至 0.10);
- MNDWI(水体):$\tau \in [0.03,0.07]$;
- NDBI(建成区):$\tau \in [0.05,0.10]$。
经验法则:可先用
any+ 稍紧阈值,对“内混严重的样本”更敏感;若误删较多,再转mean。
-
稳定性:
- 选择来自“⑤/⑥/⑦”的变化或离散度指标(如
dNDVI,NBR_range,GLCM_contrast_std); - 阈值 $\theta$ 建议 0.15–0.30。若需要“标准样本”,可取 0.15;若要覆盖轻微季节/光照变化,取 0.25–0.30。
- 对具有明显季节性(农田、湿地)的样本,优先选同季影像或放宽 $\theta$。
- 选择来自“⑤/⑥/⑦”的变化或离散度指标(如
-
像元与腐蚀:
n_min建议 ≥ 25;小斑块或边界复杂区域可设置e=1–2,显著降低边界混合影响。
-
类别均衡:
- 若训练目标包含少数类,建议先不过滤类别数,完成第一轮训练与样本诊断后再做精修;
- 也可使用“类别增广/重采样”与本过滤并用。
典型工作流
- 先勾选几何过滤(
A_min=30, C_min=0.30)清掉形状异常样本。 - 启用光谱一致性,
mode=any,阈值以ndvi:0.06,mndwi:0.05,ndbi:0.07起步。 - 选取 2–4 个稳定性指标(如
dNDVI,NBR_range),$\theta=0.20$。 - 查看统计图与日志,微调阈值;必要时将
mode=mean以提高鲁棒性。 - 最后再启用类别样本数约束(如 25–50)做均衡收尾。
日志与排错要点
- CRS 不一致:日志会提示并自动重投影或给出警告(无 CRS 时默认假定正确)。
- 阈值基名不匹配:会提示“未找到可用的光谱阈值字段(按
:::前缀匹配)”,请检查阈值串与 npz 字段基名。 - 稳定性字段缺失:日志会列出缺失字段并跳过。
- 过滤结果核查:结束时输出“总样本数/保留率/各类前后对照”,可快速评估是否过滤过严或过宽。
执行顺序提醒:流水线固定为 几何 → 光谱 → 稳定性 → 类别,请据此设置阈值与字段,以获得期望的样本质量。
[4] 生成数据集(Landsat 土地覆盖)
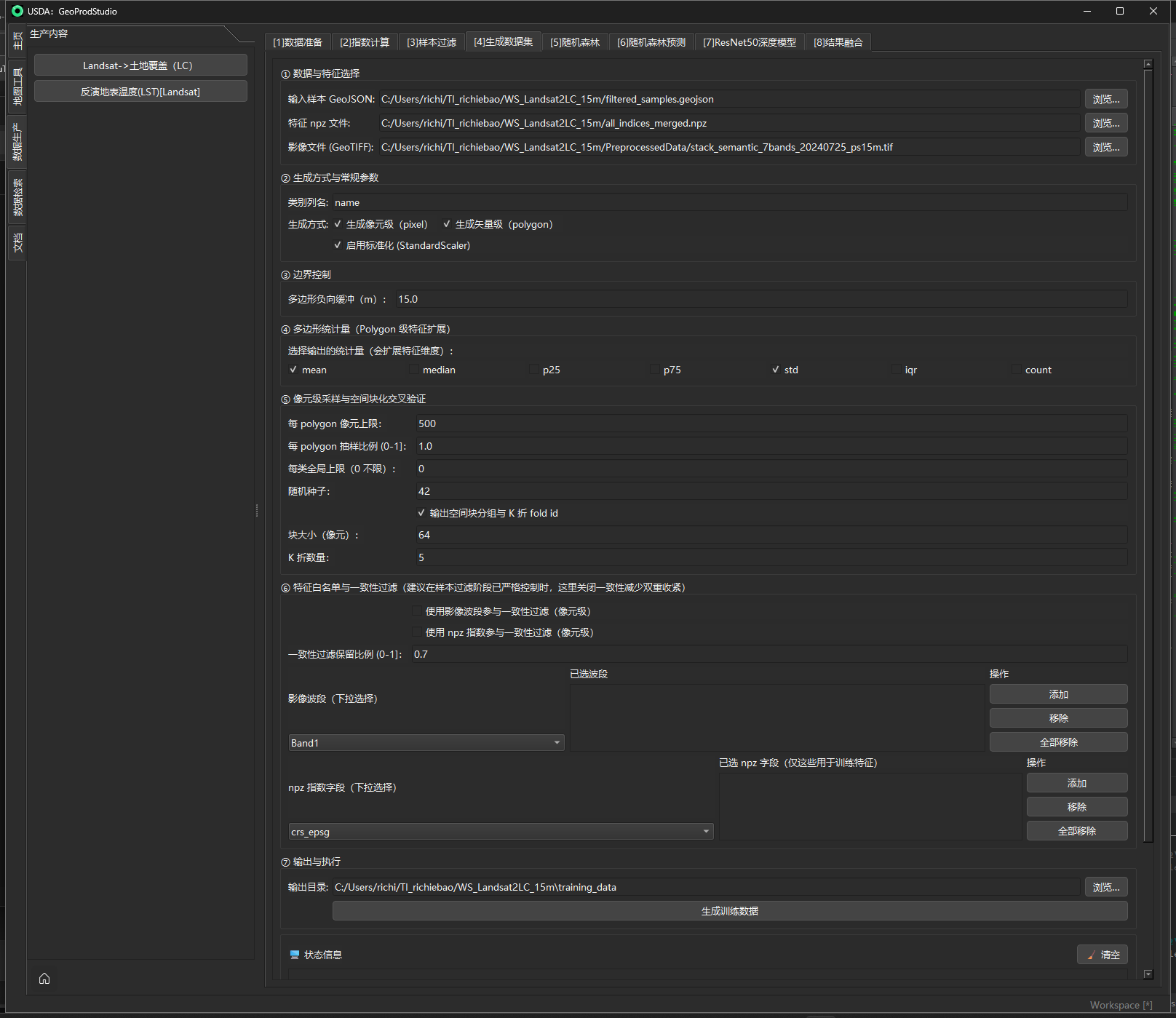
① 数据与特征选择
目的
指定训练样本矢量(GeoJSON)、特征集合(.npz)与(可选)参考影像,以便后续统计、像元采样与一致性过滤。UI 会根据所选 .npz 自动列出可用指标字段,根据 GeoTIFF 自动列出 Band 列表。
机制/实现(要点)
- 读取 GeoJSON、npz(包含 transform、可选 crs_epsg)并构造特征字典
band_dict;仅保留二维数值数组作为特征。若 npz 指定了坐标系,则将样本重投影至该坐标系;否则按样本中心经纬度推断 UTM 分带。 - transform 用于把像元行列与地理空间对应;若缺失将给出警告(不推荐无 transform)。
输入/输出与参数(面板字段一览)
| 字段 | 类型 | 说明 | 备注/默认 |
|---|---|---|---|
| 输入样本 GeoJSON | 路径 | 过滤后的样本面/类字段在②设置 | 支持自动重投影到 npz 的 crs_epsg 或推断 UTM |
| 特征 npz 文件 | 路径 | 包含 transform、可选 crs_epsg 与多个二维指标数组 |
读取后自动填充“npz 指数字段下拉框” |
| 影像文件 (GeoTIFF) | 路径 | 仅当启用“一致性过滤(基于影像波段)”时使用 | 读取后自动填充 Band1…BandN |
代码入口:
run_training_data_generation(... )第 1–3 步读取 GeoJSON/npz/CRS 并筛选二维数值特征。
使用建议
- .npz 应来自“[2] 指数计算/合并索引”的输出,确保大小一致并附带
transform与坐标信息。 - 若影像用于一致性过滤,请确保其大小与 .npz 内数组一致,否则自动忽略该项。
② 参数设置(常规)
目的
定义生成模式(polygon/pixel/both)、类名字段与是否标准化。
机制/实现
-
生成模式:
polygon:对每个样本面做分区统计,输出面级特征;pixel:在样本面内产生像元级样本(可做空间块化 CV);both:同时生成两套数据。
-
StandardScaler:若开启,对特征按列做零均值单位方差标准化,并保存
*_scaler.pkl。
输入/输出与参数
| 字段 | 类型 | 说明 | 默认 |
|---|---|---|---|
| 类别列名 | 字符串 | GeoJSON 中表示类别的字段 | name |
| 生成模式 | 单选 | polygon / pixel / both | pixel(UI 默认) |
| 启用标准化 | 复选 | StandardScaler | ✔ |
使用建议
- 面级特征适合传统 ML 模型或 QA 统计;像元级适合 RF/深度网络训练与验证。
- 长期部署时建议开启标准化,便于模型稳定复现。
③ 边界控制
目的
以负向缓冲剔除地物边界像元,减小混合像元对特征与标签的污染。
机制/实现
对每个 polygon 以 buffer_meters 做 负缓冲:
$$ \tilde{P} ;=; \mathrm{buffer}(P,,-b), \quad b>0 $$
若缓冲后为空,则该面被跳过。缓冲后的几何用于 zonal stats 与像元采样掩膜。实现参见 extract_zonal_stats_dataframe 与像元抽样流程。
参数
| 字段 | 类型 | 说明 | 默认 |
|---|---|---|---|
| 多边形负向缓冲(m) | 浮点 | polygon 内缩距离 | 15(UI 默认) |
使用建议
- 高分影像或边界不确定区域可适当加大(20–30 m)。
- 面积很小的样本可能被全部“吃掉”,请关注日志里的 NaN 行统计。
④ 多边形统计量(Polygon 级特征扩展)
目的
对选定的每个指标在 polygon 内做多统计量聚合,扩展特征维度。
机制/实现
设面 $S$ 内的某一指标像元值集合为 ${x_i}_{i=1}^{n}$,则:
- mean(均值) $\displaystyle \mu=\frac{1}{n}\sum_{i=1}^{n}x_i$
- median(中位) 样本 50% 分位数 $Q_{0.5}$
- p25/p75(分位) $Q_{0.25},, Q_{0.75}$
- std(标准差;实现用总体标准差 $ddof{=}0$) $\displaystyle \sigma=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i-\mu)^2}$
- iqr(四分位距) $\mathrm{IQR}=Q_{0.75}-Q_{0.25}$
- count(有效像元个数) $n$(剔除非有限值后计数)。
统计值按 name_stat 命名并拼接为输出特征。
参数(勾选将被计算)
| 选项 | 含义 | 备注 |
|---|---|---|
| mean / median / p25 / p75 / std / iqr / count | 见上 | 统计列名为 <指标>_<统计量> |
使用建议
- 分位数 + IQR 对异常值鲁棒,常与 mean/std 组合;
- 对“类内方差大”的光谱指数,建议开启 median、p25/p75 与 iqr。
⑤ 像元级采样与空间块化交叉验证(Pixel)
目的
在 polygon 内生成像元级训练样本,支持一致性过滤、按面/按类采样与空间块化 K 折,并保存阶段计数方便审计。
机制/实现(核心步骤)
-
一致性过滤(可选,来源于影像 Band 和/或 npz 指数的子特征):
- 对每个 polygon,将所选子特征堆叠为矩阵 $X \in \mathbb{R}^{n \times K}$,计算均值向量 $\mathbf{\mu}$ 与欧氏距离 $d_i = | \mathbf{x}_i - \mathbf{\mu} |_2$。
- 取分位阈值 $q = \mathrm{Quantile}_{\alpha}(d)$,仅保留 $d_i \le q$ 的像元($\alpha$ 为“保留比例”)。
-
每 polygon 抽样:按“最大像元数
max_n和/或比例ratio”随机采样(先一致性过滤,再抽样)。 -
全局每类上限:若指定
per_class_cap,对每个数值标签限流至最多 $C$ 条,缓解类不平衡。 -
标准化:若启用,对拼接后的全体像元特征做 StandardScaler。
-
空间块化分组 + K 折:以像元行列坐标 $(r,c)$ 与块尺寸 $b$ 生成 block 编号
$$ g=\Big\lfloor\frac{r}{b}\Big\rfloor\times10^6+\Big\lfloor\frac{c}{b}\Big\rfloor,\quad \text{fold_id}=g\bmod k $$
并保存 groups / groups_block / fold_ids,避免时空泄漏。
阶段计数 A/B/C(有效→一致性→抽样后)会写入
meta_counts_pixel便于溯源。
参数(像元级与 CV)
| 字段 | 类型 | 说明 | 默认 |
|---|---|---|---|
| 每 polygon 像元上限 | 整数 | max_n |
500 |
| 每 polygon 抽样比例 | 浮点 | 0–1 | 1.0 |
| 每类全局上限 | 整数 | 限制每个类别的像元数 | 0=不限 |
| 随机种子 | 整数 | 重现性 | 42 |
| 块大小(像元) | 整数 | 空间块尺寸 $b$ | 64 |
| K 折数量 | 整数 | k | 5 |
使用建议
- 一致性过滤:地物内部光谱差异大时非常有效。推荐:
keep_fraction=0.7,子特征可以选 NDVI、MNDWI、NBR + Red/NIR/SWIR Band。 - 空间块化 CV 对遥感建模很关键,能模拟“换区”泛化;小区域可适当减小
b,但不要过小以免泄漏。 - 每类上限建议配合类别不均衡数据(如:耕地 ≫ 湿地)。
⑥ 特征选择与一致性过滤
目的
限定用于训练的 npz 指标子集(白名单),以及选择参与一致性过滤的影像波段/指数子集与保留比例。
机制/实现
- 若白名单非空,仅使用存在于 npz 内的白名单字段作为训练特征;若白名单均不存在将报错。
- 影像波段一致性过滤需影像大小与 npz 数组一致;Band 名如
Band3将按序号读取。 - 指数一致性过滤直接按所选 npz 字段构造子空间参与步骤⑤的距离-分位筛选。
参数(过滤/白名单)
| 字段 | 类型 | 说明 | 默认 |
|---|---|---|---|
| 使用影像波段参与一致性过滤 | 复选 | 需同时选择影像与 Band | 关 |
| 使用 npz 指数参与一致性过滤 | 复选 | 需选择 npz 字段 | 关 |
| 保留比例(0–1] | 浮点 | $\alpha$;越小越严格 | 0.7 |
| 已选 Band / 已选 npz 字段 | 列表 | 参与过滤或作为训练特征白名单 | — |
使用建议
- 白名单常用于特征优选或与上一轮模型保持一致。
- 典型的一致性子特征组合:
[NDVI, NBR, MNDWI, Band4(Red), Band5(NIR), Band6(SWIR1)]。
⑦ 输出与执行
目的
选择输出目录并执行生成;完成后保存两类数据与工具文件。
输出文件(可能生成)
| 文件 | 含义 |
|---|---|
training_data_polygon_Xy.npz |
面级:X, y, feature_names, classes, meta_counts_polygon, groups 等(每面为一组)。 |
training_data_pixel_Xy.npz |
像元级:X, y, feature_names, classes, transform, coords, poly_ids, groups[, groups_block, fold_ids], meta_counts_pixel。 |
*_scaler.pkl |
StandardScaler(若启用)。 |
*_label_encoder.pkl |
标签编码器(名称↔数字)。 |
生成过程与日志由 UI 的“状态信息”面板实时显示与记录。
⑧ 状态信息(日志与排错要点)
- CRS 与投影:若 GeoJSON 无 CRS,将提示并默认设为 EPSG:4326 后再重投影;若 npz 含
crs_epsg将以其为准。 - transform:缺失时会警告并尝试推断(不推荐)。
- 影像尺寸不一致:将提示并忽略影像波段一致性过滤。
- 未提取到有效像元或所有 polygon 被过滤会抛出错误,请检查缓冲/阈值/掩膜与抽样参数。
- 完成时会打印样本量、特征维度与类别映射。
公式与解释补充
-
IQR:$\mathrm{IQR} = Q_{0.75} - Q_{0.25}$;对异常值鲁棒,可与 $\sigma$ 对照使用以量化类内离散性。
-
一致性过滤(聚类式中心距筛选):在子特征空间 $X$,以 L2 距离衡量像元与中心的偏离,按分位阈值 $\alpha$ 保留:
$$ d_i = | \mathbf{x}_i - \mathbf{\mu} |2 , \quad \mathrm{keep} \iff d_i \le \mathrm{Quantile}{\alpha}(d) $$
其中 $\alpha \in (0, 1]$ 对应“保留比例”。
-
空间块化 K 折:
$$ g = \Big\lfloor \frac{r}{b} \Big\rfloor \times 10^6 + \Big\lfloor \frac{c}{b} \Big\rfloor , \quad \text{fold_id} = g \bmod k $$
通过 blocks 将相邻像元划为同组,避免空间泄漏。
综合使用建议(推荐配置)
- 快速起步:
模式=pixel,buffer=15 m,per_polygon_max=500,block=64,k=5,keep_fraction=0.7,并启用 StandardScaler。 - 稳健泛化:务必启用空间块化 CV;白名单仅保留解释力强且物理意义清晰的指数(NDVI/NBR/MNDWI + 红/近红外/SWIR)。
- 类别不均衡:设置
per_class_cap或在下游训练阶段启用类权重;同时关注日志里的阶段计数(A/B/C/D)。
生成结果将作为[5] 随机森林 / [7] ResNet50 的输入。
[5] 随机森林(Random Forest)训练
面板:[5]随机森林。本节按圆圈序号逐段说明:① 工作空间与数据 → ② 训练参数 → ③ 特征选择 → ④ 输出与执行 → ⑤ 状态信息。实现与默认值来自
rf_trainer_panel.py与train_classifier.py。
① 工作空间与数据
目的
加载由“[4] 生成数据集”导出的训练 .npz(像元级或面级),并准备后续训练所需的元信息。
机制 / 实现
- 必备字段:
.npz至少包含X, y;可选:feature_names, coords, transform, crs_epsg/crs_wkt, groups(亦兼容groups_block/fold_ids)。加载后先做标签清洗(移除空/None),再用LabelEncoder数字化标签。若提供groups或能由coords构造空间分组,则启用严格组级切分(GroupShuffleSplit)。
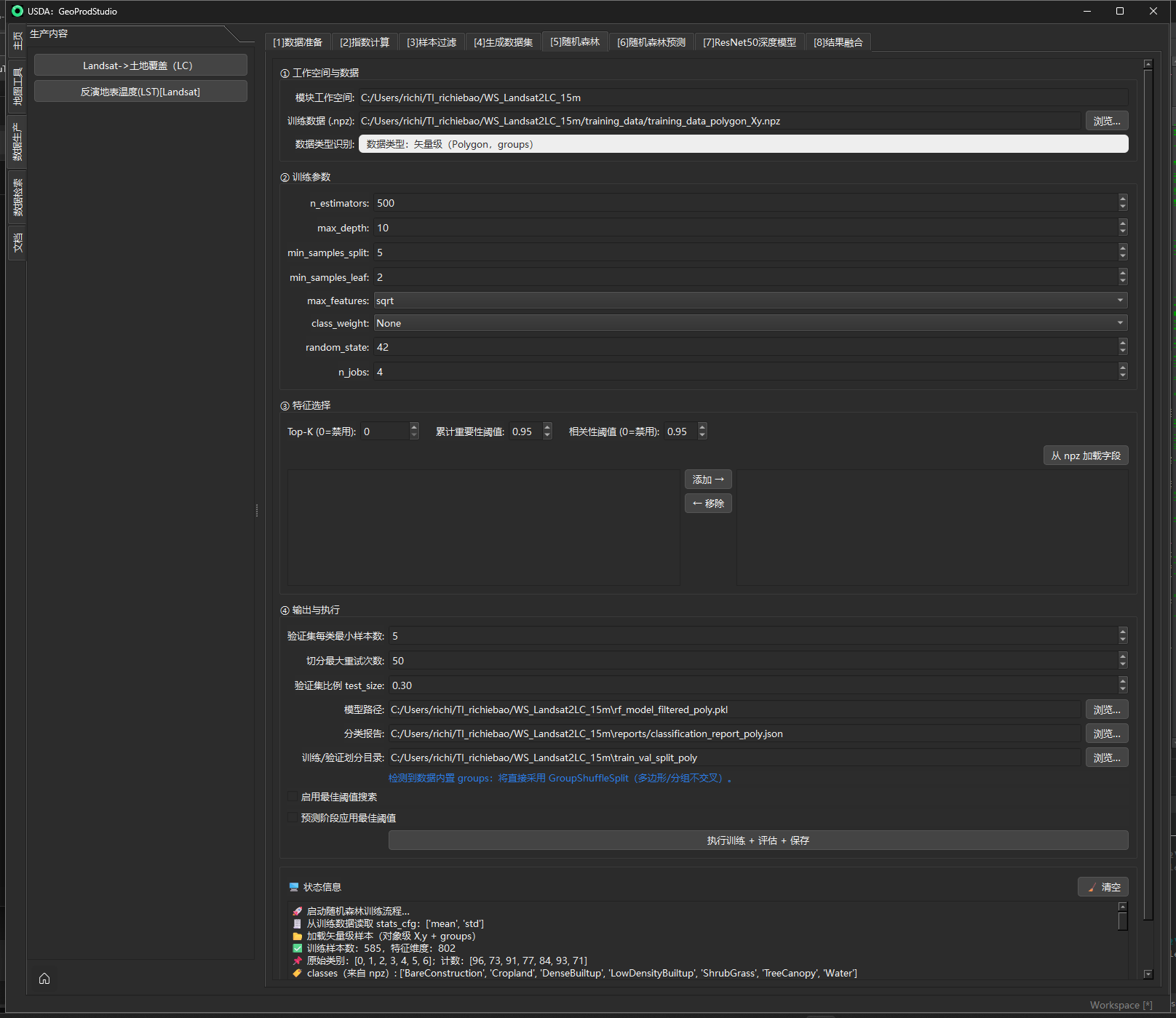
🚀 启动随机森林训练流程…
🧾 从训练数据读取 stats_cfg:['mean', 'std']
📂 加载矢量级样本(对象级 X,y + groups)
✅ 训练样本数:585,特征维度:802
📌 原始类别:[0, 1, 2, 3, 4, 5, 6];计数:[96, 73, 91, 77, 84, 93, 71]
🏷 classes(来自 npz): ['BareConstruction', 'Cropland', 'DenseBuiltup', 'LowDensityBuiltup', 'ShrubGrass', 'TreeCanopy', 'Water']
🧩 使用外部 groups 做分组划分(GroupShuffleSplit)
🔒 已启用严格组级分块(GroupSplit 断言通过)
🧪 验证集各类样本数(受约束切分):{0: 32, 1: 23, 2: 22, 3: 24, 4: 21, 5: 38, 6: 16}(满足约束:True)
🔖 split_by = provided_groups
📊 初始特征数:802
📊 重要性筛选后(累计≥0.95):559
📊 与强制保留合并后:559
🔗 开始相关性筛选(|r|≥0.95 判为高相关)
📊 相关性筛选后:335(移除 265)
📊 最终保留特征数:335
- ndvi_contrast:::glcm_textures_w5_std
- ndvi_homogeneity:::glcm_textures_w5_std
- ndvi_asm:::glcm_textures_w5_mean
- ndvi_asm:::glcm_textures_w5_std
- ndvi_energy:::glcm_textures_w5_std
- ndvi_glcm_std:::glcm_textures_w5_std
- ndvi_lbp_std:::glcm_textures_w5_std
- evi_entropy:::glcm_textures_w5_std
- evi_contrast:::glcm_textures_w5_mean
- evi_contrast:::glcm_textures_w5_std
- evi_energy:::glcm_textures_w5_mean
- evi_glcm_mean:::glcm_textures_w5_std
- evi_glcm_std:::glcm_textures_w5_mean
- savi_asm:::glcm_textures_w5_std
- msavi2_asm:::glcm_textures_w5_std
- msavi2_energy:::glcm_textures_w5_std
- msavi2_glcm_mean:::glcm_textures_w5_std
- msavi2_glcm_std:::glcm_textures_w5_mean
- msavi2_glcm_std:::glcm_textures_w5_std
- msavi2_lbp_std:::glcm_textures_w5_mean
- mndwi_entropy:::glcm_textures_w5_std
- mndwi_homogeneity:::glcm_textures_w5_mean
- mndwi_energy:::glcm_textures_w5_mean
- mndwi_energy:::glcm_textures_w5_std
- mndwi_glcm_mean:::glcm_textures_w5_mean
- mndwi_glcm_mean:::glcm_textures_w5_std
- mndwi_glcm_std:::glcm_textures_w5_std
- mndwi_lbp_std:::glcm_textures_w5_mean
- mndwi_lbp_std:::glcm_textures_w5_std
- ndbi_asm:::glcm_textures_w5_std
… 其余 305 项省略
🚀 使用随机森林训练
🧪 模型评估:
==============================
准确率 (Accuracy) : 0.8068
宏平均 F1 分数 : 0.8130
加权平均 F1 分数 : 0.8053
==============================
precision recall f1-score support
0 0.78 0.78 0.78 32
1 1.00 0.57 0.72 23
2 0.80 0.91 0.85 22
3 0.86 0.79 0.83 24
4 0.64 0.76 0.70 21
5 0.77 0.87 0.81 38
6 1.00 1.00 1.00 16
accuracy 0.81 176
macro avg 0.84 0.81 0.81 176
weighted avg 0.82 0.81 0.81 176
📄 分类报告已保存至 C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\reports/classification_report_poly.json
💾 模型已保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_poly.pkl
📝 特征名已保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_poly.pkl_features.npy
💾 特征名也已保存为 Joblib:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_poly.pkl_selected_features.pkl
🔖 标签映射已保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_poly.pkl_label_mapping.json
🧾 模型元信息(含 stats_cfg)已保存:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_poly.pkl_meta.json
✅ 训练集和验证集分别保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\train_val_split_poly
✅ 训练流程完成,结果已保存
![]()
🚀 启动随机森林训练流程…
📂 加载像元级样本(对象级 X,y + coords)
✅ 训练样本数:22599,特征维度:401
📌 原始类别:[0, 1, 2, 3, 4, 5, 6];计数:[3132, 3261, 3207, 3404, 3332, 3695, 2568]
🏷 classes(来自 npz): [np.str_('BareConstruction'), np.str_('Cropland'), np.str_('DenseBuiltup'), np.str_('LowDensityBuiltup'), np.str_('ShrubGrass'), np.str_('TreeCanopy'), np.str_('Water')]
🗺️ 坐标系识别为投影坐标(米),自适应网格由 500.0 m 调整为 500.0 m
🧩 自适应分组成功:unique_groups=16
🔒 已启用严格组级分块(GroupSplit 断言通过)
🧪 验证集各类样本数(受约束切分):{0: 1849, 1: 452, 2: 1142, 3: 861, 4: 1049, 5: 783, 6: 644}(满足约束:True)
🔖 split_by = grid_groups_from_coords
⚠️ 训练数据未提供 stats_cfg,已从特征名粗略推断:['mean', 'std']
📊 初始特征数:401
📊 重要性筛选后(累计≥0.95):205
📊 与强制保留合并后:205
🔗 开始相关性筛选(|r|≥0.95 判为高相关)
📊 相关性筛选后:94(移除 137)
📊 最终保留特征数:94
- ndvi_contrast:::glcm_textures_w5
- evi_entropy:::glcm_textures_w5
- evi_contrast:::glcm_textures_w5
- msavi2_contrast:::glcm_textures_w5
- mndwi_contrast:::glcm_textures_w5
- mndwi_homogeneity:::glcm_textures_w5
- mndwi_energy:::glcm_textures_w5
- mndwi_glcm_mean:::glcm_textures_w5
- mndwi_glcm_std:::glcm_textures_w5
- ndvi_contrast:::glcm_textures_w7
- ndvi_asm:::glcm_textures_w7
- ndvi_glcm_std:::glcm_textures_w7
- evi_contrast:::glcm_textures_w7
- evi_homogeneity:::glcm_textures_w7
- evi_energy:::glcm_textures_w7
- evi_glcm_std:::glcm_textures_w7
- savi_homogeneity:::glcm_textures_w7
- msavi2_contrast:::glcm_textures_w7
- mndwi_entropy:::glcm_textures_w7
- mndwi_contrast:::glcm_textures_w7
- mndwi_asm:::glcm_textures_w7
- mndwi_glcm_std:::glcm_textures_w7
- ndbi_contrast:::glcm_textures_w7
- ndbi_homogeneity:::glcm_textures_w7
- bsi_contrast:::glcm_textures_w7
- bsi_glcm_std:::glcm_textures_w7
- nbr_contrast:::glcm_textures_w7
- ndmi_homogeneity:::glcm_textures_w7
- evi:::spectral_indices_base_20240725
- awei_sh:::spectral_indices_base_20240725
… 其余 64 项省略
🚀 使用随机森林训练
🧪 模型评估:
==============================
准确率 (Accuracy) : 0.7577
宏平均 F1 分数 : 0.7619
加权平均 F1 分数 : 0.7588
==============================
precision recall f1-score support
0 0.91 0.57 0.70 1849
1 0.54 0.72 0.62 452
2 0.86 0.83 0.84 1142
3 0.58 0.91 0.71 861
4 0.79 0.75 0.77 1049
5 0.65 0.76 0.70 783
6 0.99 1.00 0.99 644
accuracy 0.76 6780
macro avg 0.76 0.79 0.76 6780
weighted avg 0.79 0.76 0.76 6780
📄 分类报告已保存至 C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\reports/classification_report_pixel.json
💾 模型已保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_pixel.pkl
📝 特征名已保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_pixel.pkl_features.npy
💾 特征名也已保存为 Joblib:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_pixel.pkl_selected_features.pkl
🔖 标签映射已保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_pixel.pkl_label_mapping.json
🧾 模型元信息(含 stats_cfg)已保存:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\rf_model_filtered_pixel.pkl_meta.json
✅ 训练集和验证集分别保存至:C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\train_val_split_pixel
✅ 训练流程完成,结果已保存
-
数据类型自动识别(像元优先):
- 存在
coords⇒ 判为像元级(Pixel); - 仅存在
groups(且无coords)⇒ 判为矢量级(Polygon); - 两者皆无 ⇒ 退化为分层随机切分(Stratified)。
面板会在“数据类型识别”徽标中提示,并据此自动调整默认输出后缀为
_pixel或_poly,避免覆盖既有结果。
- 存在
-
坐标系判别与米→度换算:若
coords存在,先用crs_epsg/crs_wkt(不足则用坐标范围)判断是否为地理坐标;若是,则把**网格尺寸(米)**按中位纬度换算到经纬度,再做网格化分组。 -
自适应网格:当按给定网格大小仅得到 <2 个分组时,程序会自动缩小网格(多档比例)直至获得 ≥2 个分组,并在日志中给出“等效网格”。若仍失败且启用了严格组分,会暂时降级为分层切分并给出警告。
组号定义示意(米坐标;若为度则先做米→度换算):
$$ g = \Big\lfloor \frac{x}{\Delta_x} \Big\rfloor \times 10^{7}
- \Big\lfloor \frac{y}{\Delta_y} \Big\rfloor. $$
输入 / 输出与参数(面板字段一览)
| 分组 | 字段 | 类型 | 说明 |
|---|---|---|---|
| ① 工作空间与数据 | 模块工作空间 | 只读 | 用于默认保存路径。 |
| 训练数据(.npz) | 路径 | 读取 X,y,feature_names,coords,groups… 等字段;选后自动探测类型与切换默认输出后缀。 |
使用建议
.npz建议包含coords与crs_epsg,可确保严格空间不交叉切分与可复现日志(投影/地理坐标与等效网格)。若没有coords/groups则会退化为分层切分。
② 训练参数
目的
配置随机森林(RF)超参数与并行度。
机制 / 实现
UI 直连 RandomForestClassifier 的核心超参:
n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features, class_weight, random_state, n_jobs。
默认值:500 / 10 / 5 / 2 / “sqrt” / “balanced_subsample” / 42 / 4。
训练时先(可选)做特征筛选,再以该参数集拟合最终 RF:
$$ \hat{f}(\mathbf{x}) = \mathrm{mode}!\left( \big{, T_b(\mathbf{x}) ,\big}{b=1}^{B} \right), \qquad B = n{\mathrm{estimators}}. $$
输入 / 输出与参数(面板字段一览)
| 字段 | 类型 | 默认 | 说明 |
|---|---|---|---|
| n_estimators | int | 500 | 森林规模(树数)。 |
| max_depth | int | 10 | 单棵树最大深度。 |
| min_samples_split | int | 5 | 内部节点继续划分的最小样本数。 |
| min_samples_leaf | int | 2 | 叶节点最小样本数。 |
| max_features | enum | sqrt | 分裂时的特征抽样策略:sqrt/log2/auto。 |
| class_weight | enum/None | balanced_subsample | 类权重;也支持 “None”。 |
| random_state | int | 42 | 随机种子。 |
| n_jobs | int | 4 | 并行线程数。 |
使用建议
- 首次建模推荐从默认值开始:
500×10的 RF 通常稳健;如样本极大可降到 300。 - 类别不均衡时选择
balanced或balanced_subsample更稳;也可与[4]阶段的样本均衡策略联动。
③ 特征选择
目的
通过重要性筛选与相关性裁剪两步,去除冗余特征;面板“已选列表”充当强制保留清单。
机制 / 实现
-
重要性筛选(两种模式“二选一”)
- 若设置 Top-K>0:直接取按 RF 重要性降序的前 K 个;
- 否则:按累计重要性阈值 (\tau) 取前 K 使 (\sum_{j=1}^K I_{(j)}\ge\tau)(默认 (\tau=0.95);步长 0.01 可调)。 注:不是交集,Top-K>0 时覆盖累计阈值模式。
-
相关性裁剪(可选) 在候选子集上计算相关矩阵,若 (|r_{pq}|\ge r_{\text{thr}})(默认 0.95;0 表示禁用),保留顺序靠前者、移除后者;“强制保留”永不移除。日志会给出移除数与最终保留数并列出前 30 个特征名。
-
加载字段到“强制保留” “从 npz 加载字段”会把
feature_names以及其他二维数组键(排除核心字段)列入“可选列表”,可移动到“已选列表”作为强制保留。
输入 / 输出与参数
| 字段 | 类型 | 默认 | 取值 / 范围 | 说明 | ||
|---|---|---|---|---|---|---|
| Top-K(0=禁用) | int | 0 | ≥0 | Top-K>0 时使用 Top-K 模式,否则使用“累计阈值”模式。 | ||
| 累计重要性阈值 | float | 0.95 | (0,1] | 仅在 Top-K=0 时生效;步长 0.01。 | ||
| 相关性阈值(0=禁用) | float | 0.95 | [0,1] | ( | r | \ge) 阈值即视为高度相关并移除后者;0 表示不启用。 |
| 从 npz 加载字段 | 按钮 | — | — | 将可用列名载入“可选列表”。 | ||
| 可选 ↔ 已选 | 列表 | — | — | “已选”即强制保留,不会在筛选阶段被移除。 |
小提示:把 NDVI、MNDWI、NBR、Red/NIR/SWIR 等关键物理量放入“已选”,可避免被自动筛选误删。
④ 输出与执行
目的
进行严格无渗漏的训练/验证切分,支持最佳阈值搜索,并把模型、报告与训练/验证拆分落盘备查。
机制 / 实现
-
严格组级分块 + 受约束切分
- 若提供
coords:按“米→度自适应网格”生成 groups;若失败则降级为分层切分并写警告; - 若提供
groups:直接 GroupShuffleSplit; - 否则:分层切分(提示可能渗漏)。
之后使用“受约束随机切分”:每次切分后检查验证集每类计数 ≥ 设定下限,不满足则重试,最多
max_trials次;返回(train_idx, test_idx, ok_flag, counts)。 小规模组(≤20)时,优先尝试穷举式选组,尽量满足所有类别覆盖并贴近目标验证规模。
- 若提供
-
训练与最佳阈值(可选) 训练 RF 后,若启用“最佳阈值搜索”,对每一类在 (t\in{0.01,0.02,\ldots,0.99,0.5}) 上网格搜索,最大化 one-vs-rest 的 F1,得到 (t_c^) 并保存到
model.pkl_thresholds.json。评估阶段若勾选“预测阶段应用最佳阈值”,将按 ({t_c^}) 做多类决策(无类达阈值则回退argmax)。 -
评估与保存 输出
accuracy / macro-F1 / weighted-F1与classification_report.json,并在_meta中写入切分方式、网格设置、是否应用阈值等。模型旁另存:标签映射、(可选)精选特征名、每类最佳阈值与stats_cfg(见下)。同时导出训练/验证拆分两份.npz与split_meta.json(含索引、组号、CRS、切分参数等)。
输入 / 输出与参数(面板字段一览)
| 字段 | 类型 | 默认 | 说明 |
|---|---|---|---|
| 网格单元尺寸(米) | float | 1000.0 | 基于 coords 生成 groups 的网格(自动米↔度换算 + 自适应缩放);若 groups 已存在,此行在 UI 中隐藏。 |
| 验证集每类最小样本数 | int | 5 | 受约束切分的每类下限。 |
| 切分最大重试次数 | int | 50 | 不满足下限时的最大重试次数。 |
| 验证集比例 test_size | float | 0.20 | 验证集占比。 |
| 模型路径 | 路径 | workspace/rf_model_filtered{_pixel/_poly}.pkl |
根据数据类型自动加后缀。 |
| 分类报告 | 路径 | workspace/reports/classification_report{_pixel/_poly}.json |
— |
| 训练/验证划分目录 | 目录 | workspace/train_val_split{_pixel/_poly} |
写出 train/val .npz 与 split_meta.json。 |
| 启用最佳阈值搜索 | 复选 | 关 | 搜索每类最优概率阈值(步长 0.01 + 固定 0.5)。 |
| 预测阶段应用最佳阈值 | 复选 | 关 | 评估时按阈值进行多类决策。 |
| 执行训练 + 评估 + 保存 | 按钮 | — | 运行完整流程;日志实时输出。 |
使用建议
- 空间分块:土地覆盖更关注“换区泛化”,建议始终提供
coords或外部groups;网格 500–2000 m 通常合适。 - 最小样本约束:类别偏少时把“每类最小样本数”调到 ≥5,并将“重试次数”提到 50–100。
- 最佳阈值:当追求 Macro-F1 且类间概率分布差异大时开启;整体精度优先时可关闭。
⑤ 状态信息(日志与排错)
- 数据检查:打印“样本数/特征维度/原始类别分布/npz 中 classes”,以及“数据类型识别(像元/矢量/未知)”。选择
.npz后会即时探测并切换默认输出后缀。 - CRS 与网格:提示坐标系类型(地理/投影),及自适应后的等效网格与
unique_groups。 - 特征筛选:依次输出“初始/重要性后/合并强保留/相关性后/最终保留”的特征数,并列出前 30 个特征。
- 切分结果:显示验证集各类样本数与是否满足约束,并标注
split_by(grid_groups_from_coords / provided_groups / stratified)。 - 评估报告:打印 Accuracy、Macro-F1、Weighted-F1,并把完整
classification_report.json与_meta落盘。
公式与解释
- 随机森林投票
$$ \hat{y}
\arg\max_{c} \sum_{b=1}^{B} \mathbf{1}!\left( T_b(x) = c \right) $$
- 重要性累计阈值
$$ K
\min\left{ k:; \sum_{j=1}^{k} I_{(j)} \ge \tau \right}, \qquad \tau \in (0,1]. $$
实现逻辑:若 Top-K > 0,则使用 Top-K;否则使用本式的累计阈值。
- 高度相关去冗余
若 $\lvert r_{pq}\rvert \ge r_{\text{thr}}$,则保留顺序靠前者、移除后者(强制保留始终保留)。
- 组级切分
$$ g = \Big\lfloor \frac{x}{\Delta_x} \Big\rfloor \times 10^{7}
- \Big\lfloor \frac{y}{\Delta_y} \Big\rfloor, $$
以 $g$ 做 GroupShuffleSplit;当为地理坐标时先做米$\to$度换算,并支持自适应缩放。
- 受约束随机切分
重复抽样,直到每类验证样本数 $\ge m$(或达到最大重试次数);对小规模组($\le 20$)先做穷举式选组,以最大化覆盖并贴近目标规模。
- 阈值搜索(一类对其余)
$$ t_c^\star = \arg\max_{t \in \mathcal{G}} \mathrm{F1}_{\mathrm{ovr}}(t), \qquad \mathrm{F1} = \frac{2PR}{P+R}. $$
预测时对每类应用 $p_c \ge t_c^\star$;若无类通过,则回退到 $\arg\max_c, p_c$。
快速配置(推荐值)
- 基础:
n_estimators=500, max_depth=10, min_samples_leaf=2, max_features=sqrt, class_weight=balanced_subsample; - 特征选择:Top-K=0 +
累计重要性≥0.95,再|r|≥0.95的相关性裁剪;把 NDVI/MNDWI/NBR/Red/NIR/SWIR 放入强制保留; - 切分:
grid=1000 m, min_per_class=5, max_trials=50, test_size=0.2(存在coords时自动自适应网格;小规模组优先穷举); - 阈值:追求 Macro-F1 时,启用“最佳阈值搜索”并在评估时应用。
[6] 随机森林预测(栅格/矢量制图)
面板:[6]随机森林预测。本节按圆圈序号依次说明 ① 工作空间与输入数据 → ② 执行 → ③ 状态信息,并给出机制/实现、I/O 与参数(面板字段一览)、公式与解释、使用建议与排错。核心逻辑见
predict_map.py与 UI 面板tab_rf_predict_panel.py。
① 工作空间与输入数据
目的
为两种预测级别准备资源并配置输出:
- 像元级(Raster):基于整幅特征栈逐像元分类并输出彩色分类 GeoTIFF;
- 矢量级(Polygon):对分割面逐面统计→按训练期特征顺序对齐→分类;可选栅格化输出。
机制 / 实现
共同特性
- 日志注入:UI 将线程安全日志函数注入后端,所有阶段统一写入“状态信息”。
- 原子写出:GeoTIFF/GeoJSON 全流程使用简单文件锁与“
.tmp→原子替换”,避免并发损坏。
像元级(Raster)
![]()
![]()
- 载入 npz → 取二维数值特征:仅把
.npz中二维数值数组视为特征;自动排除transform/crs_*。 - GeoTransform:健壮解析 6 参数或 3×3 矩阵到
Affine,并用于输出。 - 拼接特征矩阵:展平后按列堆叠为
n_pixel × n_feature。 - 与训练期“筛选特征”对齐:若存在
<model>.pkl_selected_features.pkl,严格按此重排与筛列;缺失即报错。 - 有效像元与缺失填补:仅当“用于预测的列中**≥ min_valid_ratio**(默认 0.80)的值为有限数”才对该像元预测;其他像元输出
255(NoData)。在缩放前,先以列中位数对全维缺失填补(使用有效像元的中位数)。 - 标准化:用训练期
StandardScaler对全维transform,再按sel_idx取列喂模型,以保证与训练维度一致。 - 预测:常规
model.predict;若启用“最佳阈值”,则按阈值进行多类判别(见“公式与解释”)。 - 写盘:以参考影像 profile为模板(统一投影/分辨率/压缩),
dtype=uint8、nodata=255、compress=LZW;可写颜色表。
矢量级(Polygon)
-
载入分割 GeoJSON + 特征 npz;把 npz 中的基础特征栅格与
transform/CRS读出。 -
CRS 对齐:若 GeoJSON 与 npz 的 CRS 不同,先重投影到 npz 的 CRS(优先 EPSG)。
-
统计项来源:优先读
<model>.pkl_meta.json内的stats_cfg;若缺失,则从model.feature_names_in_或meta.selected_features中解析列名后缀(_mean/_std/_median/_p25/_p75/_iqr/_count/_min/_max)自动推断;若仍无,退回默认mean/std。
-
面内统计:对每个 polygon 与每个基础特征计算所需统计量(列名
<feat>_<stat>);支持负/正缓冲;- 单进程/多进程:当估计工作量
n_poly × n_feat × n_stat ≥ 200,000时,自动采用多进程(ProcessPoolExecutor+ mmap);UI 可设置进程数。
- 单进程/多进程:当估计工作量
-
特征对齐与缩放:
- 用
all_stat_cols组装全量矩阵→列中位数填补 NaN→(可选)整体scaler.transform; - 再按
selected_features或feature_names_in_的顺序选列喂模型(确保与训练一致)。
- 用
-
预测与写出(极简字段):
- 仅写出
seg_id, rf_pred, rf_pred_idx, rf_proba, geometry五列到 GeoJSON; rf_proba统一为标量(多类概率取最大值)。
- 仅写出
-
可选栅格化:把
rf_pred_idx栅格化到参考影像网格,输出uint8GeoTIFF(nodata=255, LZW)。
输入 / 输出与参数(面板字段一览)
| 分组 | 字段 | 类型 | 默认/示例 | 说明 |
|---|---|---|---|---|
| 预测级别 | 选择模式 | 下拉 | 像元级 / 矢量级 | UI 两套区域随模式切换显示。 |
| ① 工作空间与输入数据(Raster) | 模块工作空间 | 只读 | — | 记忆与回填路径。 |
| 特征 npz 路径 | 文件 | *.npz | 只读取二维数值键为特征;需含 transform。 |
|
| 模型(.pkl)路径 | 文件 | *.pkl | [5] 阶段训练输出。 | |
| scaler(.pkl)路径 | 文件 | *.pkl | 训练期 StandardScaler(必需)。 |
|
| 参考影像(.tif) | 文件 | *.tif | 作为输出 profile 模板。 | |
| 启用最佳阈值(.json) | 复选 | 关 | 勾选后按阈值进行多类判别。 | |
| 最佳阈值文件 | 文件 | *_thresholds.json | 与模型配套(可选)。 | |
| 输出分类图(.tif) | 文件 | classified_map.tif | uint8, nodata=255, LZW。 |
|
| ① 工作空间与输入数据(Polygon) | 分割 GeoJSON | 文件 | *.geojson | 面级预测输入;内部自动CRS 对齐。 |
| 特征 npz 路径 | 文件 | *.npz | 读取基础特征与 transform/CRS。 |
|
| 模型(.pkl)路径 | 文件 | *.pkl | — | |
| scaler(.pkl)路径 | 文件 | *.pkl | 可空(若训练期未使用可不填)。 | |
| 输出结果 GeoJSON | 文件 | polygon_rf_pred.geojson | 仅写极简字段(见上)。 | |
| 负/正缓冲距离(m) | float | 0.0 | 统计前对 polygon 做 buffer。 | |
| 浮点写出精度 | int | 4 | GeoJSON 落盘浮点四舍五入精度。 | |
| 将多边形结果栅格化 | 复选 | 关 | 勾选后开启下两项。 | |
| 参考影像(对齐) | 文件 | *.tif | 用于栅格化对齐。 | |
| 输出栅格(.tif) | 文件 | polygon_rf_pred.tif | uint8, nodata=255, LZW。 |
UI 还提供进程数输入(矢量级),并把线程安全日志桥接到面板。
② 执行
目的
启动整幅预测:
- Raster:特征拼接 → 缩放 →(可选)阈值判别 → 写出彩色分类图;
- Polygon:面内统计 → 特征对齐/缩放 → 预测 →(可选)栅格化 → 写出极简 GeoJSON/GeoTIFF。
机制 / 实现(全过程)
- 异步执行:统一走
TaskRunner,按钮执行期自动置灰;结束后恢复。 - 关键内部阈值:
min_valid_ratio=0.80(Raster),控制有效像元判定(未在 UI 暴露)。 - 并行统计(Polygon):默认自动选择进程数(CPU-1,最多 16);UI 可覆盖。分片块大小 256,多进程 mmap 读取 npz,显著降低内存复制与进程启动开销。
- 写盘:所有产物均加锁 + 原子替换;GeoTIFF 统一
uint8, nodata=255, LZW;Polygon GeoJSON 仅写极简字段以减小体积。
③ 状态信息
-
关键日志
- Raster:特征键数量/示例、有效像元统计、筛选特征对齐与否、scaler/model 路径、阈值文件、输出路径、类别计数。
- Polygon:多边形数/基础特征数/统计项、是否并行与进程数、对齐用的真实特征列、缺失列提示、输出路径、类别列表与数量。
-
工具:提供“清空日志”按钮;对字段缺失与并发启动做前置拦截提示。
公式与解释(可直接用于论文)
1) 有效像元判定与缺失填补(Raster)
设用于预测的列维数为 $d$,第 $i$ 个像元有效特征计数为:
$$ v_i = \sum_{j=1}^{d} \mathbf{1}!\left[, x_{ij}\ \text{是有限数} ,\right]. $$
像元 $i$ 为 有效 当:
$$ v_i \ge \left\lceil \rho , d \right\rceil, \quad \rho = \texttt{min_valid_ratio} = 0.80. $$
随后对 全体列 以 列中位数 填补缺失:
$$ \tilde{x}{ij} = \begin{cases} x{ij}, & x_{ij}\ \text{有限},[6pt] \mathrm{median}{k:,\text{有效}}(x{kj}), & \text{否则}. \end{cases} $$
这样,scaler 的缩放维度与训练完全一致。
2) 标准化与特征对齐
训练期 StandardScaler 在全维上拟合 $(\mu, \sigma)$。预测时:
$$ \mathbf{z} = \frac{\tilde{\mathbf{x}} - \mu}{\sigma} $$
随后按训练期“筛选特征”的顺序索引选列喂模型。
3) 多类阈值判别(可选)
若模型输出后验概率 $\mathbf{p}i = (p{i1}, \dots, p_{iC})$,
阈值 $\mathbf{t} = (t_1, \dots, t_C)$(默认 $0.5$;可由 *_thresholds.json 覆盖):
$$ S_i = {, c \mid p_{ic} \ge t_c ,}, $$
$$ \hat{y}i = \begin{cases} \displaystyle \arg\max\limits{c \in S_i}, p_{ic}, & S_i \neq \varnothing, \[6pt] \displaystyle \arg\max\limits_{c}, p_{ic}, & S_i = \varnothing . \end{cases} $$
4) 面内统计(Polygon)
对 polygon 掩膜内像元集合 $\Omega$ 与某一基础特征栅格 $F$,可计算:
$$ \text{mean} = \frac{1}{|\Omega|}\sum_{u \in \Omega} F(u), \qquad \text{std} = \sqrt{\frac{1}{|\Omega|}\sum_{u \in \Omega} \big(F(u) - \bar{F}\big)^2}, \quad \dots $$
最终列名按 <feat>_<stat> 展开,并 按模型期望的列顺序对齐。
使用建议
- 资源一致性(Raster):npz 的尺寸/transform 必须与参考影像一致;若训练期启用了“筛选特征”,务必确保
<model>_selected_features.pkl与 npz 字段完全匹配。 - 阈值开关:训练阶段若进行了“最佳阈值搜索”,建议启用并指向配套
*_thresholds.json;否则直接采用argmax。 - NoData(Raster):受云/阴影或特征缺失影响的像元输出 255;后处理可叠加掩膜。
- 并行与稳定(Polygon):大任务建议开启并行,进程数不宜超过物理核数;GeoJSON/GeoTIFF 已内置文件锁与原子写出,无需额外加锁。
- 栅格化(Polygon):若需发布为底图,建议使用与目标服务一致的参考影像进行栅格化,并在外部构建金字塔。
日志与排错(常见信息)
🎯 特征字段 N 个(示例前20):...:确认 Raster 特征清单。✅ 有效像元(≥XX% 特征可用):k / n:若为 0,整幅将输出 NoData 并提示。📌 使用筛选特征对齐:M 个/✅ 已按筛选列表重排…:若缺失,将抛出“筛选特征 X 在 npz 中缺失”。🧮 Polygon 统计项:mean,std,…:核对将用于面内统计的指标集合。⚙ 启用多进程统计:估算工作量=... 单元,进程数=...:确认是否触发并行。💾 已保存 GeoTIFF/GeoJSON:path:输出成功;随后打印各类别计数。⚠️ 栅格化重投影失败,将按当前 CRS 直接 burn(可能错位):检查 GeoJSON/参考影像 CRS。
[7] ResNet50 深度模型(像元级 Patch 分类)
面板:[7]ResNet50深度模型。按圆圈序号逐段说明:① 数据与样本 → ② 训练配置 → ③ 预测配置 → ④ 输出与执行 → ⑤ 状态信息。核心实现见
resnet_train.py / resnet_predict.py,UI 面板见tab_resnet_panel.py。
① 数据与样本
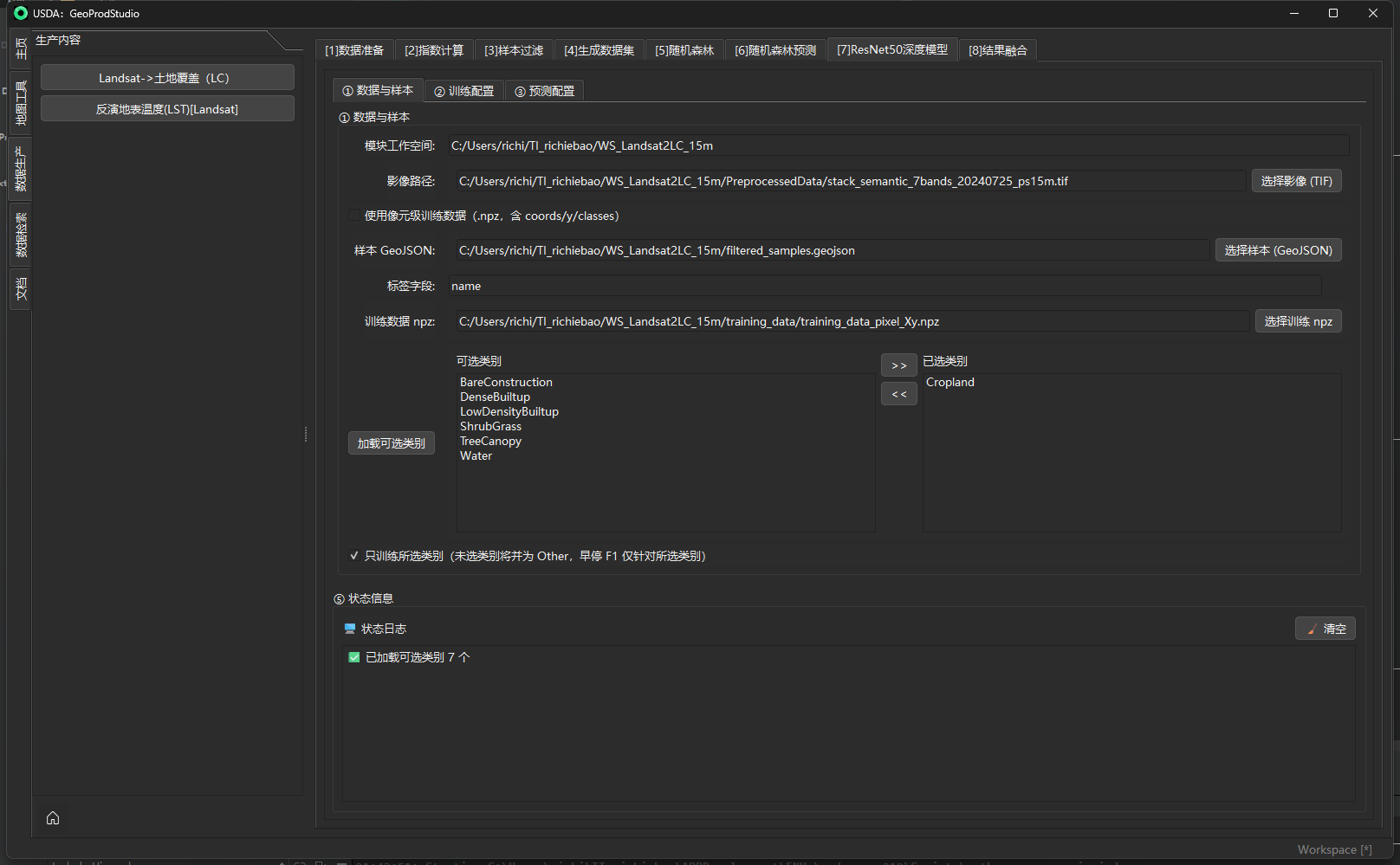
目的
从多光谱影像裁剪定尺 (C,H,W) patch(默认按 1/10000 反射率归一化),构建像元级训练样本;支持两条输入路径:GeoJSON 或 像元级 .npz。
机制 / 实现
- GeoJSON → Patch:居中裁剪,自动 CRS 对齐;返回
(X:float32[C,H,W]/10000, y:int64, classes:list, weights:float32);权重来自中心点→几何边界的距离指数衰减(边界更“难”,权重更大)。支持目标类二分类 / 未选类合并 Other的标签整形。 - 像元级 .npz → Patch:必须包含
coords, y, classes(可选weights),按坐标在线裁剪;同样支持**“单一目标类→{Other,Target}”与“多选类+Other”**的无丢样本重映射。 - 轻量数据增强(像素级友好):四向旋转、低概率左右翻、轻量尺度扰动(等效 RandomResizedCrop)、弱高斯噪声。
- UI 类别选择:从 GeoJSON 或 npz 读取可选类别到“双列表”;勾选“只训练所选类别”→未选合并 Other,早停 F1 仅在所选类别上度量(UI 层完成映射)。
输入 / 输出与参数(面板字段)
| 字段 | 类型 | 默认/示例 | 说明 |
|---|---|---|---|
| 模块工作空间 | 只读 | — | 作为默认输入/输出根目录。 |
| 影像路径(.tif) | 文件 | — | 多波段 GeoTIFF,裁剪与预测源。 |
| 使用像元级 npz | 复选 | 关 | 勾选后启用 .npz 路线、禁用 GeoJSON 输入。 |
| 样本 GeoJSON | 文件 | *.geojson | 训练样本(点或面),居中裁剪。 |
| 标签字段 | 文本 | name | GeoJSON 类别列名。 |
| 训练数据 npz | 文件 | *.npz | 含 coords,y,classes(可 weights)。 |
| 加载可选类别 | 按钮 | — | 读取类别值到“双列表”。 |
| 只训练所选类别 | 复选 | 关 | 未选→Other;早停 F1 仅在所选上。 |
② 训练配置
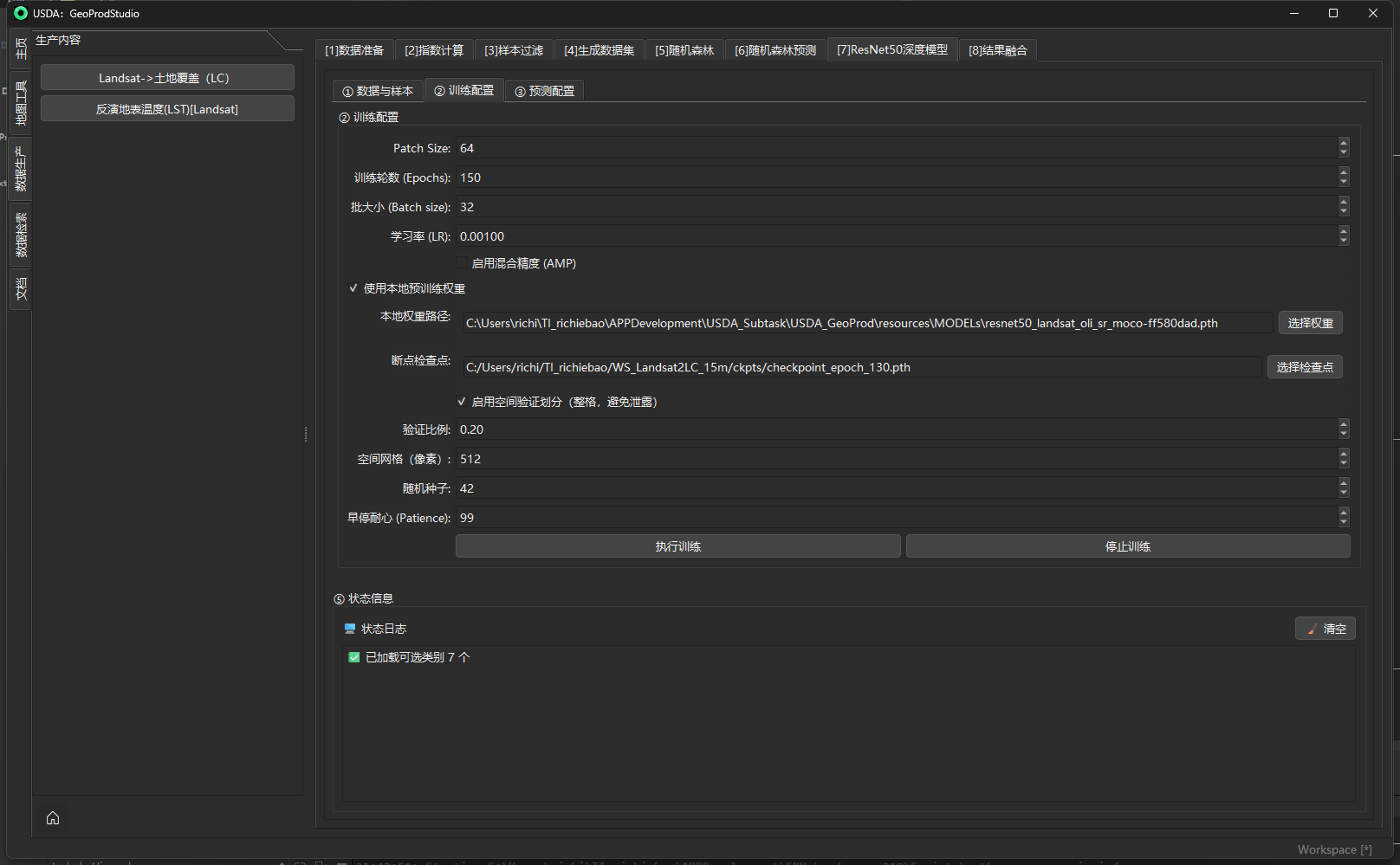
目的
配置 ResNet50、损失与验证划分;提供 AMP、类均衡、早停与断点恢复,保证可复现实验。
机制 / 实现
- 模型构建:优先 TorchGeo ResNet50 (LANDSAT_OLI_SR_MOCO);也支持本地预训练权重或跳过权重初始化。分类头改为
Dropout(0.2)+Linear(in_features,num_classes),支持channels_last。 - 类别权重(指数缩放):按计数
n_c计算 [ w_c\propto (n_c)^{-\alpha},\ \alpha=\texttt{class_weight_exponent}\ (\text{默认 }0.35), ] 归一化后用于 CrossEntropy / Focal / Hybrid 损失。 - 损失:默认 加权交叉熵(
label_smoothing=0.05);可选 FocalLoss(γ=1.5) 或 HybridFocalDice(宏 Dice + Focal)。 - 优化/调度/加速:Adam(+
weight_decay=1e-4);CosineAnnealingWarmRestarts;AMP(torch.amp.GradScaler)与可选torch.compile(max-autotune)。 - 验证划分:若数据集带
coords→ 空间分块验证(整格(row,col)//block_size);否则随机分层。两者均保证验证集每类至少 1 个样本。 - 类均衡采样:训练集 DataLoader 使用 WeightedRandomSampler(1/freq)。
- 早停:以 Macro-F1 为判据;连续
patience轮无提升即停止,自动保存“最佳/最终”权重。 - 断点恢复:从
checkpoint_epoch_*.pth恢复(模型/优化器/epoch/曲线)。
输入 / 输出与参数(面板字段)
| 字段 | 类型 | 默认 | 说明 |
|---|---|---|---|
| Patch Size | int | 128 | 裁剪边长(像素 32–256)。 |
| Epochs | int | 50 | 训练轮数。 |
| Batch size | int | 64 | 训练批量。 |
| Learning rate | float | 1e-3 | Adam 学习率。 |
| 混合精度(AMP) | 复选 | 开 | CUDA 上启用。 |
| 使用本地预训练权重 | 复选 | 关 | 可选 .pth/.pt 路径;未填尝试默认权重。 |
| 断点检查点 | 文件 | — | 从 checkpoint 恢复。 |
| 启用空间验证 | 复选 | 关 | 起用整格空间划分。 |
| 验证比例 | float | 0.20 | 验证集占比。 |
| 空间网格(像素) | int | 512 | 分块大小(像素)。 |
| 随机种子 | int | 42 | 切分/采样随机种子。 |
| 早停耐心 | int | 10 | Macro-F1 早停耐心。 |
③ 预测配置
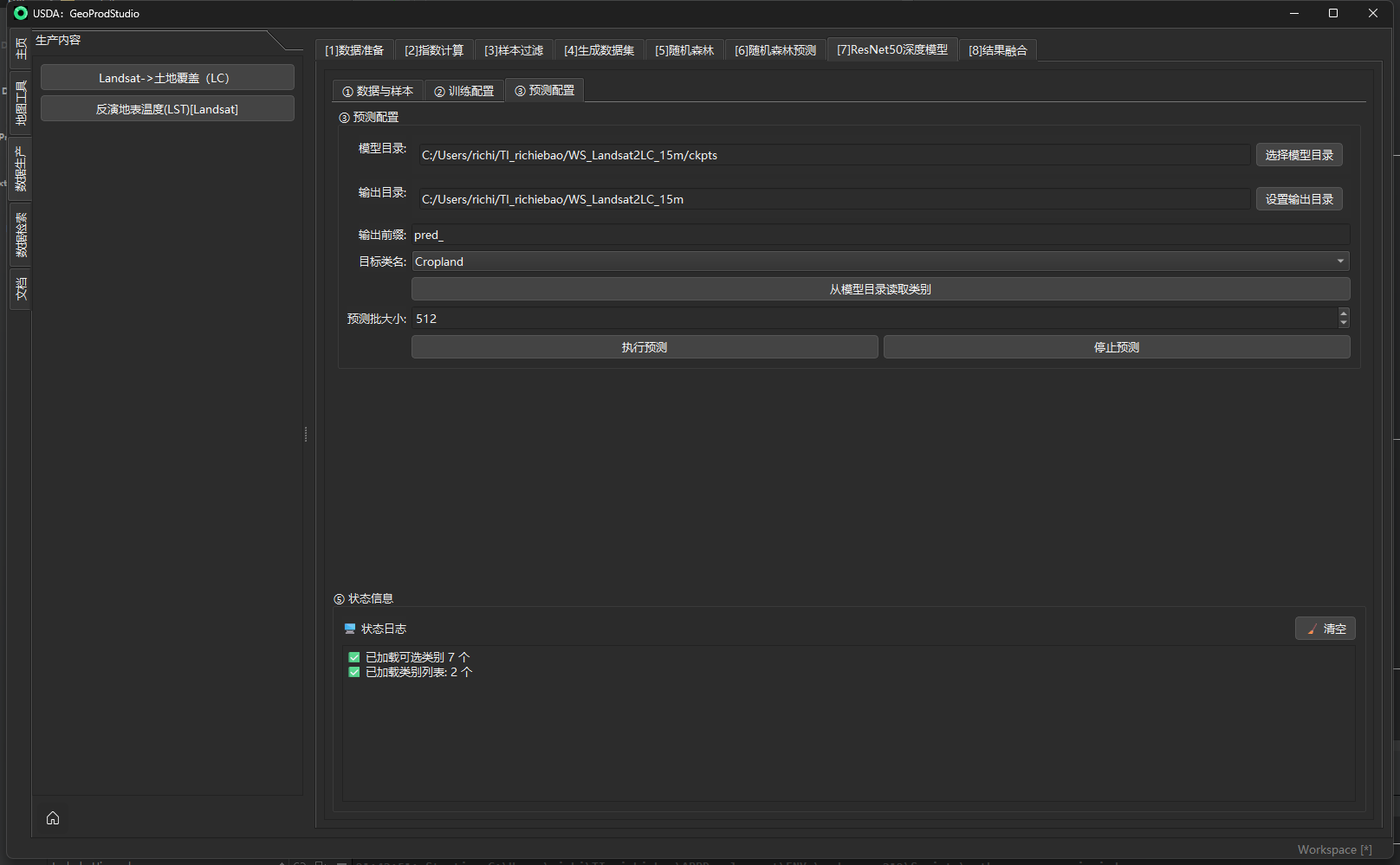
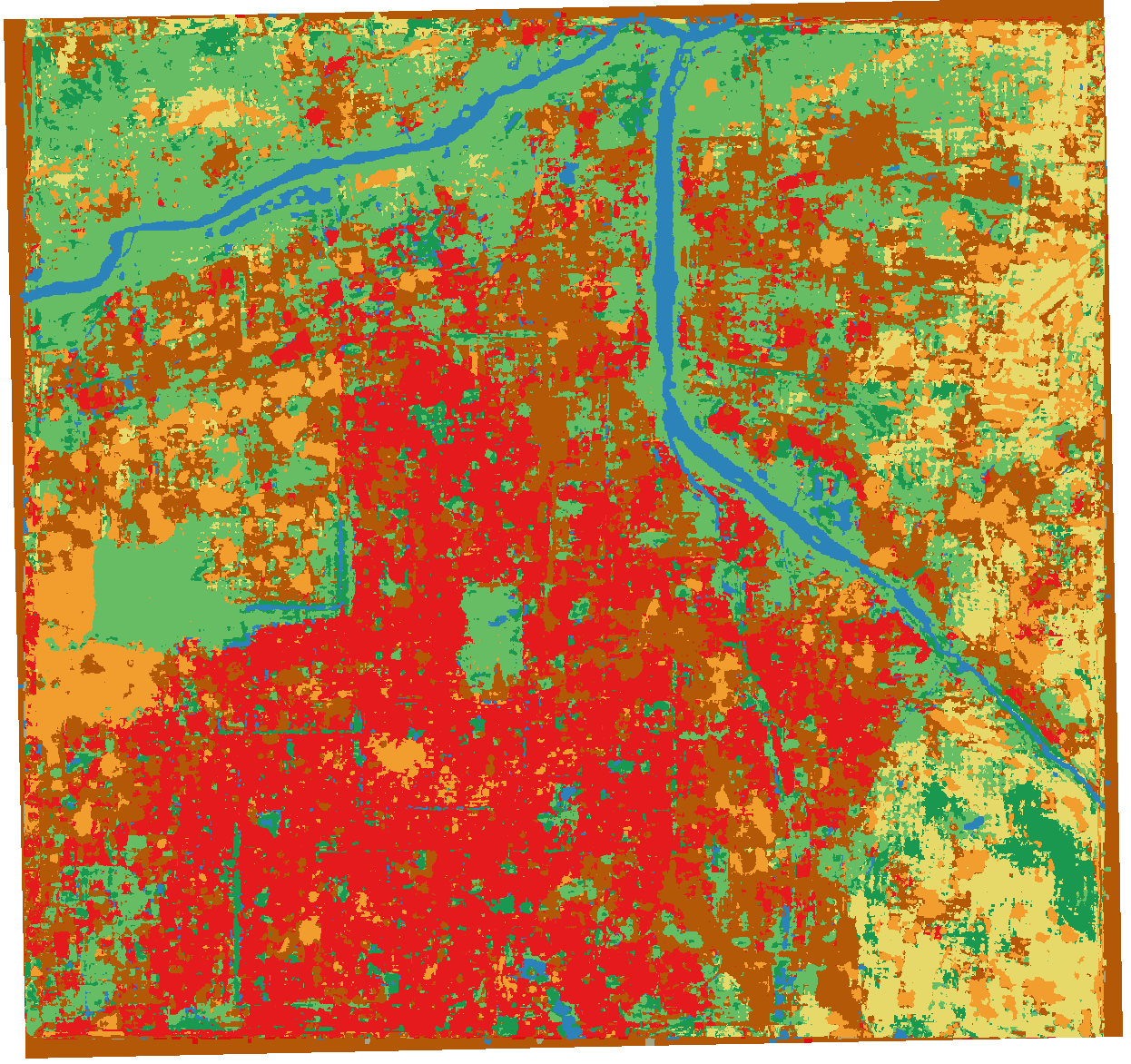

目的
加载模型目录(trained_resnet_model.pth + class_names.txt)并对整幅影像执行中心像元滑窗推理;可选输出目标类概率图。
机制 / 实现
-
模型加载:按影像波段数构建
torchgeo.resnet50(in_chans=C),替换分类头并载入权重;缺失/额外权重键位将记录计数。 -
中心像元滑窗:仅为有效中心输出类别与概率;边缘留空(由窗口半径决定)。按块(tile)读取+行写出,长幅大图稳定。
-
温度缩放(可关):(\mathrm{softmax}(z/\tau))。多尺度(64/128) + 融合(vote/smooth) 可选;也可一键关闭所有增强(像元级严格模式)。
-
中断机制:支持回调
stop_callback,UI “停止预测”即时生效。 -
输出:
*_class_map.tif:uint8,nodata=255(LZW 压缩);*_probabilities.tif:float32,count=num_classes;*_prob_<class>.tif:可选目标类概率。
参数一览(面板 + 后端要点)
| 字段/参数 | 类型 | 默认 | 说明 |
|---|---|---|---|
| 模型目录 | 目录 | 工作空间 | 需含 class_names.txt 与权重。 |
| 输出目录/前缀 | 目录/文本 | 工作空间/pred_ |
结果保存位置与命名前缀。 |
| 目标类名 | 下拉 | — | 额外输出该类概率图。 |
| 预测批大小 | int | 128(UI) | 实际按块内样本分批预测。 |
| patch_size | int | 64/128 | 后端可 64 或 128,多尺度时自动二倍。 |
| center_stride | int | 1 | 中心步长(>1 下采样预测)。 |
| multi_scale/use_blend/tau | bool/bool/float | 关/开/1.0 | 多尺度、融合方式与温度缩放。 |
| tile_size | int | 512 | Tile Buffer 尺寸。 |
| pixelwise_mode | bool | 关 | 一键严格像元模式(强制 patch=64,关闭多尺度/融合/温度/后处理)。 |
④ 输出与执行
目的
一键完成训练→评估→导出与整幅预测,并保证可中断/可恢复。
机制 / 实现
-
训练阶段
- 切分→采样→优化:空间/随机验证,类均衡采样,AMP + 余弦重启退火;每
checkpoint_every轮存断点;以 Macro-F1 选“最佳权重”。 - 导出:
trained_resnet_model.pth、trained_resnet_model_last.pth、class_names.txt、training_loss_curve.png、控制台分类报告。
- 切分→采样→优化:空间/随机验证,类均衡采样,AMP + 余弦重启退火;每
-
预测阶段
- 滑窗中心像元推理,可开多尺度与温度缩放;可选 3×3 轻后处理(
maximum_filter),默认关闭。 - 写盘策略:按行窗口写出,低内存占用;输出
class_map / probabilities / prob_<class>。
- 滑窗中心像元推理,可开多尺度与温度缩放;可选 3×3 轻后处理(
⑤ 状态信息(日志与排错)
- 训练端:打印类别计数→权重、切分规模(train/val)、每轮
TrainLoss/ValLoss/F1_macro/LR、早停提示、检查点/最佳权重保存路径;绘制损失曲线 PNG。 - 预测端:显示模型目录、类别数、权重加载缺失/额外键数、进度百分比、输出文件路径;若
class_names.txt不存在或为空→显式报错。 - UI 侧:线程安全日志、清空日志按钮;“停止训练/预测”均为可中断请求。
公式与解释
- 类别权重(指数缩放)
$$ w_c = \frac{(n_c)^{-\alpha}}{\sum_k (n_k)^{-\alpha}},\qquad \alpha = 0.35\ (\text{default}). $$
用于平衡长尾类别;当 $\alpha=0$ 时退化为等权。
- 交叉熵 / Focal / Hybrid(示意)
交叉熵损失:
$$ \mathcal{L}{\text{CE}} = -\frac{1}{B}\sum_i \sum_c w_c, \mathbf{1}[y_i=c] \log\frac{e^{z{ic}}}{\sum_k e^{z_{ik}}}. $$
Focal 损失:
$$ \mathcal{L}{\text{Focal}} = \frac{1}{B}\sum_i (1 - p{i,y_i})^{\gamma},\ell_i. $$
混合损失(Hybrid):
$$ \mathcal{L}{\text{Hybrid}} = (1-\lambda),\mathcal{L}{\text{Focal}}
- \lambda,(1-\text{Dice}_{\text{macro}}). $$
(实现含 label_smoothing=0.05,$\gamma=1.5$,$\lambda\approx0.35$。)
- 温度缩放与多尺度融合
$$ \mathbf{p} = \mathrm{softmax}(\mathbf{z}/\tau),\qquad \tau \ge 1. $$
$$ \mathbf{p}^* = \begin{cases} (\mathbf{p}{64} + \mathbf{p}{128}) / 2, & \text{smooth}, \[4pt] \arg\max\text{一致则用其;否则取最大置信的概率向量}, & \text{vote}. \end{cases} $$
vote模式以两尺度中最大置信者为准。
使用建议
- Patch 尺寸:Landsat 30 m 常用
64–128;若关注纯像元判别,建议开启 pixelwise_mode(固定 64,关多尺度/融合/温度/后处理)。 - 只训练所选类别:面向重点类(如水体/建筑)时勾选此项,未选并为 Other,并将早停 F1 聚焦于所选类,更贴合任务指标。
- 空间验证:遥感具强空间自相关,优先开启“整格划分(像素网格)”,防止泄露。
- 类不均衡:保持默认
class_weight_exponent=0.35即可,过大易过惩少数类。 - 稳定性:大图预测使用默认
tile_size=512即可;如显存紧张,降低batch_size。如需干净边界,可在预测后轻后处理(3×3 最大滤波)。
[8] 结果融合(RF × ResNet50 后融合与优选)
面板:[8]结果融合。按圆圈序号说明 ① 路径与数据 → ② 融合方法与参数 → ③ 执行 → ④ 状态信息,并给出机制/实现、I/O 参数表、公式与解释、使用建议/排错。核心实现见
fusion_selector_module.py与 UItab_fusion_panel.py。
① 路径与数据
目的
把主模型(通常为随机森林)分类图与 ResNet50 的分类/概率图对齐到同一空间基准,为随后 A–E 多种融合策略提供输入。
机制 / 实现
-
读取主图为参照:以主图的 transform/CRS/shape 作为目标空间。
-
空间对齐(reproject):
- 分类图:最近邻重采样,输出
nodata=255。 - 概率图:双线性重采样,输出
nodata=NaN(float32)。
- 分类图:最近邻重采样,输出
-
可选“所有类别概率图”:逐通道双线性对齐后堆叠为
(C,H,W)。 -
标签编码器:加载
label_encoder.pkl,将目标类名映射为索引(如Shrubland→3)。
输入 / 输出与参数(面板字段一览)
| 分组 | 字段 | 类型 | 默认/示例 | 说明 |
|---|---|---|---|---|
| ① 路径与数据 | 模块工作空间 | 只读 | — | 记忆路径。 |
| 主模型预测图 | 文件 | classified_map.tif | RF 等主分类结果(uint8,255=NoData)。 | |
| ResNet 分类图 | 文件 | predicted_center_class_map.tif | ResNet “中心像元”分类结果(uint8)。 | |
| ResNet 概率图 | 文件 | predicted_prob_target.tif | 目标类的概率图(float32)。 | |
| ResNet 所有类概率 | 文件 | predicted_center_all_probs.tif | 可选,(C,H,W) 概率;用于方法 E。 | |
| 标签编码器 pkl | 文件 | label_encoder.pkl | 含 classes_ 与 transform。 |
|
| 样本 npz | 文件 | train_val_split.npz | 用于评估(需含 coords,y)。 |
|
| 输出目录 | 目录 | …/ResNet_predictedTIFF | 融合图与报告输出位置。 |
② 融合方法与参数
目的
选择并配置 A–E 中的一种或多种策略;可一键多方法运行并自动选 F1 最优。
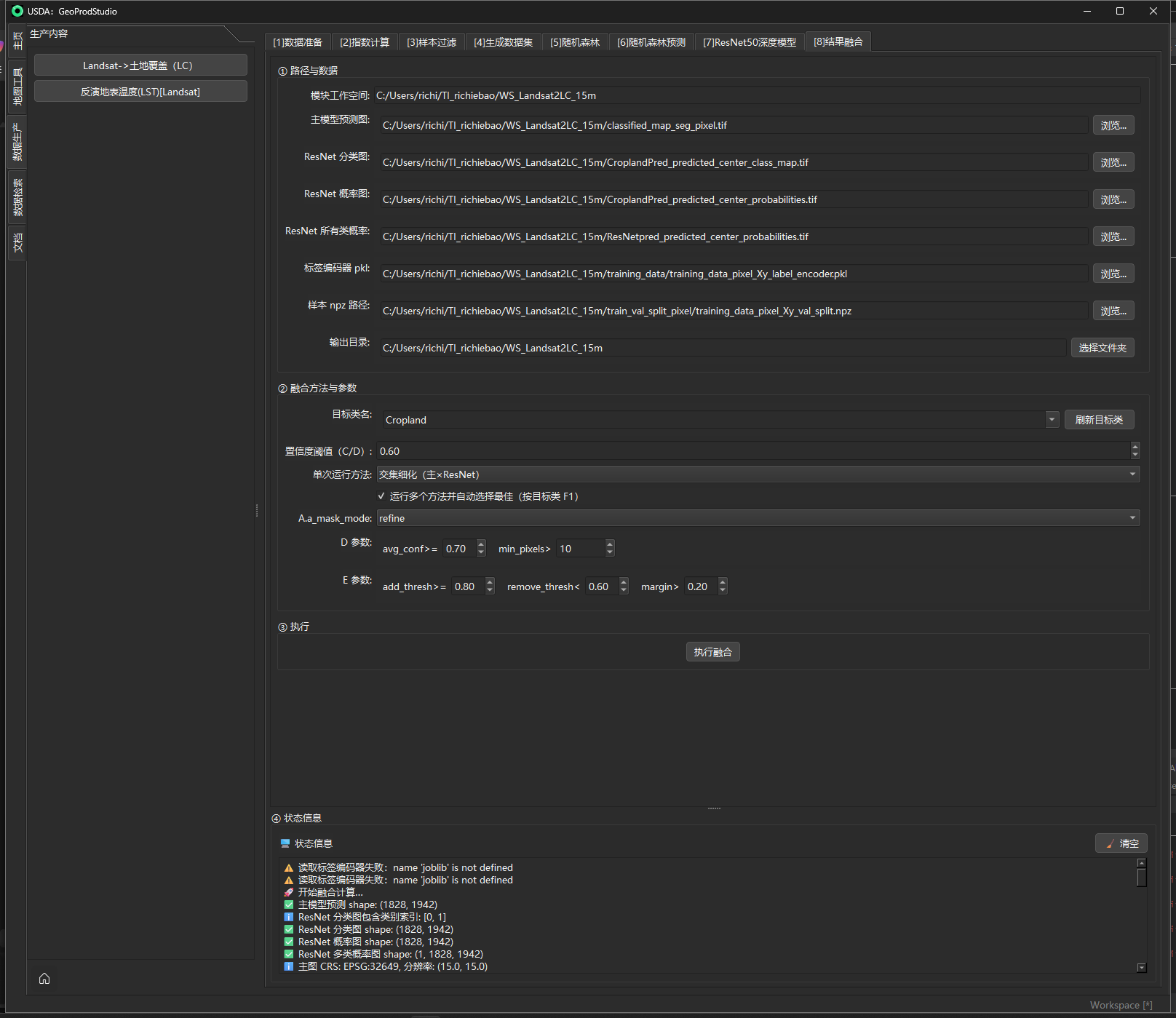
⚠️ 读取标签编码器失败:name 'joblib' is not defined
⚠️ 读取标签编码器失败:name 'joblib' is not defined
🚀 开始融合计算…
✅ 主模型预测 shape: (1828, 1942)
ℹ️ ResNet 分类图包含类别索引: [0, 1]
✅ ResNet 分类图 shape: (1828, 1942)
✅ ResNet 概率图 shape: (1828, 1942)
✅ ResNet 多类概率图 shape: (1, 1828, 1942)
ℹ️ 主图 CRS: EPSG:32649, 分辨率: (15.0, 15.0)
ℹ️ 分类 CRS: EPSG:32649, 分辨率: (15.0, 15.0)
ℹ️ 概率 CRS: EPSG:32649, 分辨率: (15.0, 15.0)
🧪 ResNet 二值图正类推断:label=1(mean_p0=0.861, mean_p1=0.965)
📐 A 方法融合策略: refine;交集像元数: 334761
📦 已保存: C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\fused_A.tif
融合图 shape: (1828, 1942)
验证集样本数量: 6780
coords 范围: 行[99-1807],列[33-1804]
有效预测样本数: 6780
最终有效样本数(已知标签): 6780
🎯 A 方法的 F1 分数: 0.8287
📊 分类报告:
precision recall f1-score support
BareConstruction 0.96 0.91 0.94 1849
Cropland 0.72 0.98 0.83 452
DenseBuiltup 0.93 0.98 0.95 1142
LowDensityBuiltup 0.90 0.93 0.91 861
ShrubGrass 0.96 0.73 0.83 1049
TreeCanopy 0.88 0.97 0.93 783
Water 1.00 1.00 1.00 644
accuracy 0.92 6780
macro avg 0.91 0.93 0.91 6780
weighted avg 0.93 0.92 0.92 6780
🧪 ResNet 二值图正类推断:label=1(mean_p0=0.861, mean_p1=0.965)
📐 D 保留连通域像元数: 3221427
📦 已保存: C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\fused_D.tif
融合图 shape: (1828, 1942)
验证集样本数量: 6780
coords 范围: 行[99-1807],列[33-1804]
有效预测样本数: 6780
最终有效样本数(已知标签): 6780
🎯 D 方法的 F1 分数: 0.1314
📊 分类报告:
precision recall f1-score support
BareConstruction 1.00 0.04 0.08 1849
Cropland 0.07 1.00 0.13 452
DenseBuiltup 1.00 0.04 0.08 1142
LowDensityBuiltup 0.00 0.00 0.00 861
ShrubGrass 0.97 0.03 0.05 1049
TreeCanopy 0.99 0.15 0.26 783
Water 1.00 0.12 0.21 644
accuracy 0.12 6780
macro avg 0.72 0.20 0.12 6780
weighted avg 0.80 0.12 0.10 6780
🧪 ResNet 二值图正类推断:label=1(mean_p0=0.861, mean_p1=0.965)
⚠️ 多类概率图通道数=1 < 目标类索引=1(Cropland)。退化为二类:使用单类概率图作为目标类概率,other=1-p,并以 ResNet 分类图作为回写类别。
🟩 E 补漏像元数: 2732771
🟥 E 剔除误判像元数: 28864
📦 已保存: C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\fused_E.tif
融合图 shape: (1828, 1942)
验证集样本数量: 6780
coords 范围: 行[99-1807],列[33-1804]
有效预测样本数: 6771
最终有效样本数(已知标签): 6771
🎯 E 方法的 F1 分数: 0.1364
📊 分类报告:
precision recall f1-score support
BareConstruction 1.00 0.10 0.19 1849
Cropland 0.07 1.00 0.14 452
DenseBuiltup 0.98 0.04 0.08 1142
LowDensityBuiltup 0.00 0.00 0.00 861
ShrubGrass 0.97 0.07 0.13 1049
TreeCanopy 0.98 0.25 0.40 774
Water 1.00 0.12 0.21 644
accuracy 0.15 6771
macro avg 0.71 0.23 0.16 6771
weighted avg 0.80 0.15 0.16 6771
🧪 ResNet 二值图正类推断:label=1(mean_p0=0.861, mean_p1=0.965)
📐 B 覆盖像元数: 3226715
📦 已保存: C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\fused_B.tif
融合图 shape: (1828, 1942)
验证集样本数量: 6780
coords 范围: 行[99-1807],列[33-1804]
有效预测样本数: 6780
最终有效样本数(已知标签): 6780
🎯 B 方法的 F1 分数: 0.1314
📊 分类报告:
precision recall f1-score support
BareConstruction 1.00 0.04 0.08 1849
Cropland 0.07 1.00 0.13 452
DenseBuiltup 1.00 0.04 0.08 1142
LowDensityBuiltup 0.00 0.00 0.00 861
ShrubGrass 0.97 0.03 0.05 1049
TreeCanopy 0.99 0.15 0.26 783
Water 1.00 0.12 0.21 644
accuracy 0.12 6780
macro avg 0.72 0.20 0.12 6780
weighted avg 0.80 0.12 0.10 6780
🧪 ResNet 二值图正类推断:label=1(mean_p0=0.861, mean_p1=0.965)
📐 C 修正像元数: 2891954
📦 已保存: C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\fused_C.tif
融合图 shape: (1828, 1942)
验证集样本数量: 6780
coords 范围: 行[99-1807],列[33-1804]
有效预测样本数: 6780
最终有效样本数(已知标签): 6780
🎯 C 方法的 F1 分数: 0.1314
📊 分类报告:
precision recall f1-score support
BareConstruction 1.00 0.04 0.08 1849
Cropland 0.07 1.00 0.13 452
DenseBuiltup 1.00 0.04 0.08 1142
LowDensityBuiltup 0.00 0.00 0.00 861
ShrubGrass 0.97 0.03 0.05 1049
TreeCanopy 0.99 0.15 0.26 783
Water 1.00 0.12 0.21 644
accuracy 0.12 6780
macro avg 0.72 0.20 0.12 6780
weighted avg 0.80 0.12 0.10 6780
📦 已保存: C:/Users/richi/TI_richiebao/WS_Landsat2LC_15m\report_best_A.json
🏆 最佳融合方案: A,F1=0.8287
机制 / 实现
- 五类策略:A(交集细化)、B(直接覆盖)、C(置信度阈值修正)、D(连通域增强)、E(全概率一致性补漏&纠错)。每法结束均可保存融合图;若启用“多方法自动优选”,将对目标类计算 F1,选择最高者作为最佳方案。
- 稳健 I/O:原子落盘(
.tmp + .lock)与 JSON 报告保存;日志线程安全。 - 评估:按
coords精确采样融合图像元,去除 255,无效样本与超界坐标显式处理;输出classification_report与(可选)混淆矩阵。
输入 / 输出与参数(面板字段一览)
| 分组 | 字段 | 类型 | 默认/示例 | 说明 |
|---|---|---|---|---|
| ② 融合方法与参数 | 目标类名 | 文本 | Shrubland | 需与 label_encoder 中的类名一致。 |
| 置信度阈值(C/D) | float | 0.60 | C/D 使用;ResNet 概率 ≥ 阈值才视为可信。 | |
| 单次运行方法 | 下拉 | A/B/C/D/E | 选择单法运行;或勾选“运行多个方法并优选”。 | |
| 运行多个方法并自动选择最佳 | 复选 | 开 | 顺序:A → D → E → B → C(推荐)。 | |
| A.a_mask_mode | 下拉 | refine/strict | A 子策略:refine 或 strict。 |
|
| D 参数 | 复合 | avg_conf≥0.70, min_pixels>10 | 连通域均值与最小像元阈值。 | |
| E 参数 | 复合 | add≥0.80, remove<0.60, margin>0.20 | 全概率一致性策略的三阈值。 |
③ 执行
目的
启动融合任务(可单法或多法连跑),自动保存 TIFF 与评估报告,并返回最佳方法与 F1。
机制 / 实现(执行全过程)
- 对齐 → 融合 → 保存 → 评估 → 优选;失败的某法会被跳过且不影响后续方法。
- 输出采用主图 profile,
uint8、nodata=255、内置颜色表,并用文件锁+原子替换避免半写。 - UI 由
QThreadPool驱动后台任务,结束后写回“最佳方法/报告路径”等记录。
④ 状态信息
- 实时打印:对齐后的 shape、CRS/像素大小、每法补漏/剔除/交集像元数、F1 分数、分类报告摘录、输出路径与最佳方案。
- “🧹 清空”可一键清屏;结束会输出“🎯 已结束”。
公式与解释
下面在你已给出的公式基础上,逐法把符号、逻辑与“为什么有效”讲清楚,同时给出阈值的单调性、精确率/召回率影响、边界与空值处理等工程细节,便于论文复述与实现核对。所有数学写法均为 KaTeX 友好格式。
符号与公共约定(再次明确)
- 目标类索引 $t$ 来自标签编码器(类名→整数);
- 主图(通常 RF)$M\in{0,\dots,K}\cup{255}$,ResNet 分类 $R\in{0,\dots,K}\cup{255}$;
255表示 NoData; - ResNet 目标类概率 $p_{t}\in[0,1]$,多类概率 $\mathbf p=(p_0,\dots,p_K)$,$\sum_c p_c=1$(若给到的是每类独立概率,先做归一化);
- 任何一步不改变 NoData:若 $M_{ij}=255$ 则 $F_{ij}=255$;若 ResNet 图像素越界/NaN,对应逻辑判定为“条件不满足”;
- 连接性默认 8-邻域(如不特别声明);面积 $|\Omega|$ 以像元计;
- 写出时类别范围始终限定在 ${0,\dots,K}\cup{255}$。
A 交集细化(主 × ResNet)
交集
$$ \mathcal I={(i,j)\mid M_{ij}=t \ \land\ R_{ij}=t} $$
是两模型对目标类一致的像元集合。
strict(强保守):分歧处标记为无效
$$ F_{ij}=\begin{cases} t,&(i,j)\in\mathcal I,\ 255,&M_{ij}=t,\ R_{ij}\ne t,\ M_{ij},&\text{otherwise}. \end{cases} $$
refine(温和保守):分歧处采纳 ResNet 的判断
$$ F_{ij}=\begin{cases} R_{ij},&M_{ij}=t,\ R_{ij}\ne t,\ t,&(i,j)\in\mathcal I,\ M_{ij},&\text{otherwise}. \end{cases} $$
为什么有效
- A 利用“两模一致性”锁定高置信硬核:strict 最大化精确率(Precision),refine 在精确率与召回率(Recall)之间取平衡;
- 典型流程:先 A 固化核心,再用 C/D/E 补漏与纠错。
性质与工程细节
- A 不用概率,不依赖校准;
- A 是幂等的:重复执行不再改变结果;
- strict 会产生“洞”,建议配合 D/E 再修复。
B 直接覆盖(以 ResNet 为准)
$$ F_{ij}=\begin{cases} t,&R_{ij}=t,\ M_{ij},&\text{otherwise}. \end{cases} $$
为什么有效
- 当 ResNet 的目标类召回率更高(或边界更锐利)时,B 能快速提升 Recall;
- 适合 ResNet 目标类的混淆少、概率稳定的场景。
性质
- B 单调于“ResNet 判为 $t$”的像元集合,不使用概率;
- 若 ResNet 分类有噪声,B 也会把噪声直接写入,故常放到 A/D/E 之后作为补充。
C 置信度阈值修正(像元级)
给定 $\tau\in(0,1]$,当主图非目标类而 ResNet 判为目标类且 $p_{t}\ge\tau$ 时改写:
$$ F_{ij}=\begin{cases} t,&M_{ij}\ne t,\ R_{ij}=t,\ p_{t,ij}\ge\tau,\ M_{ij},&\text{otherwise}. \end{cases} $$
为什么有效
-
用概率门控“ResNet 的新增”,$\tau$ 越高越保守:
- 单调性:定义被改写集合 $\mathcal S(\tau)={(i,j)\mid M_{ij}\ne t,R_{ij}=t,p_{t,ij}\ge\tau}$,则 $\tau_1<\tau_2\Rightarrow \mathcal S(\tau_2)\subseteq\mathcal S(\tau_1)$。
- $\tau$ 升高:Precision ↑,Recall ↓;$\tau$ 降低:Precision ↓,Recall ↑。
-
对概率不稳的区域可能引入噪声,需与 D/E 联动。
工程细节
- 缺失/NaN 概率视为条件不满足;
- 若 ResNet 分类为 $t$ 但 $p_t$ 低于阈值,不改写(与 B 不同)。
D 连通域增强(区域级)
构造二值掩膜 $\mathbb B={(i,j)\mid R_{ij}=t,\ p_{t,ij}\ge\tau}$,分解为连通域 ${\Omega_m}$,对每一块计算均值置信度:
$$ \bar p(\Omega_m)=\frac{1}{|\Omega_m|}\sum_{(i,j)\in\Omega_m}p_{t,ij}. $$
若 $\bar p(\Omega_m)\ge \alpha$ 且 $|\Omega_m|> n_{\min}$ 则整块改写为 $t$:
$$ F_{ij}=\begin{cases} t,&(i,j)\in\Omega_m\ \text{且}\ \bar p(\Omega_m)\ge\alpha,\ |\Omega_m|>n_{\min},\ M_{ij},&\text{otherwise}. \end{cases} $$
为什么有效
- 现实地物以片状出现;把像元级噪声用区域统计平滑能显著抑制椒盐误差;
- $\alpha$ 与 $n_{\min}$ 控制“可信度”与“规模”,典型设置 $\alpha\approx0.7,\ n_{\min}\approx 10$。
性质
- 对二值掩膜 $\mathbb B$ 单调:$\tau$ 升高 → $\mathbb B$ 收缩 → 改写更保守;
- 对区域参数单调:$\alpha\uparrow$ 或 $n_{\min}\uparrow$ → 更保守(Precision ↑,Recall ↓)。
实现要点
- 连接性 8 邻域,边界贴边的区域照常计入;
- 该法与 A 兼容:先 A 再 D 更稳(先锁核心,后成片扩张)。
E 全概率一致性(补漏 & 纠错)
当有全类概率 $\mathbf p$ 时,E 同时做两件事:
(1) 高置信补漏
若 $M_{ij}\ne t$ 且 $p_{t,ij}\ge a$(add_thresh),则置为 $t$。
— 等价于 C 的“概率新增”但不要求 ResNet 分类为 $t$,因此能捕捉“分类头没给到 $t$ 但 $p_t$ 很高”的像元(常见于 argmax 被近邻类以极小优势胜出)。
(2) 明显冲突纠错
若 $M_{ij}=t$,但 $p_{t,ij}< r$(remove_thresh),且
$$ \max_{c\ne t}p_{c,ij} > p_{t,ij}+m $$
(margin),则改写为 $\arg\max_c p_{c,ij}$。
合并写法
$$ F_{ij}=\begin{cases} t,&M_{ij}\ne t,\ p_{t,ij}\ge a,\ \arg\max_c p_{c,ij},&M_{ij}=t,\ p_{t,ij}< r,\ \max_{c\ne t}p_{c,ij} > p_{t,ij}+m,\ M_{ij},&\text{otherwise}. \end{cases} $$
为什么有效
- 补漏用高阈值 $a$ 保障 Precision;
- 纠错同时要求“目标类置信度低”且“某非目标类显著高于目标类”(以 $m$ 作间隔),避免在概率差距很小的模糊区随意翻转。
- 若只有二类概率,令 $\tilde p_{\text{other}}=1-p_t$ 即可退化实现(保持同一逻辑)。
阈值与单调性
- $a\uparrow$ → 补漏更少(Recall ↓,Precision ↑);
- $r\downarrow$ 或 $m\uparrow$ → 纠错更少(更稳);
- 三阈值可作网格搜索,以目标类 F1或成本权重的 F$_\beta$ 为目标优选。
工程注意
- E 对概率校准较敏感(最好有温度缩放/验证集对比);
- 若概率有系统偏差(如某类整体偏低),先用 A/D 再谨慎打开 E。
与精确率/召回率的关系(总览)
- 提升 Precision(更保守):A-strict、A-refine(小幅)、C 的高 $\tau$、D 的高 $\alpha$/大 $n_{\min}$、E 的高 $a$/高 $m$/低 $r$;
- 提升 Recall(更激进):B、C 的低 $\tau$、D 的低 $\alpha$/小 $n_{\min}$、E 的低 $a$/低 $m$/高 $r$。
复杂度与稳定性
- A/B/C:单遍逐像元,时间 $O(HW)$;
- D:先连通域标记 $O(HW)$,再按区域聚合;
- E:逐像元但用多类概率,代价与通道数 $C$ 成正比;
- 全流程采用主图的 profile 写盘,NoData 与颜色表沿袭一致;所有方法对空值/越界都不改写。
实操建议(从参数到流程)
- 推荐顺序:A → D → E →(必要时)B/C;
- 起步值:$\tau\approx0.6\sim0.7$,$\alpha\approx0.7$,$n_{\min}\approx10$,$a\approx0.8$,$r\approx0.6$,$m\approx0.2$;
- 优选指标:以目标类 F1或F$_\beta$($\beta>1$ 偏向 Recall)在验证样本上网格搜索;
- 幂等性:A/B/C/E 在同一输入上重复执行结果不再变化(D 因区域统计,在参数不变时也幂等);
- 复现实验:记录最终生效的参数与最佳方法名字(A/B/C/D/E),连同评估 JSON 一同归档。
评估与优选(目标类 F1)
- 依据样本
coords采样融合结果 $F$,过滤255,与y对齐后计算classification_report,以目标类名对应条目的 F1 作为指标;多法运行时选择 F1 最大者(同时保存报告 JSON)。
使用建议(参数优选与场景建议)
-
优先顺序:建议 A → D → E → B → C。A 稳定起步,D 成片增强,E 全概率精修,B/C 为补充。
-
常用阈值:
- C/D 的置信度阈值 $\tau$:0.6–0.7;
- D 的区域均值/规模:$\alpha\approx0.7,\ n_{\min}\approx 10$;
- E 的三阈值:
add≈0.8、remove≈0.6、margin≈0.2(地类混杂时可适当升高margin)。
-
概率图质量:E 的效果依赖概率校准与多类概率的可靠性;若概率不稳,先用 A/D,再慎用 E。
-
空间对齐:分类最近邻、概率双线性已在后台处理;如仍见错位,多半是参考影像与输入影像的 CRS/分辨率不一致,请核对元数据日志。
-
NoData 管理:分类
255、概率NaN;评估阶段会自动剔除无效像元,避免分数偏移。
日志与排错
- 路径检查:若必要文件缺失(主图、分类图、概率图、编码器、样本),UI 会即时报错并终止。
- CRS/分辨率提示:加载时会打印主图/ResNet 图的 CRS 与分辨率,便于核查是否需要重投影。
- 方法失败的容错:单法异常会被捕获并跳过,不影响后续方法与最终优选;最佳报告采用原子保存。
- 评估空判:当有效样本为 0 时打印提示并跳过该方法的评估与报告。